Download as PDF, PPTX




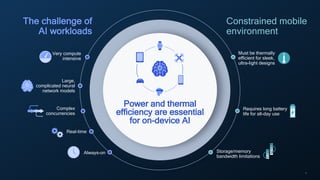

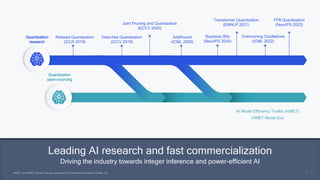
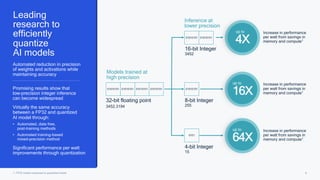
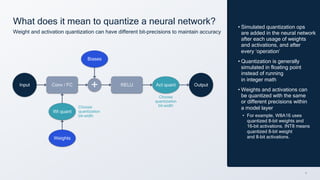



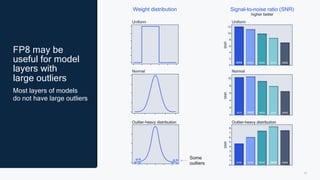

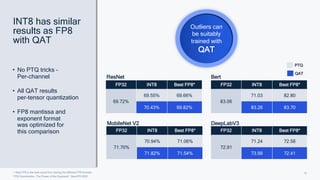
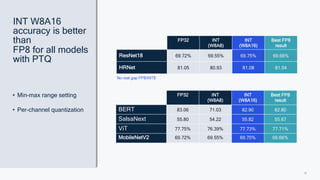
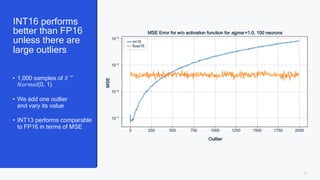

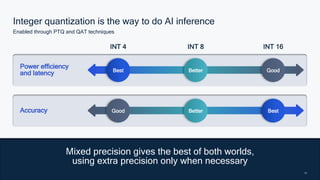

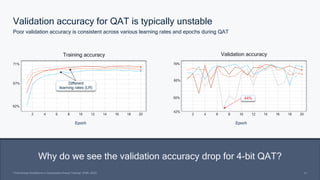
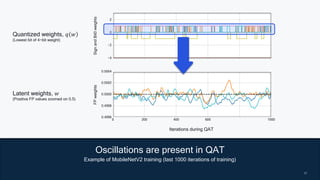

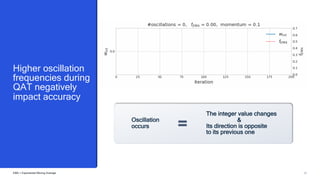
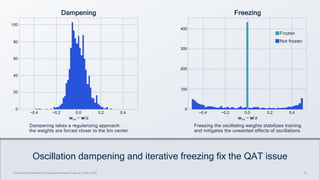


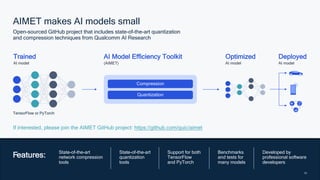

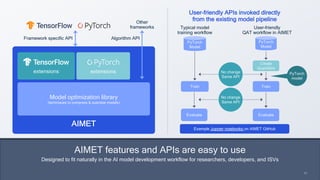

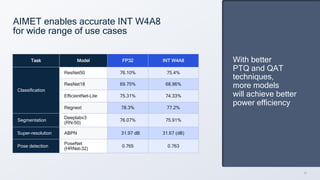





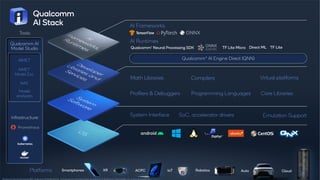




This document summarizes a presentation given by Chirag Patel and Tijmen Blankevoort of Qualcomm AI Research on model efficiency techniques for edge AI. They discuss why model efficiency is important for on-device AI due to constraints like power and thermal limits. They overview techniques like quantization, conditional compute, neural architecture search, and compilation that can shrink AI models and efficiently run them on hardware. Specifically, they find that integer quantization through techniques like post-training and quantization-aware training can achieve similar accuracy as floating point models but provide much better performance per watt. Overall, the presentation advocates that integer quantization is the best approach for efficient AI inference on edge devices.















































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)







