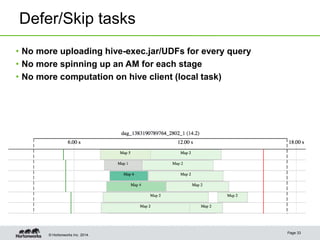
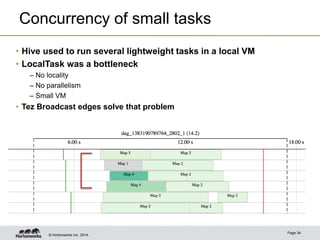
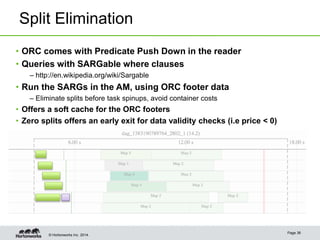
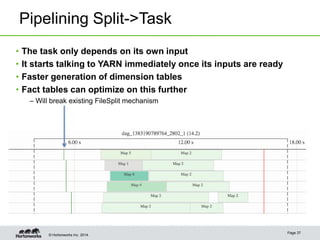
This document provides an overview of performance improvements in Hive through the use of Apache Tez and other optimizations. Some key points discussed include:
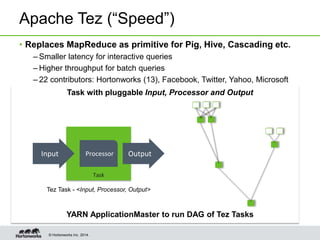
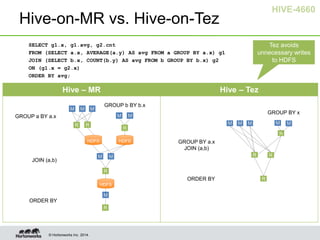
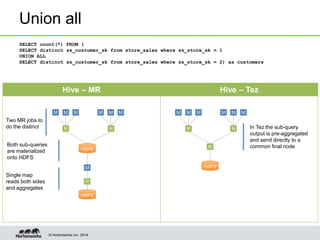
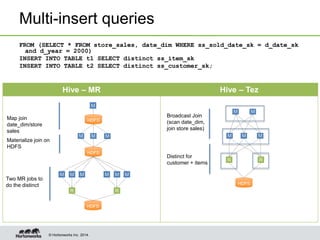
- Hive on Tez replaces MapReduce as the execution engine, providing lower latency for interactive queries and higher throughput for batch queries.
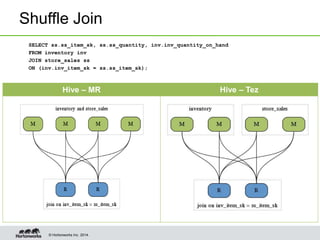
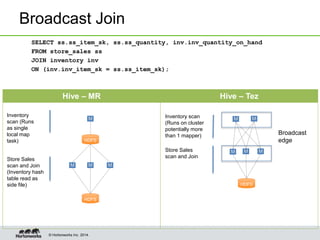
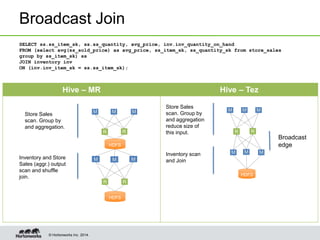
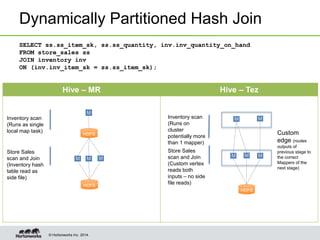
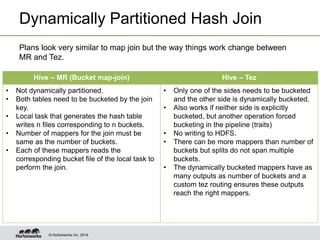
- Tez enables various join optimizations like broadcast joins, dynamically partitioned hash joins, and 1-1 edges between tasks to improve performance.
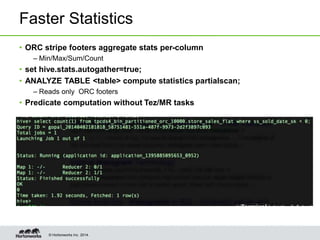
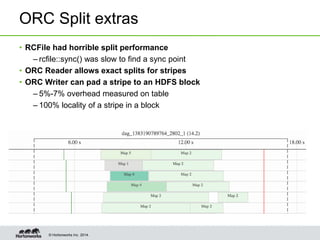
- Other optimizations in Hive include vectorized query processing, cost-based optimization, faster query startup times, predicate pushdown in ORC files, and statistics gathering from ORC footers.
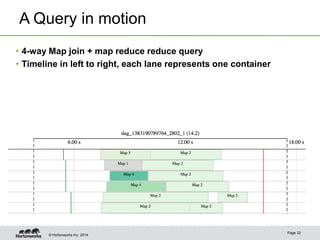
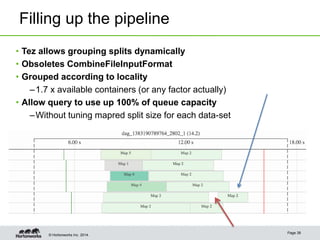
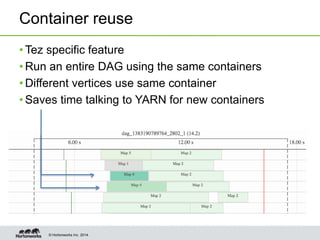
- Tez allows for pipelining of tasks, dynamic parallelism, split elimination, and