Downloaded 350 times



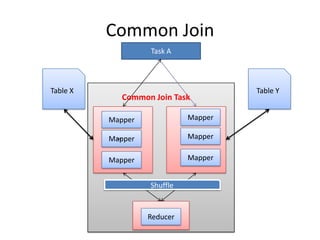
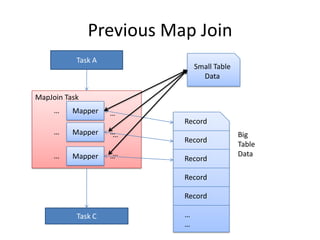
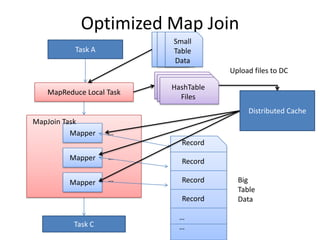

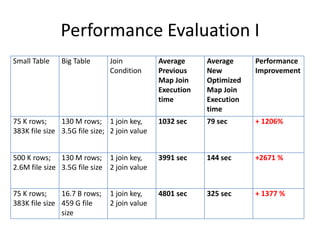
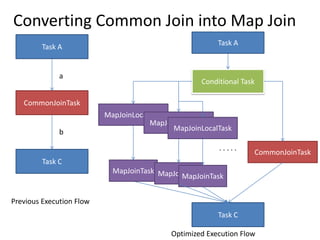
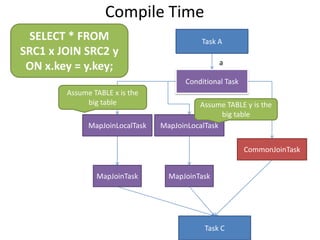
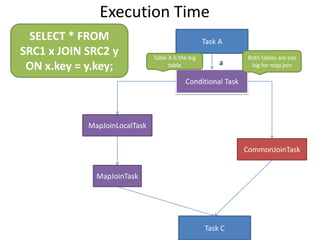
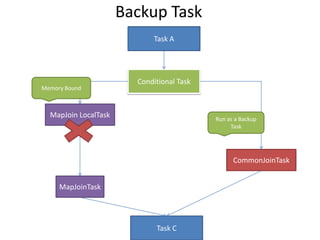

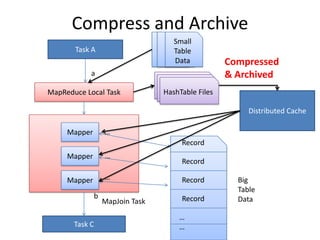
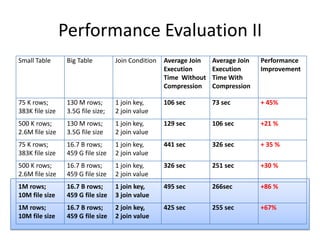
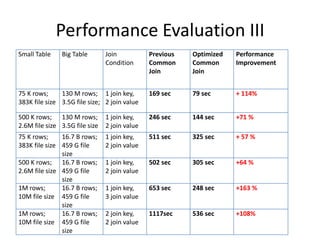



This document discusses optimization techniques for map join in Hive. It describes: 1) Previous approaches to common join and map join in Hive and their limitations. 2) Optimized map join techniques like uploading small tables to distributed cache and performing local joins to avoid shuffle. 3) Using JDBM for hash tables caused performance issues so alternative approaches were evaluated. 4) Automatically converting common joins to optimized map joins based on table sizes and joining conditional. 5) Compression and archiving of hash tables to distributed cache to reduce bandwidth overhead. 6) Performance evaluations showing improvements from the optimized techniques.















![[Harvard CS264] 08b - MapReduce and Hadoop (Zak Stone, Harvard)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264hadooplecture2011-110322172329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)































