Download to read offline



![SotA in NN Compression
Lottery ticket hypothesis [Frankle and Carbin, ICLR 2018]
for a dense randomly initialized feed forward NN there are subnetworks that
achieve the same performance at similar training cost
such a subnetwork can be obtained by pruning, without further training
retrain from early training iteration
Inference complexity gain
straight forward for pruning layers, channels, etc.
sparse tensors need specific support (e.g. recently added to CUDA)
usually certain sparseness ratio needs to be met to get gain
8](https://image.slidesharecdn.com/20210625standardisingcompressednns-210625115828/75/Standardising-the-compressed-representation-of-neural-networks-7-2048.jpg)
![SotA in NN Compression - Quantisation
possible to go <10bit parameters for many common NNs without performance loss
many works show losses can be regained with fine-tuning (or already training with quantized
network)
mixed precision (e.g., per layer) is beneficial for many networks
going to very low precision (1bit) is feasible (needs approaches to ensure backprop still works, e.g.,
asymptotic-quantized estimator [Chen et al., IEEE JSTSP 2020])
Inference complexity gain
needs support on target platform, and in DL framework (+ any custom operators)
increasingly supported on GPUs and specific NN processors (at least 4, 8, 16)
9](https://image.slidesharecdn.com/20210625standardisingcompressednns-210625115828/75/Standardising-the-compressed-representation-of-neural-networks-8-2048.jpg)
