Downloaded 42 times












![15
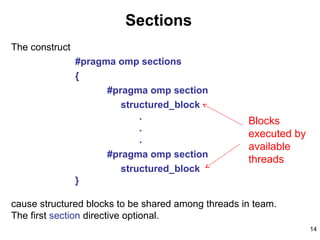
Example
#pragma omp parallel shared(a,b,c,d,nthreads) private(i,tid)
{
tid = omp_get_thread_num();
#pragma omp sections nowait
{
#pragma omp section
{
printf("Thread %d doing section 1n",tid);
for (i=0; i<N; i++) {
c[i] = a[i] + b[i];
printf("Thread %d: c[%d]= %fn",tid,i,c[i]);
}
}
#pragma omp section
{
printf("Thread %d doing section 2n",tid);
for (i=0; i<N; i++) {
d[i] = a[i] * b[i];
printf("Thread %d: d[%d]= %fn",tid,i,d[i]);
}
}
} /* end of sections */
} /* end of parallel section */
One
thread
does this
Another
thread
does this](https://image.slidesharecdn.com/slides8b-130504122937-phpapp02/85/Programming-using-Open-Mp-15-320.jpg)

![17
Example
#pragma omp parallel shared(a,b,c,nthreads,chunk) private(i,tid)
{
tid = omp_get_thread_num();
if (tid == 0) {
nthreads = omp_get_num_threads();
printf("Number of threads = %dn", nthreads);
}
printf("Thread %d starting...n",tid);
#pragma omp for schedule(dynamic,chunk)
for (i=0; i<N; i++) {
c[i] = a[i] + b[i];
printf("Thread %d: c[%d]= %fn",tid,i,c[i]);
}
} /* end of parallel section */
For loop
Executed by
one thread](https://image.slidesharecdn.com/slides8b-130504122937-phpapp02/85/Programming-using-Open-Mp-17-320.jpg)















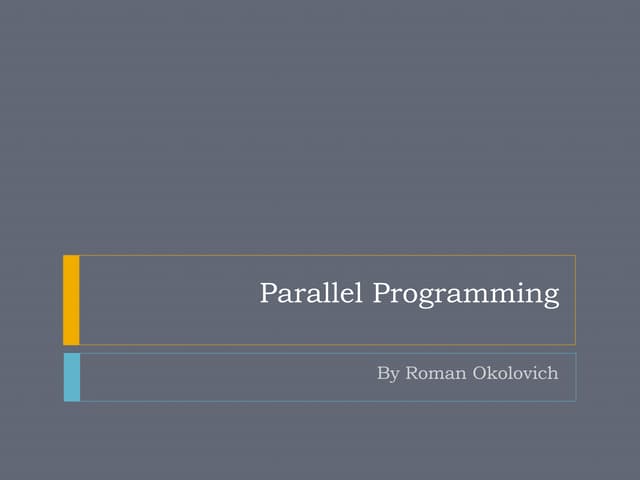
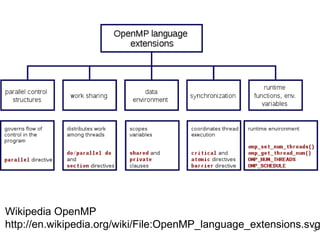
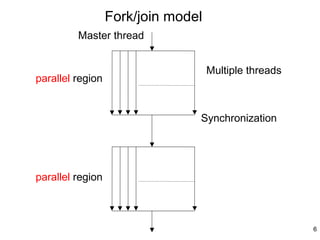
This document provides an introduction to OpenMP, a standard for parallel programming using shared memory. OpenMP uses compiler directives like #pragma omp parallel to create threads that can access shared data. It uses a fork-join model where the master thread creates worker threads to execute blocks of code in parallel. OpenMP supports work sharing constructs like parallel for loops and sections to distribute work among threads, and synchronization constructs like barriers to coordinate thread execution. Variables can be declared as private to each thread or shared among all threads.