Download as PDF, PPTX



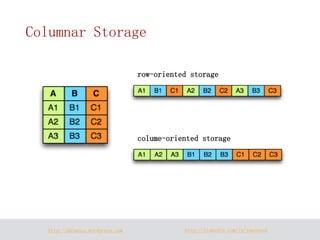



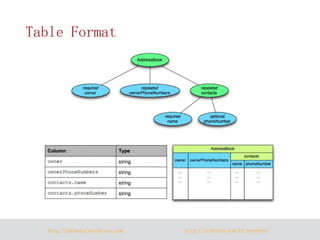








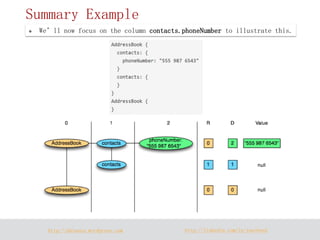






The document discusses Parquet, a column-oriented data storage format for Hadoop. Parquet aims to provide efficient column-based storage across Hadoop platforms by limiting I/O to only the needed columns and supporting nested data structures. It uses definition and repetition levels to reconstruct nested data representations from columns and allows for different compression codecs like Snappy and GZIP.
































































































