Download as PDF, PPTX








![17
17
R. Pourezza, T. Cohen, Extending Neural P-frame Codecs for B-frame Coding, Under review at ICCV 2021
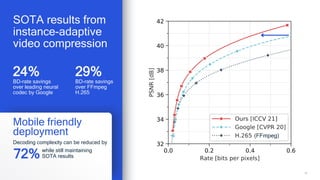
Our B-frame coding provides state-of-the-art results
Improved rate-distortion tradeoff by extending neural p-frame codecs for B-frame coding
32
33
34
35
36
37
38
39
40
41
0 0.1 0.2 0.3 0.4 0.5 0.6
PSNR
(dB)
Rate (bits per pixel)
PSNR
0.92
0.93
0.94
0.95
0.96
0.97
0.98
0.99
1
0 0.1 0.2 0.3 0.4 0.5 0.6
MS-SSIM
Rate (bits per pixel)
MS-SSIM
Ours Google [CVPR-20] H.265 (FFmpeg)](https://image.slidesharecdn.com/presentation-howairesearchisenablingnext-gencodecs-210714202630/85/How-AI-research-is-enabling-next-gen-codecs-16-320.jpg)


![23
Y. Lu, Y. Zhu, Y. Yang, A. Said, T. Cohen, Progressive Neural Image Compression with Nested Quantization and Latent Ordering, Accepted at ICIP 2021
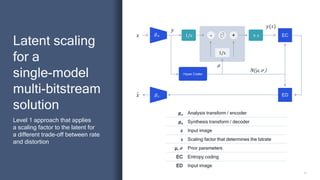
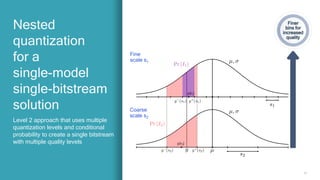
Variable-bitrate
progressive
neural image
compression
Achieves comparable
performance to HEVC
Intra but uses only a
single model and a
single bitstream
HEVC Intra
Separate bitstreams,
one for each quality
[N-model, N-bitstream] Level 0
[1-model, 1-bitstream] Level 2 - Ours
[1-model, N-bitstream] Level 1 - HEVC Intra
[1-model, 1-bitstream] Level 2
Our scheme
A single bitstream
where the prefixes
decode to different
qualities](https://image.slidesharecdn.com/presentation-howairesearchisenablingnext-gencodecs-210714202630/85/How-AI-research-is-enabling-next-gen-codecs-22-320.jpg)
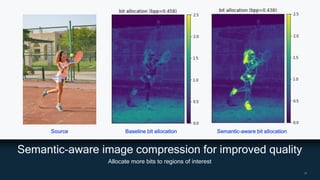
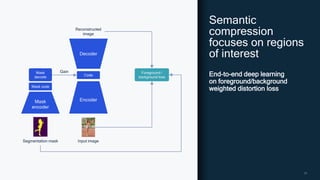
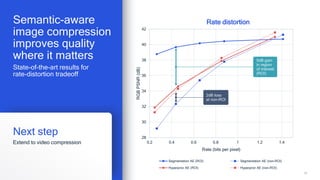

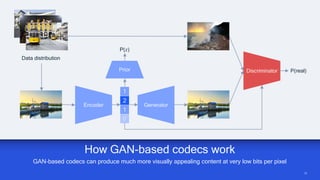

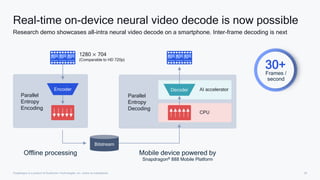
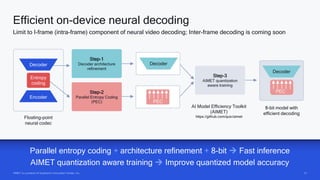






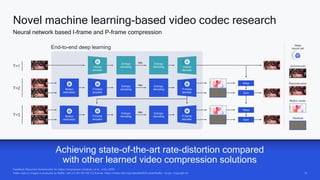
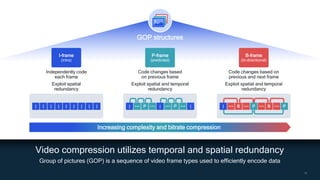
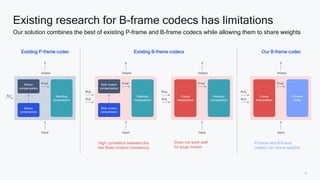
AI research is enabling more efficient video and voice codecs through techniques like generative models and deep learning. Qualcomm's latest research includes a neural video codec that achieves state-of-the-art compression rates compared to other learned video compression solutions. Their work on B-frame coding also provides improved rate-distortion results by extending neural P-frame codecs to allow for B-frame coding and interpolation. Future research aims to develop more efficient on-device deployment methods and semantically aware compression focused on regions of interest.












































![[IJET-V1I2P1] Authors :Imran Ullah Khan ,Mohd. Javed Khan ,S.Hasan Saeed ,Nup...](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v1i2p1-150413013648-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)









































