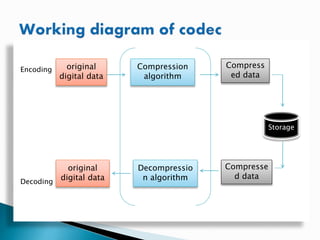
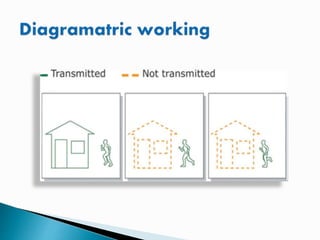
Video compression reduces and removes redundant video data so digital video files can be efficiently transmitted and stored. Uncompressed video takes up huge amounts of data, for example over 1 GB/s for high definition TV. Compression uses algorithms to encode video into a smaller compressed file, then decode it back into a similar quality video. Popular standards like MPEG-4 and H.264 use techniques like comparing frames and only coding changed pixels to greatly reduce file sizes while maintaining quality. Frames can be intra-frames that standalone or inter-frames that reference other frames, allowing different levels of compression.