Downloaded 53 times







![© Hortonworks Inc. 2011 – 2015. All Rights Reserved
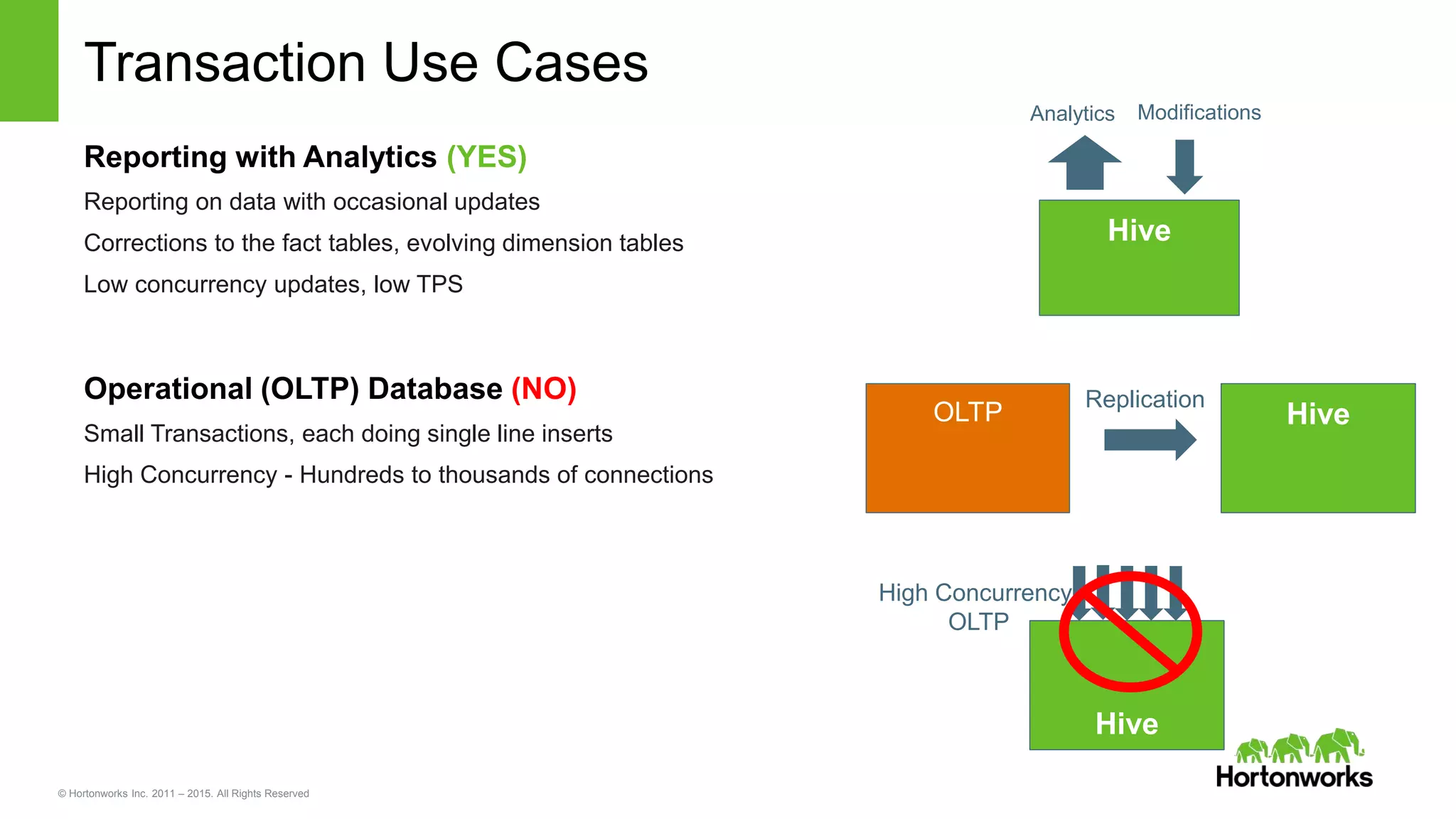
