Downloaded 109 times


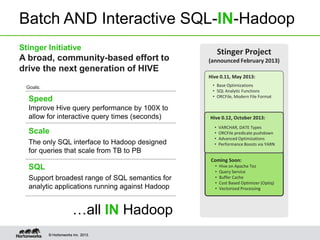






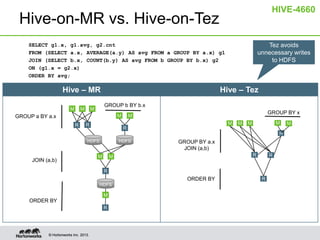
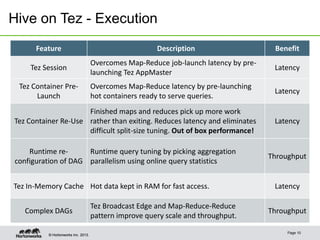
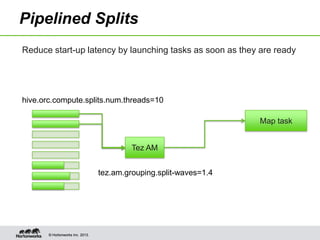
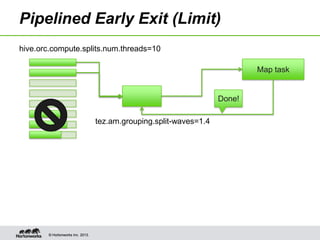







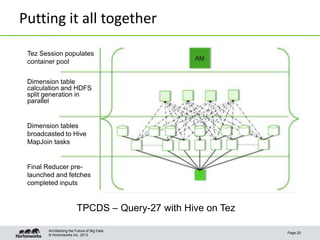
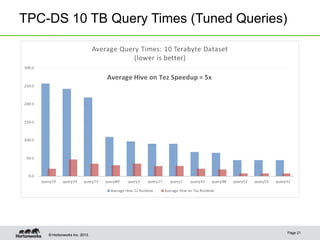
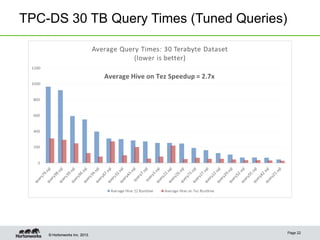


Hive on Tez provides significant performance improvements over Hive on MapReduce by leveraging Apache Tez for query execution. Key features of Hive on Tez include vectorized processing, dynamic partitioned hash joins, and broadcast joins which avoid unnecessary data writes to HDFS. Test results show Hive on Tez queries running up to 100x faster on datasets ranging from terabytes to petabytes in size. Hive on Tez also handles concurrency well, with the ability to run 20 queries concurrently on a 30TB dataset and finish within 27.5 minutes.





























































































