Downloaded 212 times











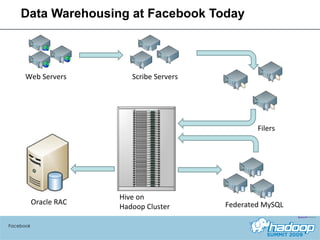




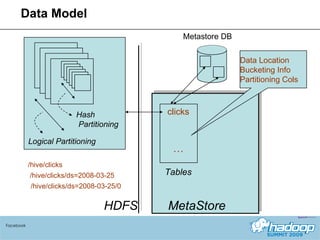
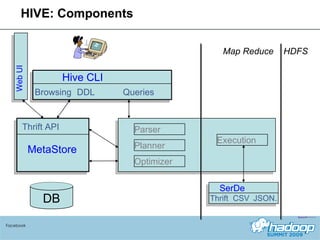




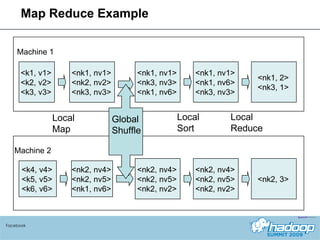



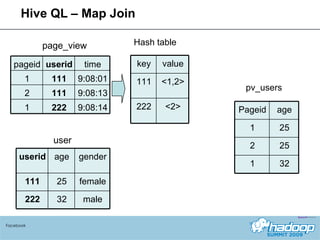

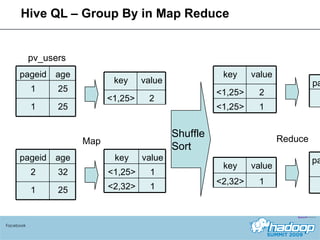















The document provides an overview of Hive, a data warehousing system built on Hadoop. It discusses how Hive is used at Facebook to manage large amounts of data, provides details on Hive's architecture and query language, and outlines ongoing work to improve performance and expand functionality.
























































