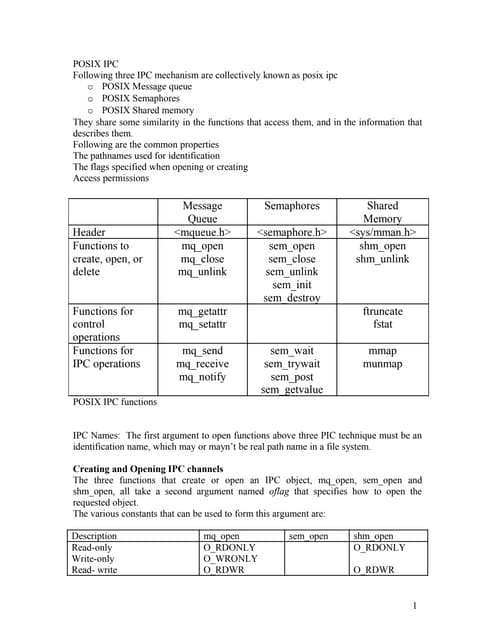
This document discusses shared memory and semaphores for inter-process communication. It describes:
1) Shared memory allows unrelated processes to access the same logical memory. Processes can create and attach to shared memory segments using system calls like shmget() and shmat().
2) Semaphores provide synchronization between processes. There are unnamed binary semaphores used for critical sections and named semaphores identified by name that can be accessed by multiple processes. Semaphore operations like sem_wait() and sem_post() are used for locking and unlocking.