![Relation to Network Architecture Search (NAS)
finding an alternative architecture
and train
architecture search is
computationally expensive
training is then done using e.g. knowledge distillation,
teacher-student learning
Faster NAS methods have been proposed, e.g. Single-Path Mobile AutoML
[Stamoulis et al., IEEE JSTSP 2020]
needs also access to full training data, while fine-tuning could be done on partial
data or application specific data
10
[Strubell, et al. ACL 2019]](https://image.slidesharecdn.com/20210625standardisingcompressednns-210625115828/75/Standardising-the-compressed-representation-of-neural-networks-9-2048.jpg)
![Relation to target hardware
Optimising for target hardware
supported operations (e.g., sparse matrix multiplication, weight precisions)
relative costs of memory access and computing operations
training a network, derive network for particular platform
first approaches [Cai, ICLR 2020]
no reliable prediction of inference
costs on particular target architecture
in particular, prediction of speed and
energy consumption
cf. autotune in inference of
DL frameworks
11](https://image.slidesharecdn.com/20210625standardisingcompressednns-210625115828/75/Standardising-the-compressed-representation-of-neural-networks-10-2048.jpg)
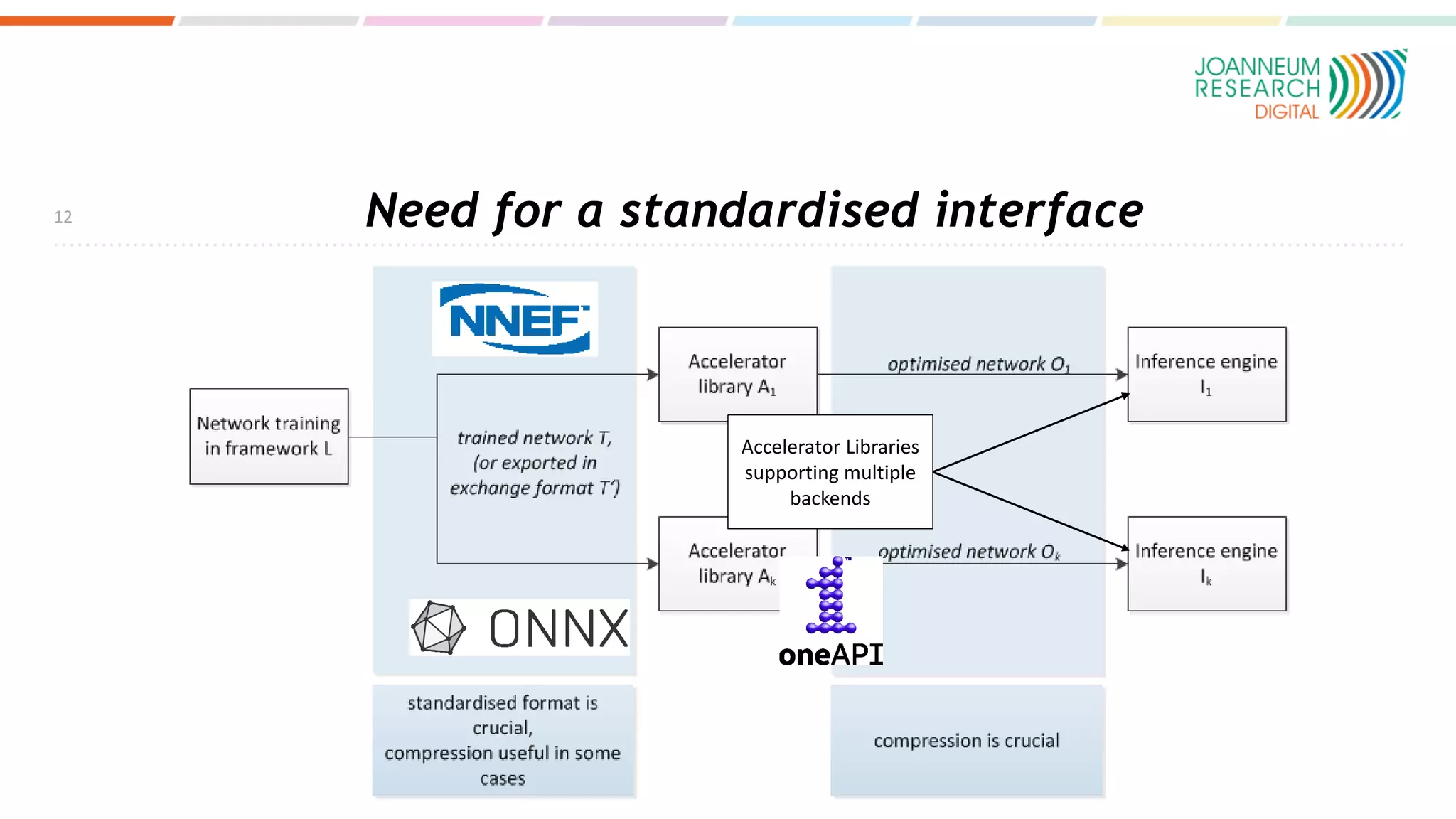



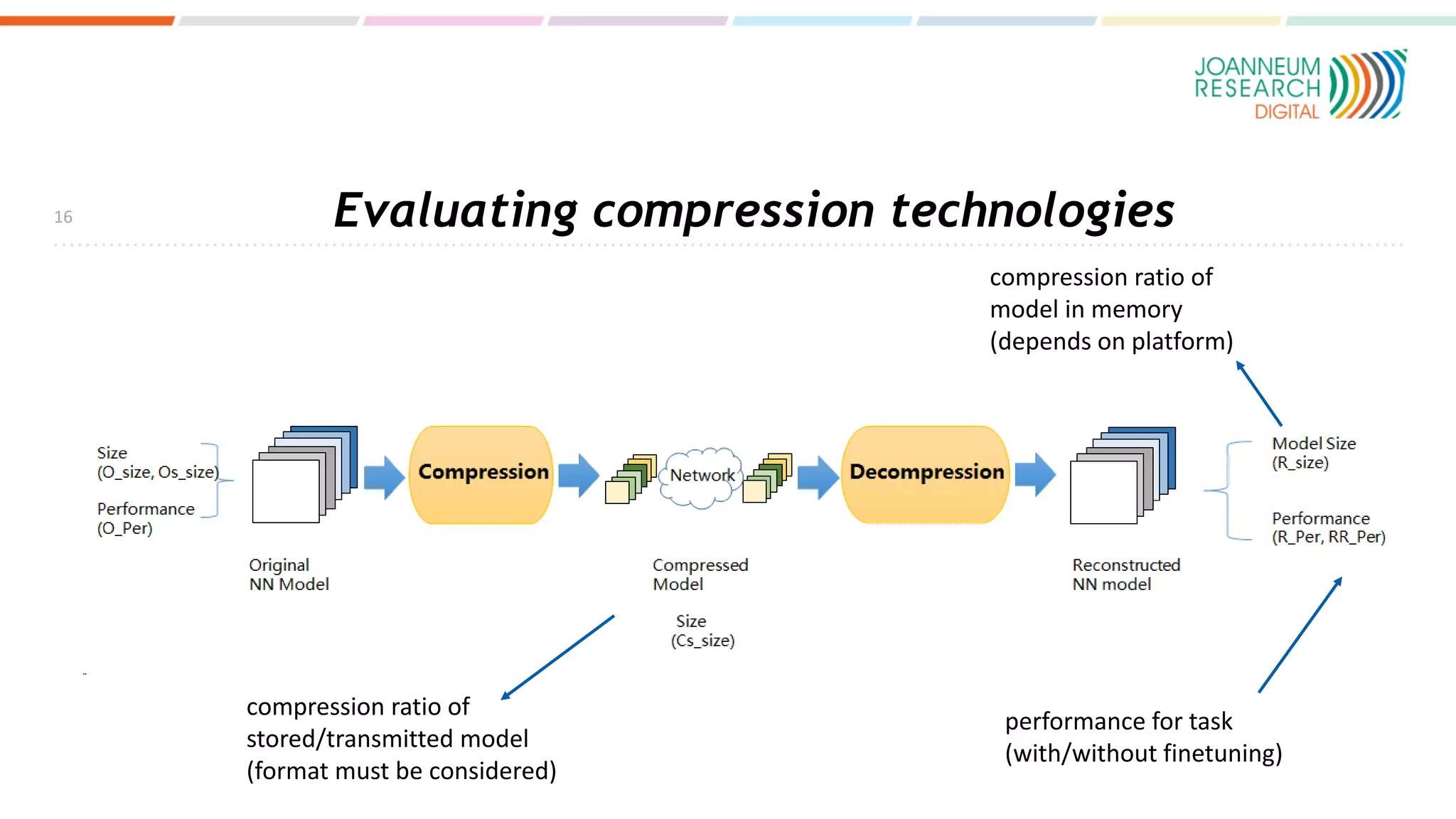
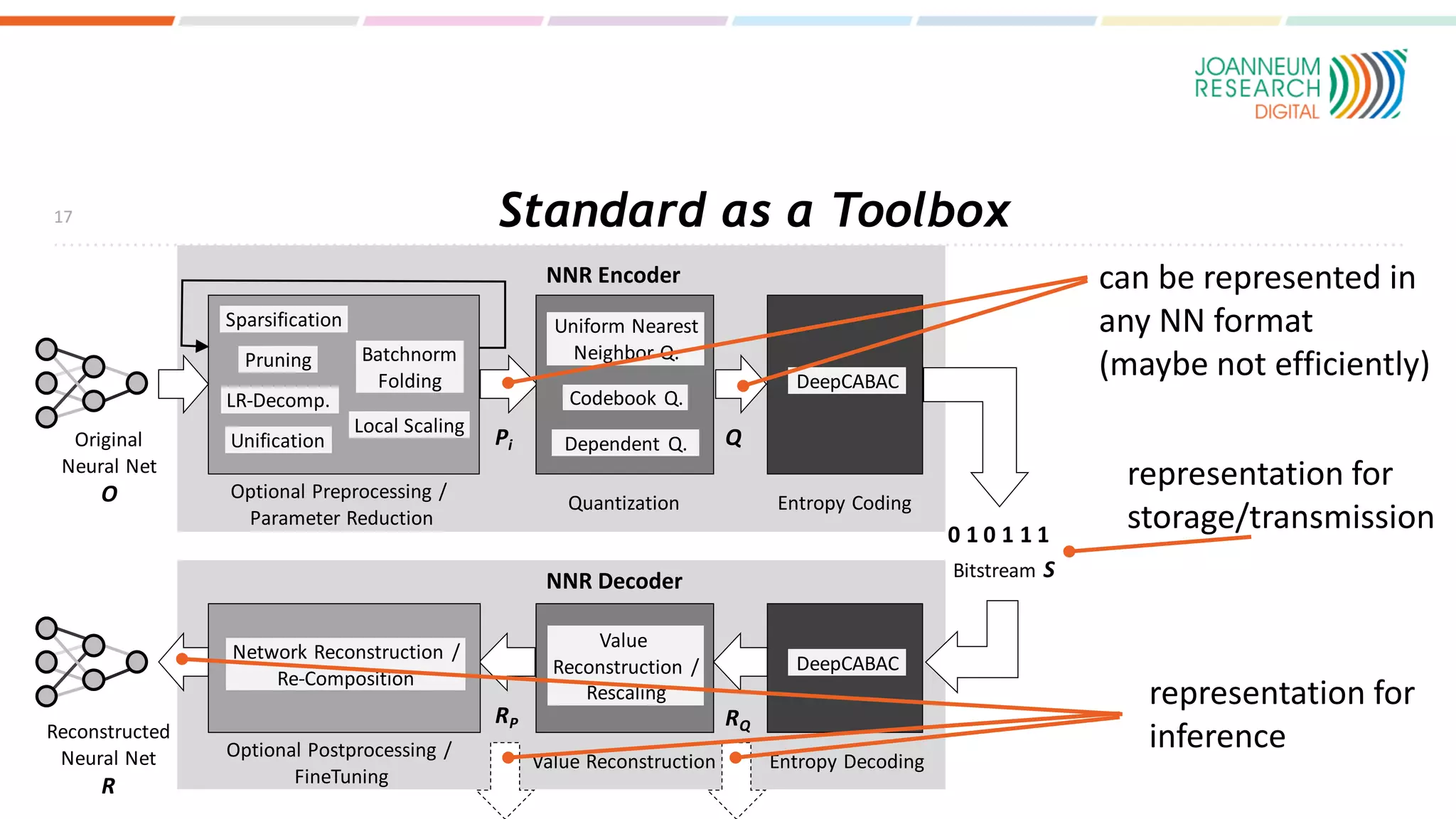









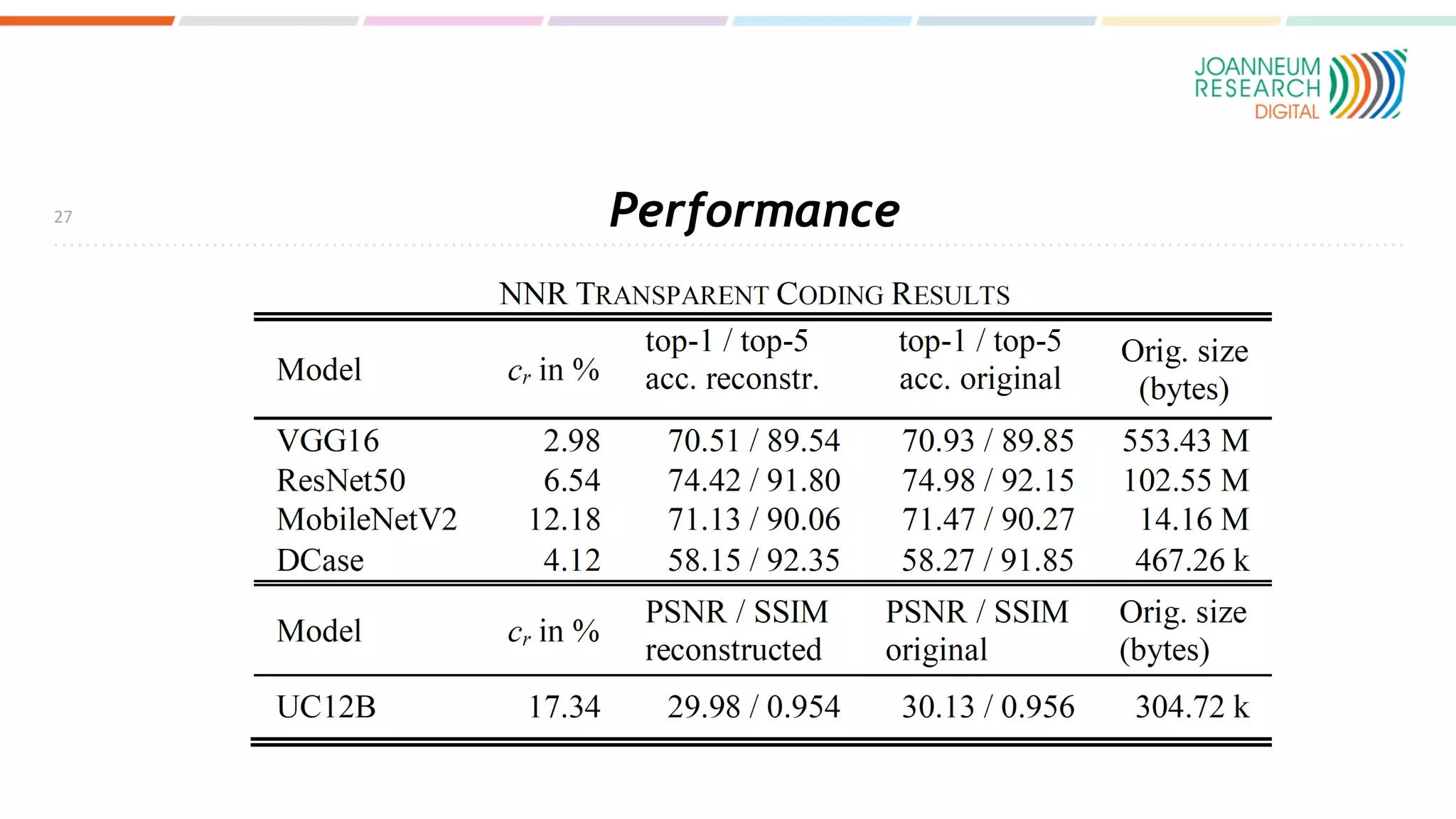
