Downloaded 51 times




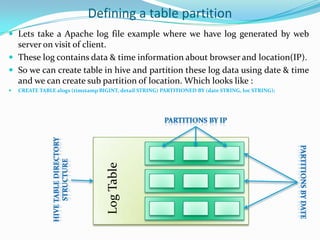


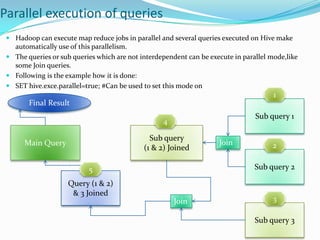


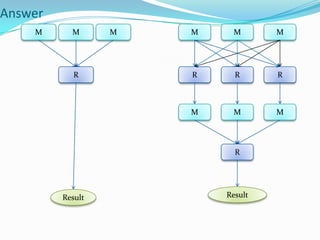




Well designed tables like partitioning and bucketing can improve query speed and reduce costs. Partitioning involves horizontally slicing data, such as by date or location. Bucketing imposes structure allowing more efficient queries, sampling, and map-side joins. Parallel query execution allows subqueries to run simultaneously to improve performance. The explain command helps analyze queries and identify optimizations.











































































































