Downloaded 20 times




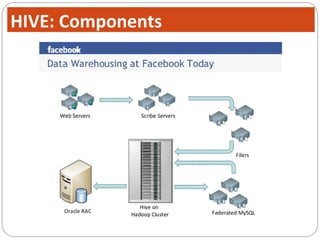




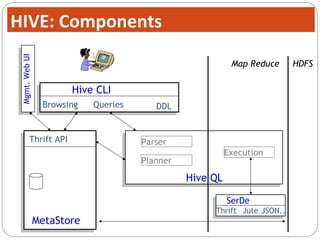



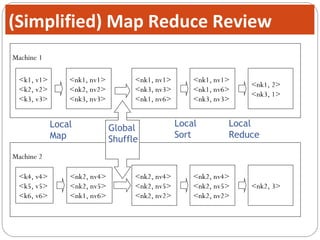
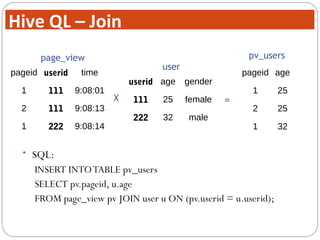



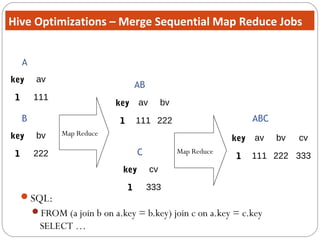







The document discusses Hive, a data warehouse infrastructure built on top of Hadoop. It provides the following key points: - Hive provides a mechanism for analysts to query large datasets using a SQL-like language called HiveQL instead of using Java programs. This allows analysts who do not know Java to work with Hadoop. - Hive includes components like a shell, compiler, execution engine, and metastore to allow SQL-like queries over data stored in Hadoop files. It uses a metastore to manage metadata about tables and their physical storage. - Hive represents data as tables partitioned into buckets or ranges. It uses a data model similar to relational databases to organize data and query it using SQL-











![[Harvard CS264] 08b - MapReduce and Hadoop (Zak Stone, Harvard)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264hadooplecture2011-110322172329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)























































