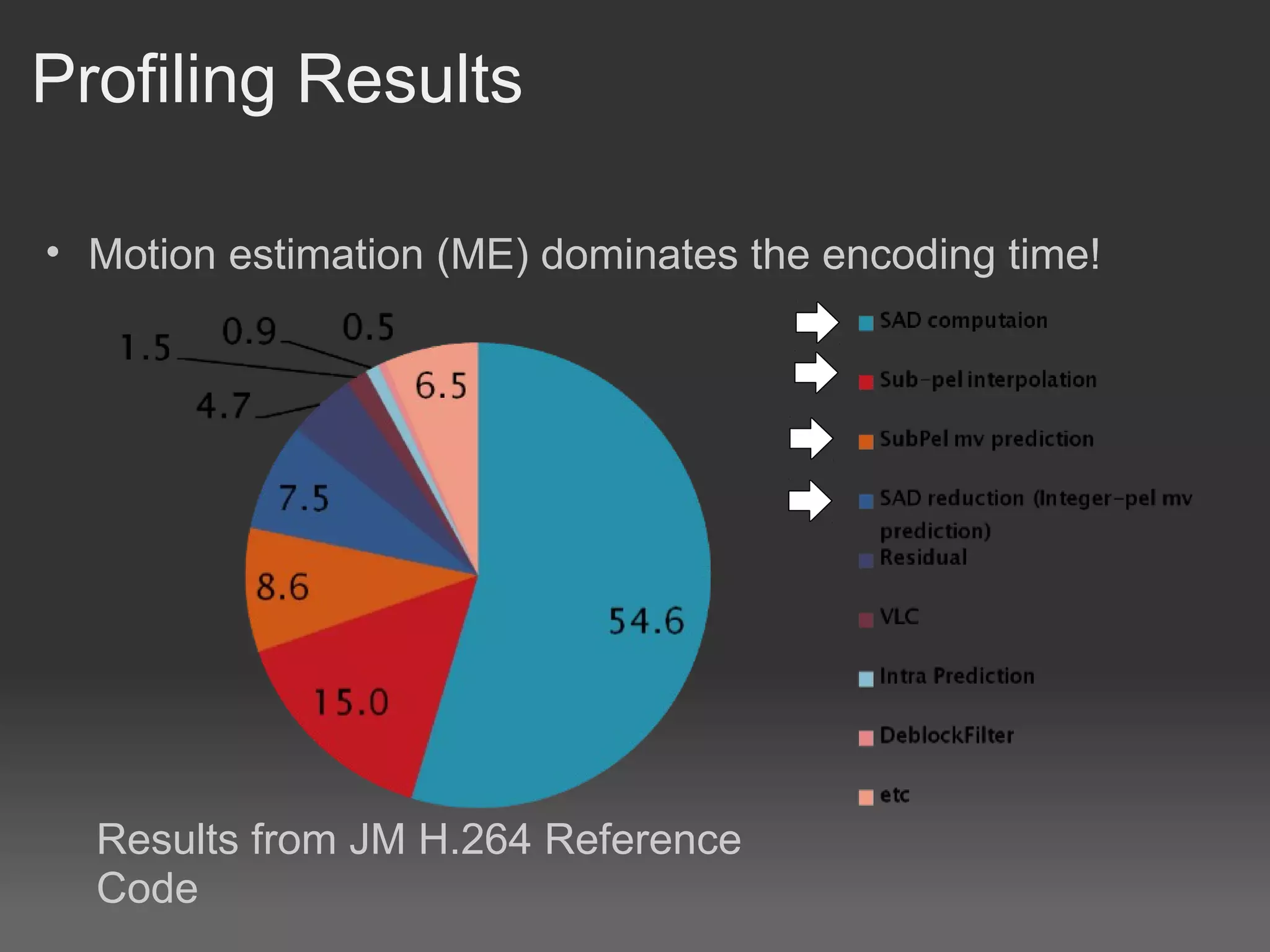
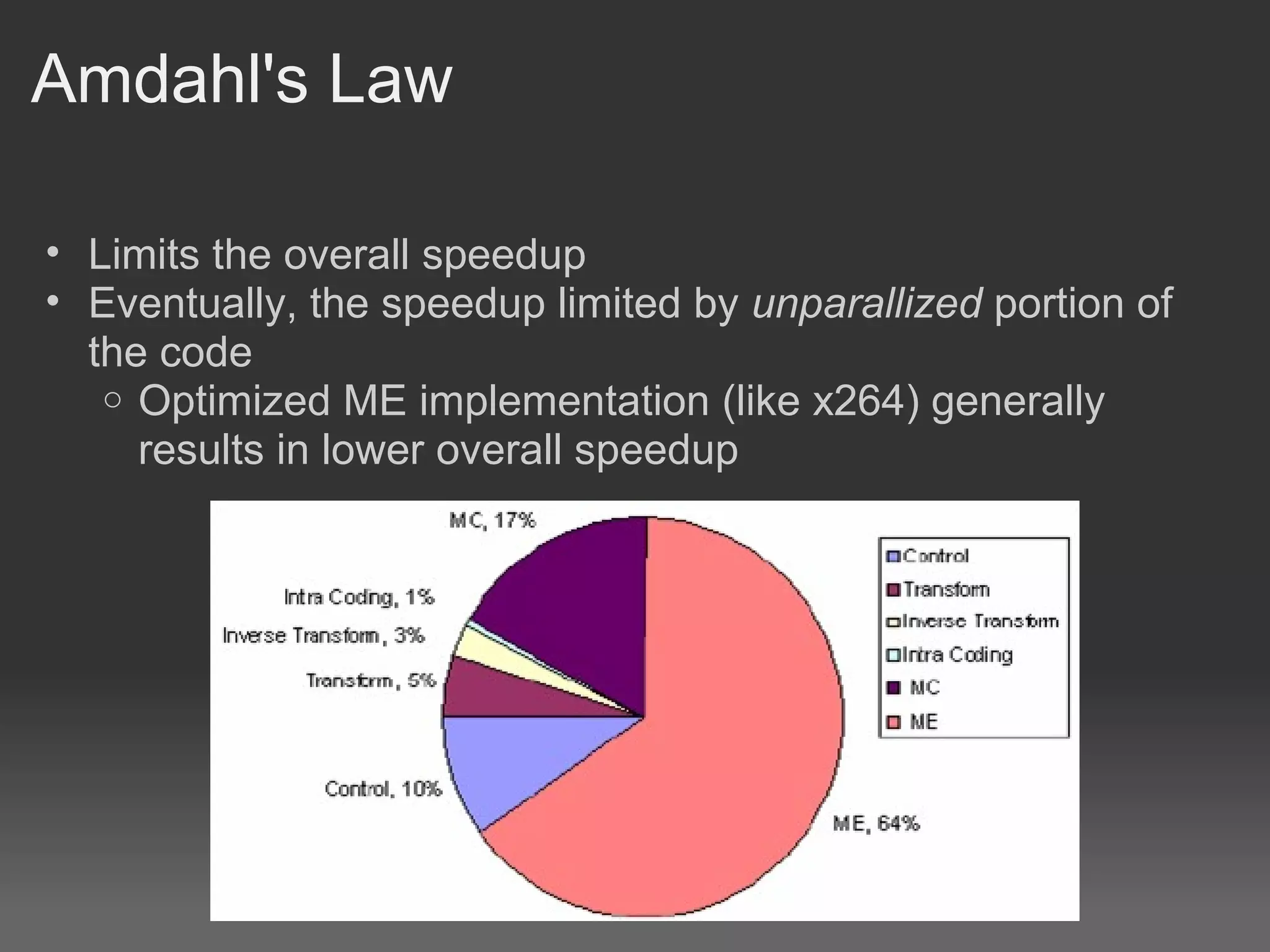
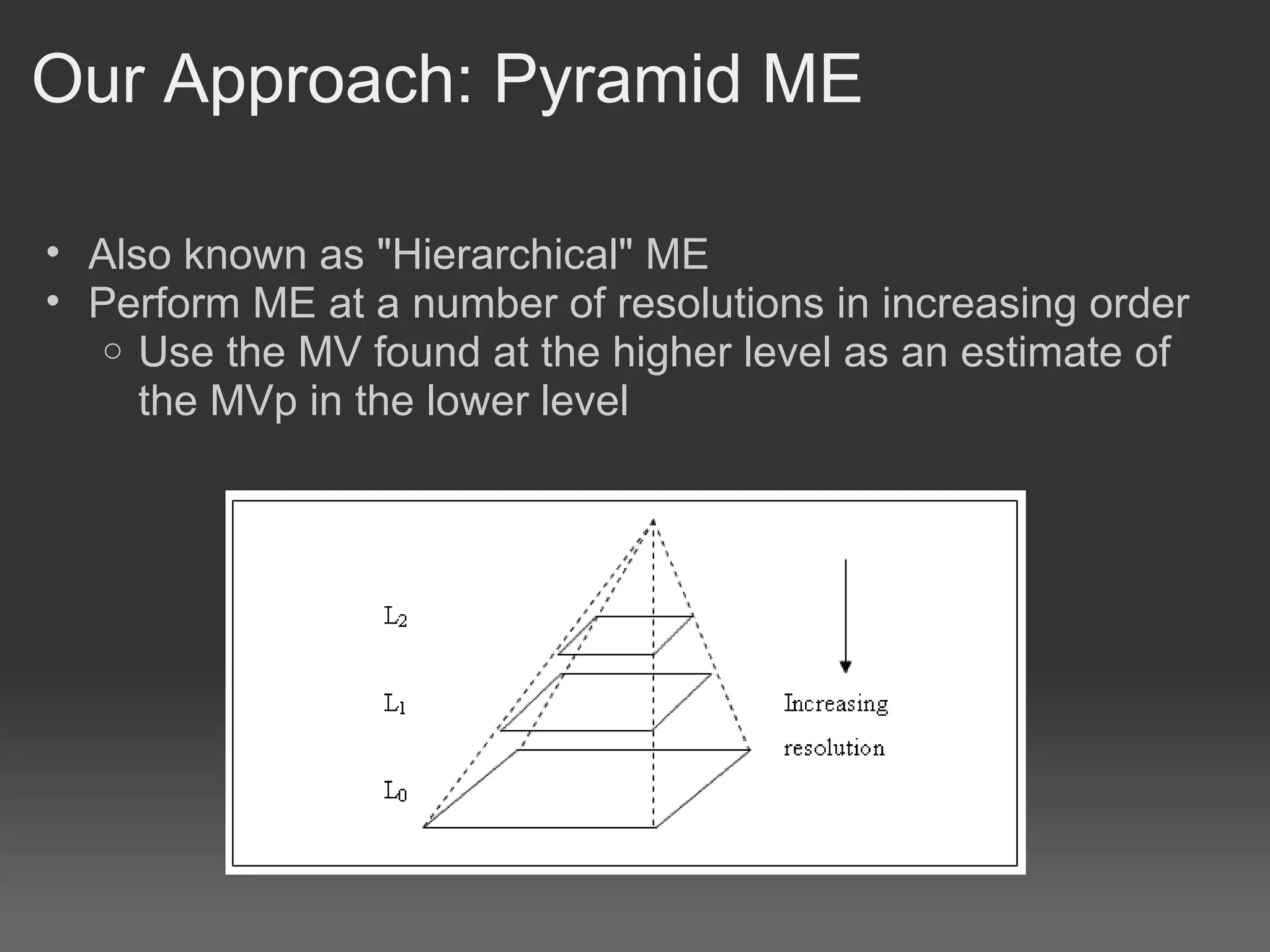
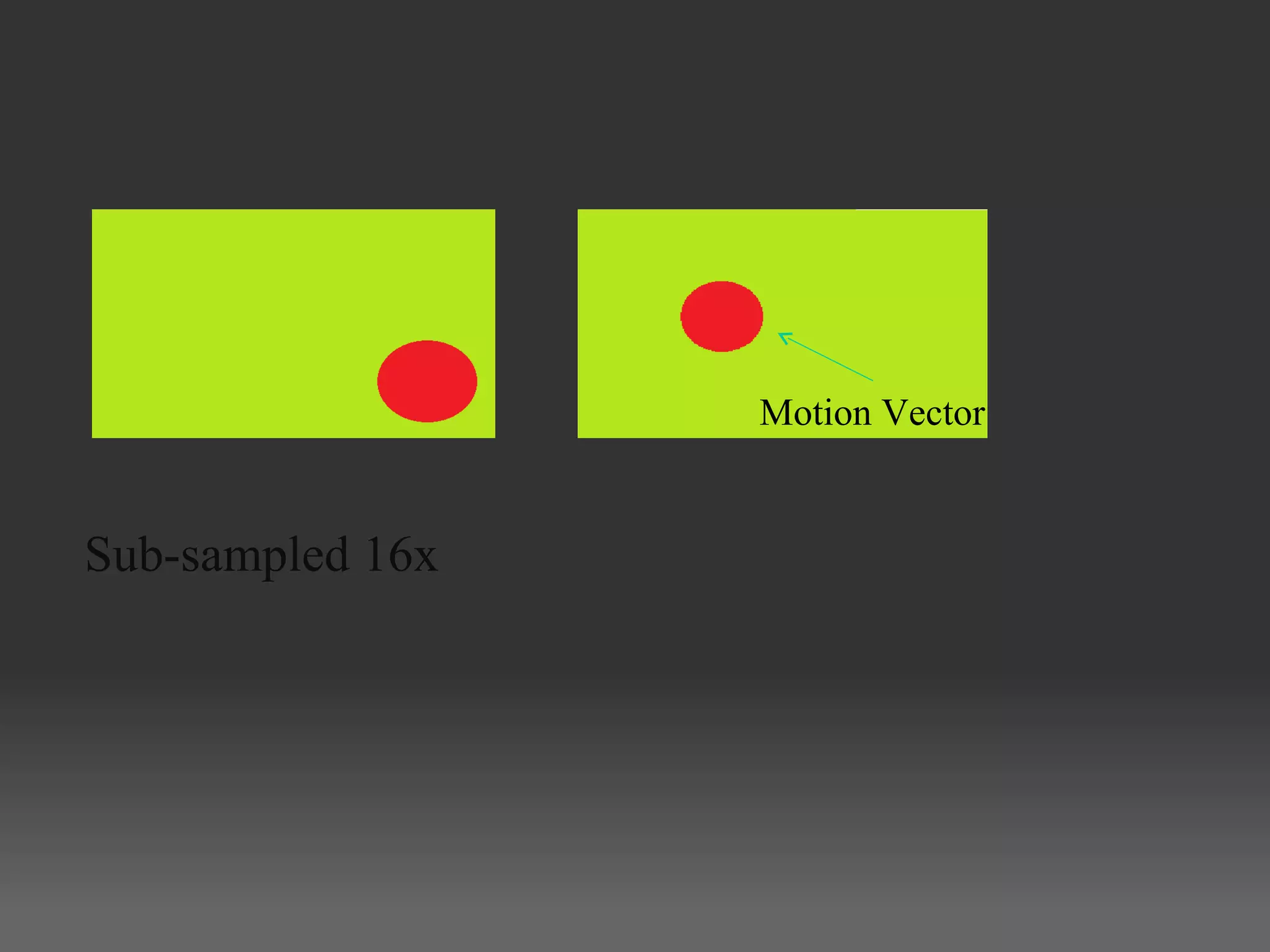
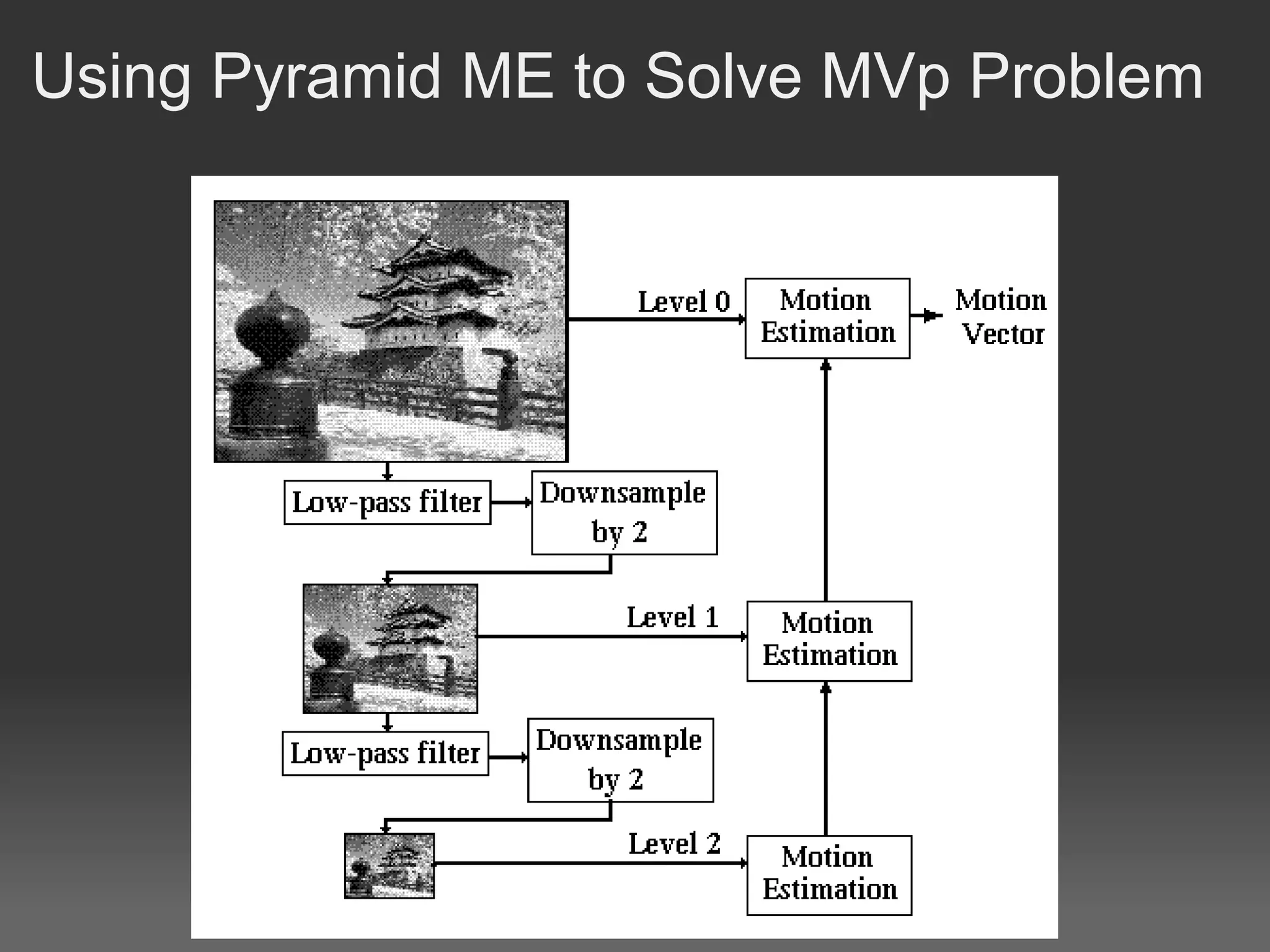
