



![Copyright © 2015, Intel Corporation. All rights reserved.
Hadoop to Big Data
5
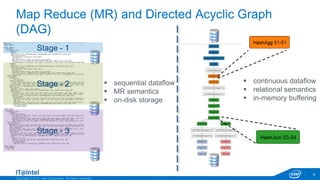
Processing Model
Analytical Model
Storage Model
Language Model
Complex EventBatch In-Memory
Machine
Learning
Textual SpatialAggregate Temporal Graph
Unstructured Relational Columnar Hierarchic Graph
MR SQL NOSQL JSQL NOSPARQL
retrofitting Hadoop [unstructured batch analytics] to cater to the full big data demand](https://image.slidesharecdn.com/june9325pmintelghoshedalav2-150616223332-lva1-app6892/85/N-ot-o-nly-Ha-doop-the-DAG-showdown-5-320.jpg)









![Copyright © 2015, Intel Corporation. All rights reserved.
Benchmark Environment
Cloudera Enterprise 5.3.2
4 Node Cluster [1 master + 3 workers]
Memory 62.9 GiB in each node
Cores 16
TPCDS Database with Scale of 250
Queries used
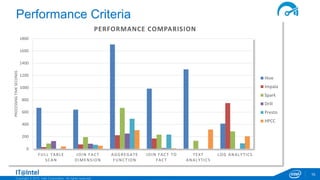
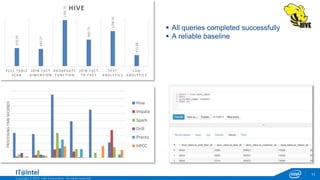
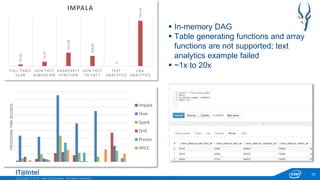
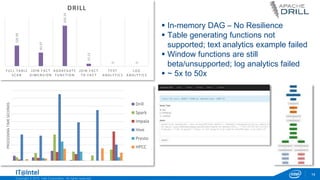
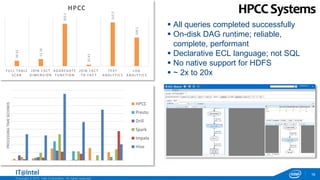
Full Table Scan
Fact and Dimension Join
Aggregate functions
Fact to Fact Join
Text Analytics
Log Analytics
22
Hadoop 2.5.0-cdh5.3.0
Hive 0.13.1-cdh5.3.0
presto-server-0.103
Apache Drill: 0.9.0
impalad version 2.1.0-cdh5
Spark 1.3.1
HPCC – 5.0.14.1
TPCDS Scale of 250 – 19.3 GB
Store Sales -18.8 GB
Customer - 300.3 MB
Text Analytics (twitter) – 436.6 MB
CIKM twitter dataset
Log Analytics (weblog) - 5.0 GB
HPCC ECL WLAM sample
Versions
Data Volume](https://image.slidesharecdn.com/june9325pmintelghoshedalav2-150616223332-lva1-app6892/85/N-ot-o-nly-Ha-doop-the-DAG-showdown-22-320.jpg)
![Copyright © 2015, Intel Corporation. All rights reserved.
Completeness Scores
23
To-disk failover 2 3 0 3 0 3 4
HDFS Compatibility 4 4 4 4 4 4 2
Yarn Integration 4 0 0 3 1 4 0
File formats 4 4 4 3 2 4 1
Expressive language 3 3 3 4 3 3 3
Streaming support 0 0 0 4 0 4 0
Connectivity 4 4 4 4 4 2 3
Web UI 2 3 4 4 4 3 3
Integrated Monitoring 2 3 4 4 4 3 4
Security 3 3 1 1 1 1 1
Hybrid Analytics 3 2 1 4 1 3 4
Seamless Dataframes 1 1 1 4 1 4 2
32 30 26 42 25 38 25
*Score: 0 Min [0] - 4 Max [4]Note: Other names and brands may be claimed as the property of others.](https://image.slidesharecdn.com/june9325pmintelghoshedalav2-150616223332-lva1-app6892/85/N-ot-o-nly-Ha-doop-the-DAG-showdown-23-320.jpg)


The document compares different big data analytics frameworks that use the directed acyclic graph (DAG) model versus the traditional MapReduce (MR) model. It finds that while DAG frameworks are improving and Spark comes closest to meeting diverse big data use cases that go beyond batch analytics, DAG runtimes are still maturing and have limitations compared to MR in areas like completeness, performance, and reliability. The document concludes that while Hadoop may no longer be the only option, frameworks still need improvements for "no-MR" to fully replace MR for big data processing.






















































































