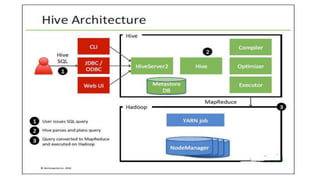
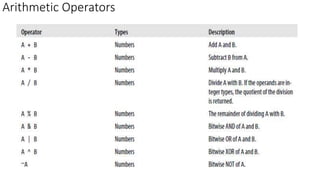
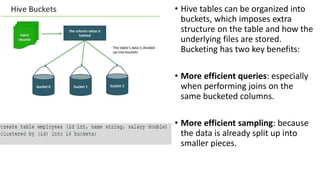
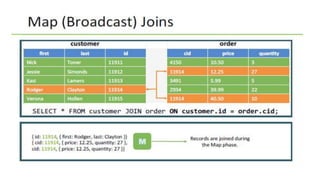
Apache Hive is a data warehouse system for Hadoop that facilitates SQL-like operations on big data via HiveQL, maintaining metadata in a metastore while data is stored in HDFS. Hive manages data in managed tables and allows referential control to external tables, providing efficient querying through bucketing and various storage formats. The document also details Hive's command execution architecture, data importing methods, and querying capabilities, including sorting, aggregating, and joins.