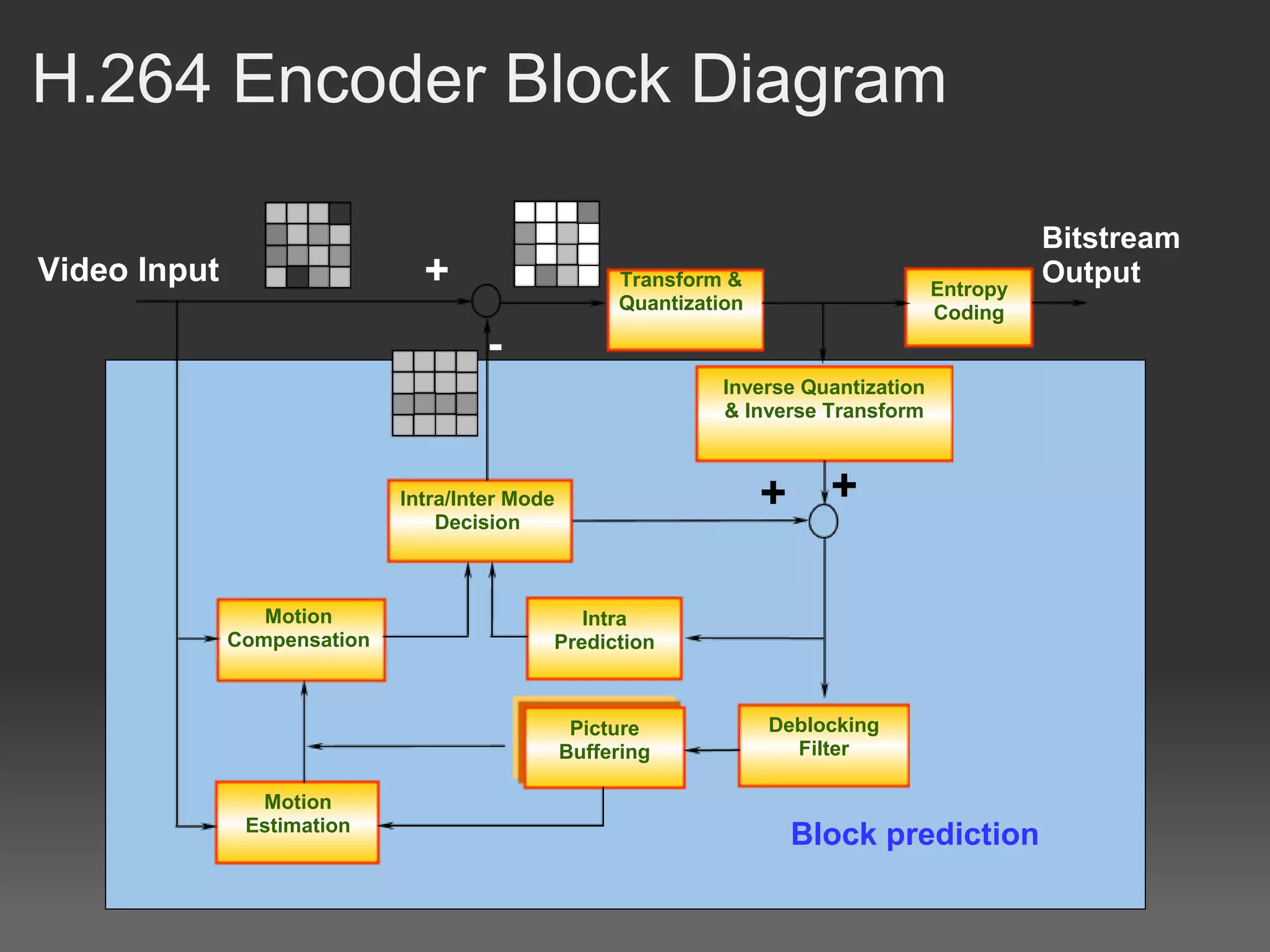
H.264, also known as MPEG-4 Part 10 or AVC, is a video compression standard that provides significantly better compression than previous standards such as MPEG-2. It achieves this through spatial and temporal redundancy reduction techniques including intra-frame prediction, inter-frame prediction, and entropy coding. Motion estimation, which finds motion vectors between frames to enable inter-frame prediction, is the most computationally intensive part of H.264 encoding. Previous GPU implementations of H.264 motion estimation have sacrificed quality for parallelism or have not fully addressed dependencies between blocks. This document proposes a pyramid motion estimation approach on GPU that can better address dependencies while maintaining quality.






































































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)










![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)