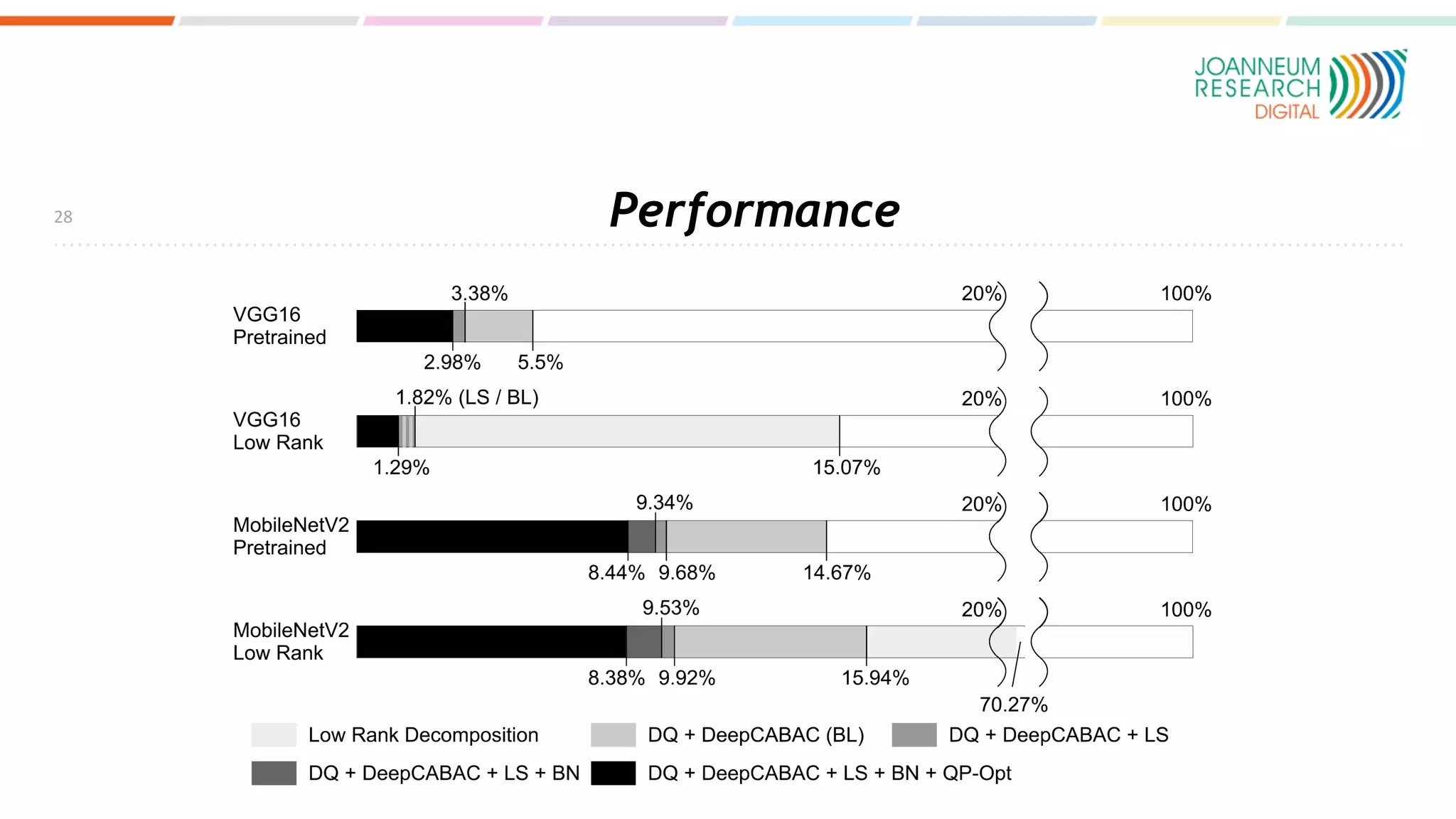
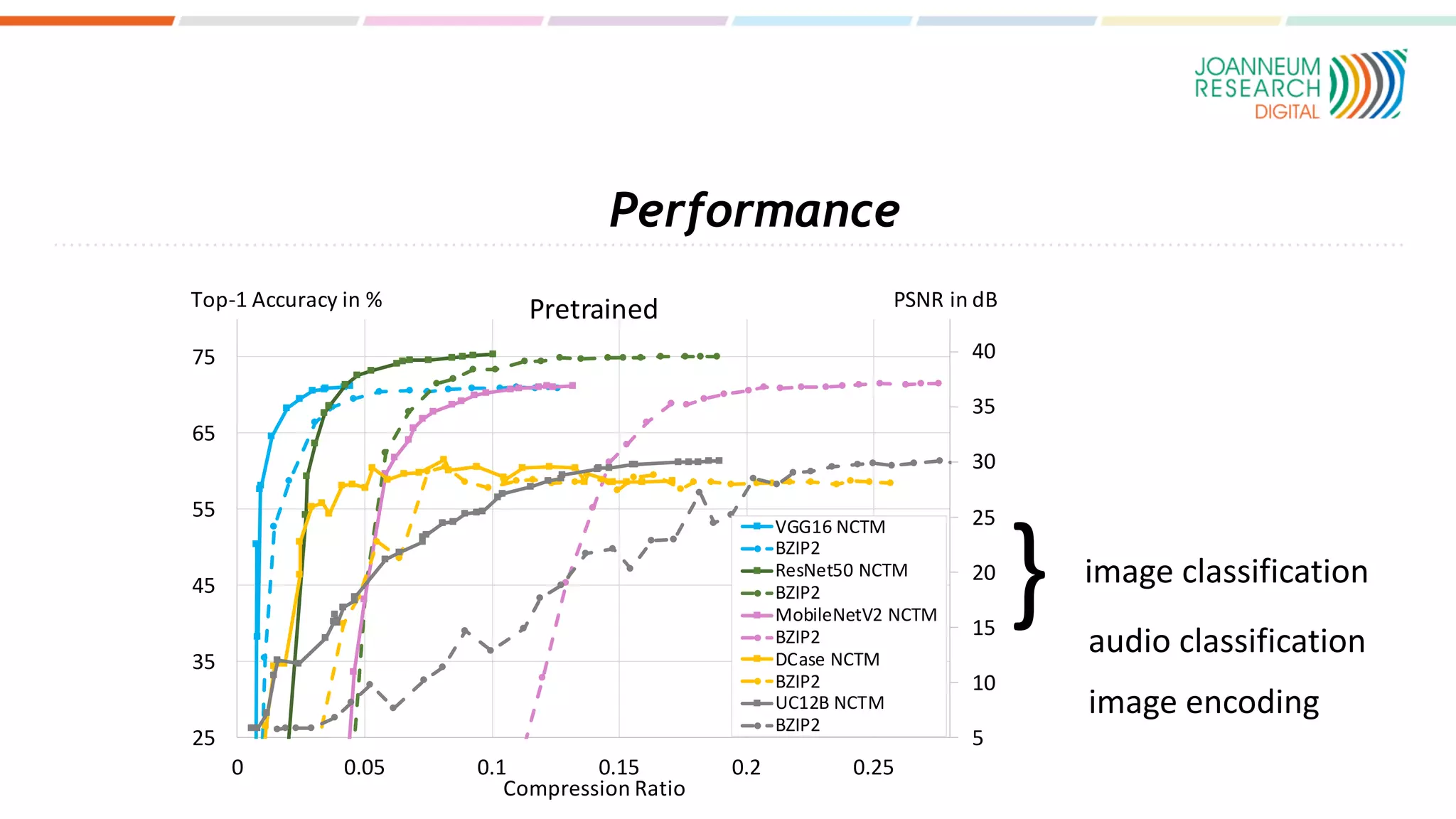
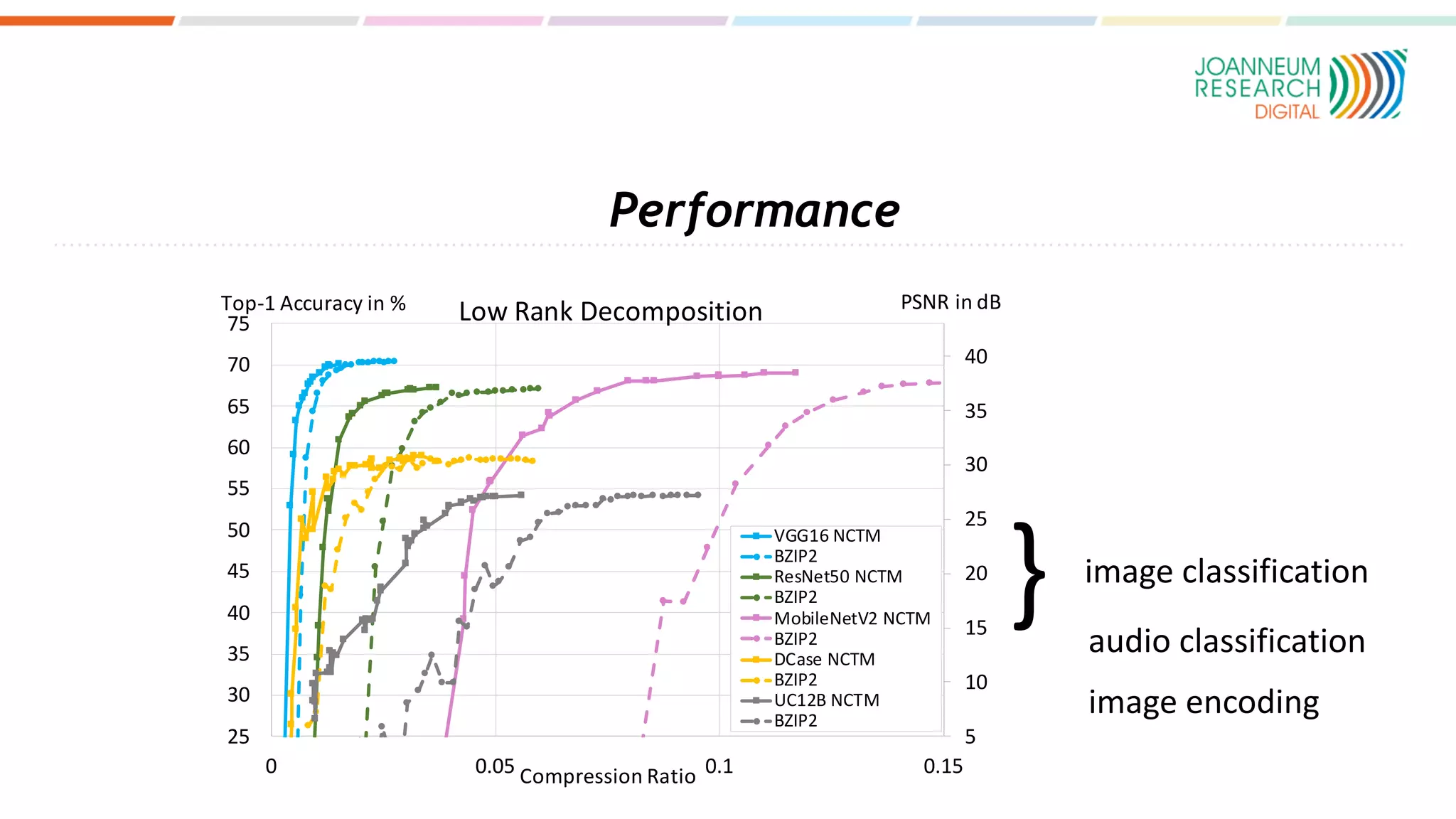
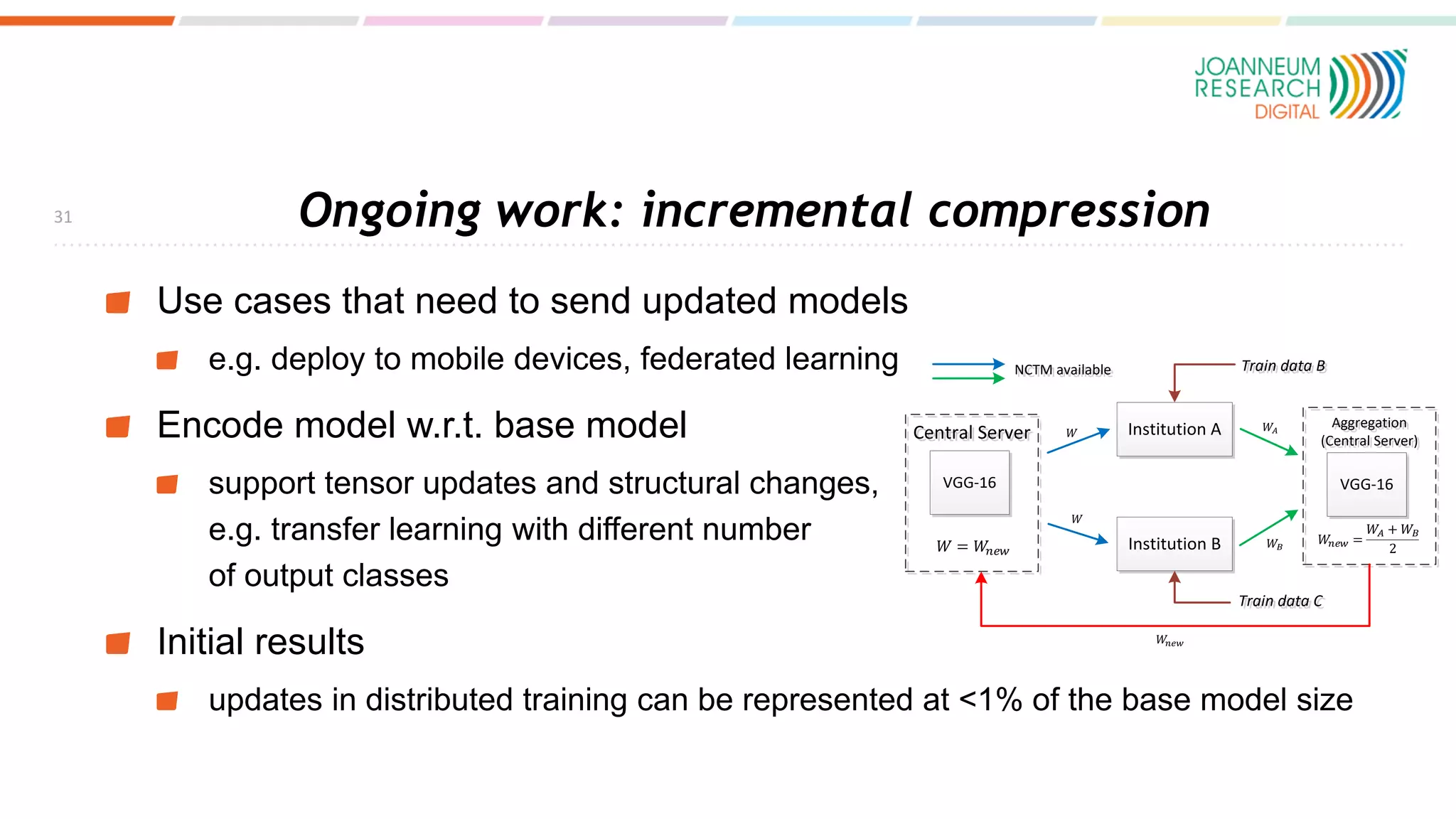



The document discusses the standardization of compressed representations of neural networks, outlining the need for interoperability in neural network compression to optimize performance on resource-constrained devices. It covers state-of-the-art methods such as pruning, quantization, and encoding techniques while emphasizing the importance of evaluating compression ratios and performance in specific applications. Ongoing work aims to develop a standard that allows for compressing neural network parameters to less than 10% of their original size without performance loss.


![[DLHacks LT] PytorchのDataLoader -torchtextのソースコードを読んでみた-](https://cdn.slidesharecdn.com/ss_thumbnails/torchtextupload-170918235754-thumbnail.jpg?width=640&height=640&fit=bounds)




















































