Deep Dive: Transaction
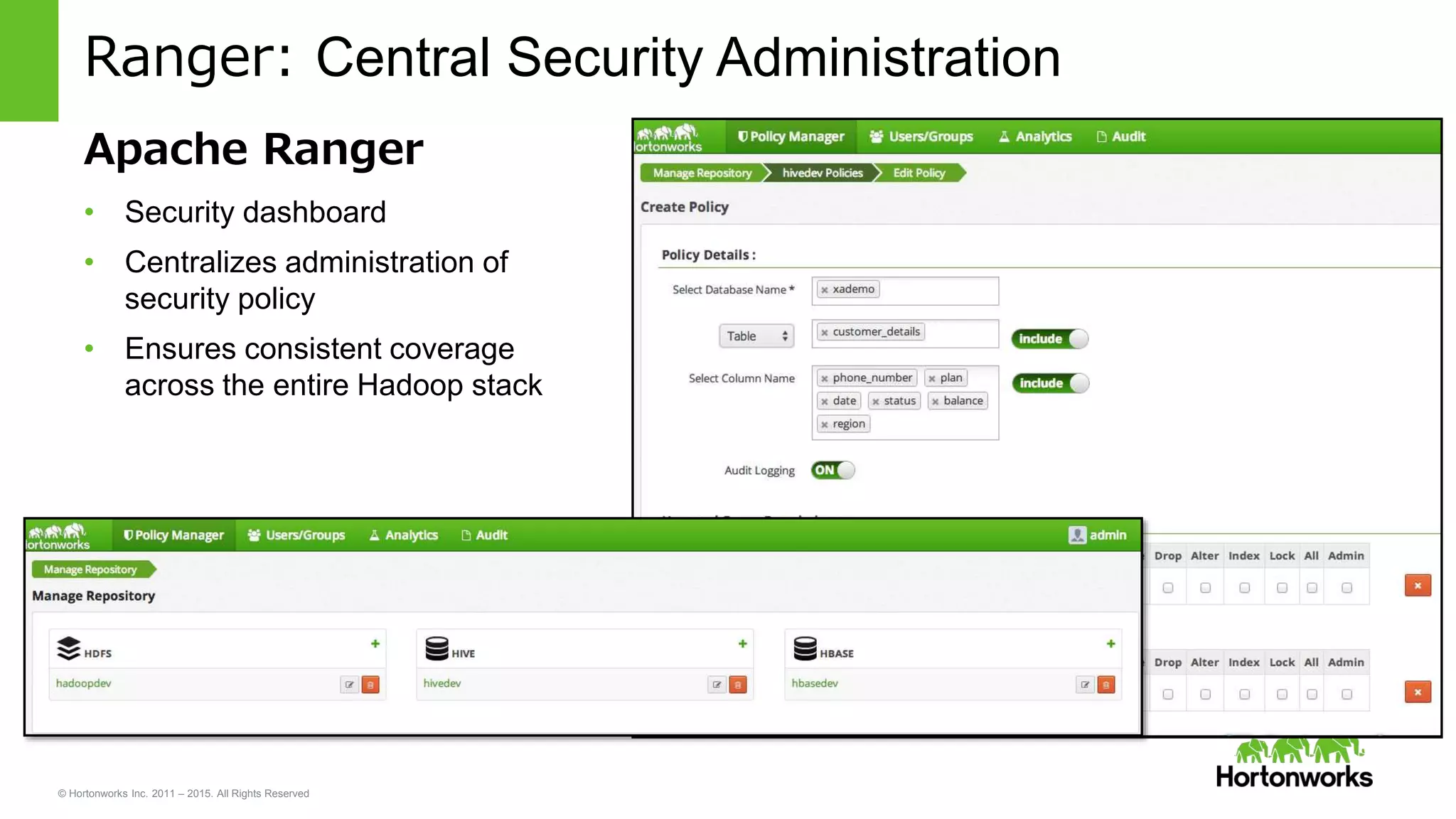
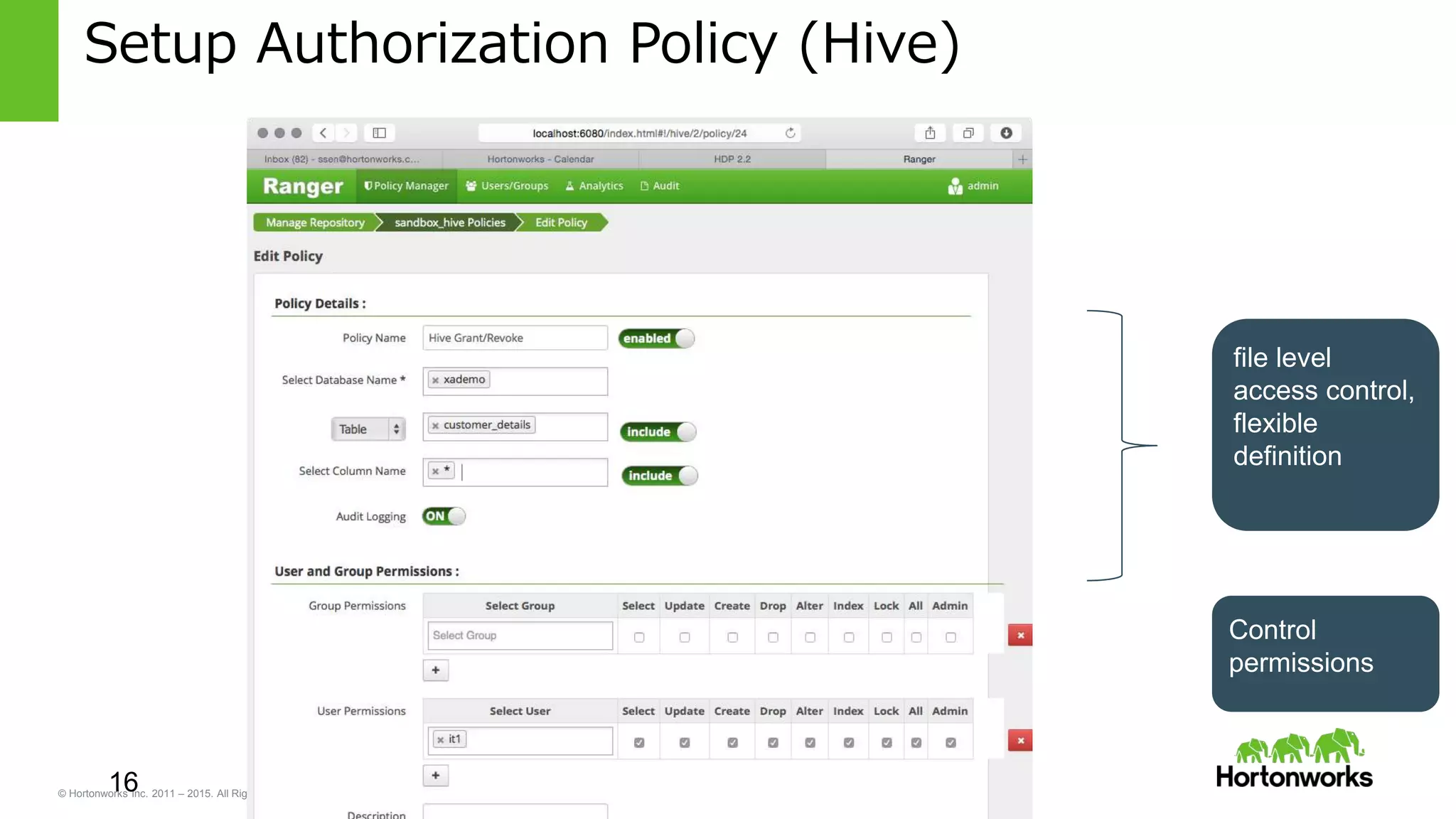
Transaction Support in Hive with ACID semantics
• Hive native support for INSERT, UPDATE, DELETE.
