Downloaded 61 times



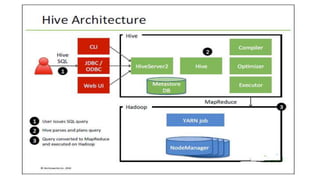



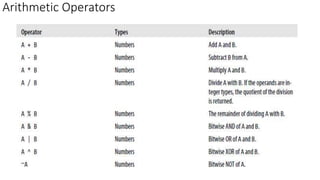






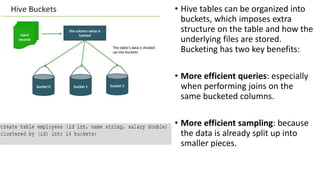





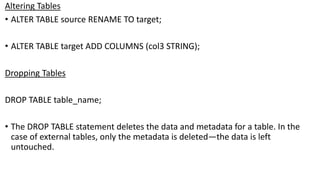





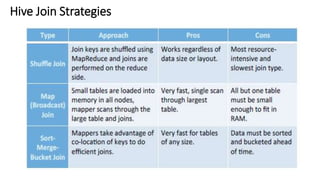

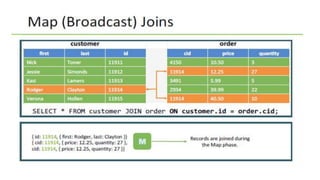


Apache Hive is a data warehouse system for Hadoop that allows users to perform SQL-like operations on big data stored in HDFS using a language called HiveQL. It manages metadata about data, organizes tables into managed and external categories, and utilizes MapReduce jobs for query execution. Hive also supports various data types, operations, and has features like partitioning, bucketing, and views to optimize performance and data handling.











































