• Split Into Phases:
• Phase 1: Hive Streaming Ingest (append)
• Phase 2: INSERT / UPDATE / DELETE Support
• Phase 3: BEGIN / COMMIT / ROLLBACK Txn
[Done]
[Done]
[Next]
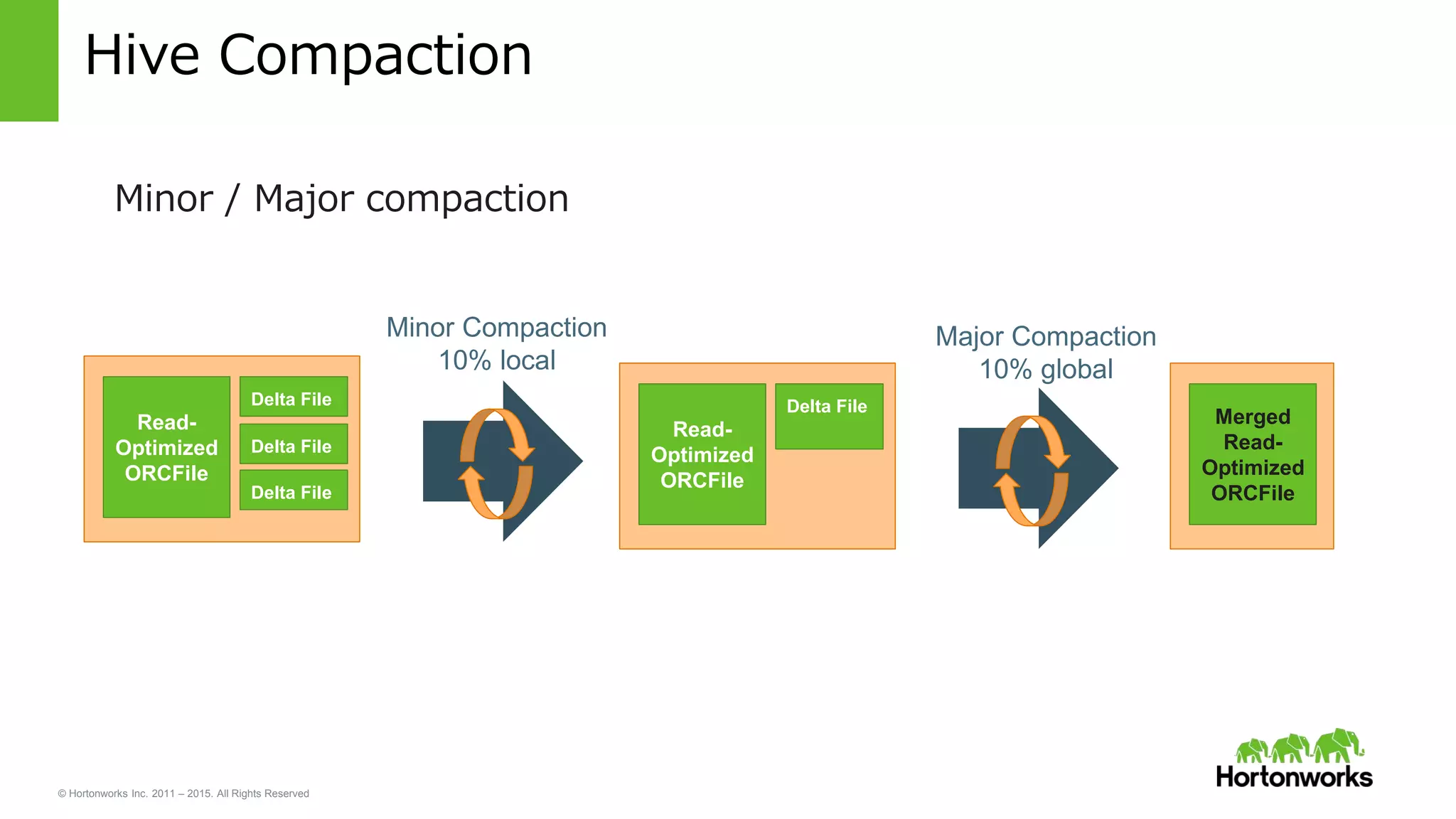
Read-
Optimized
ORCFile
Delta File
Merged
Read-
Optimized
ORCFile
1. Original File
Task reads the latest
ORCFile
Task
Read-
Optimized
ORCFile
Task Task
2. Edits Made
Task reads the ORCFile and merges
the delta file with the edits
3. Edits Merged
Task reads the
updated ORCFile
Hive ACID Compactor
periodically merges the delta
files in the background.](https://image.slidesharecdn.com/hive-present-and-feature-shanghai-150803035656-lva1-app6891/75/Hive-present-and-feature-shanghai-12-2048.jpg)


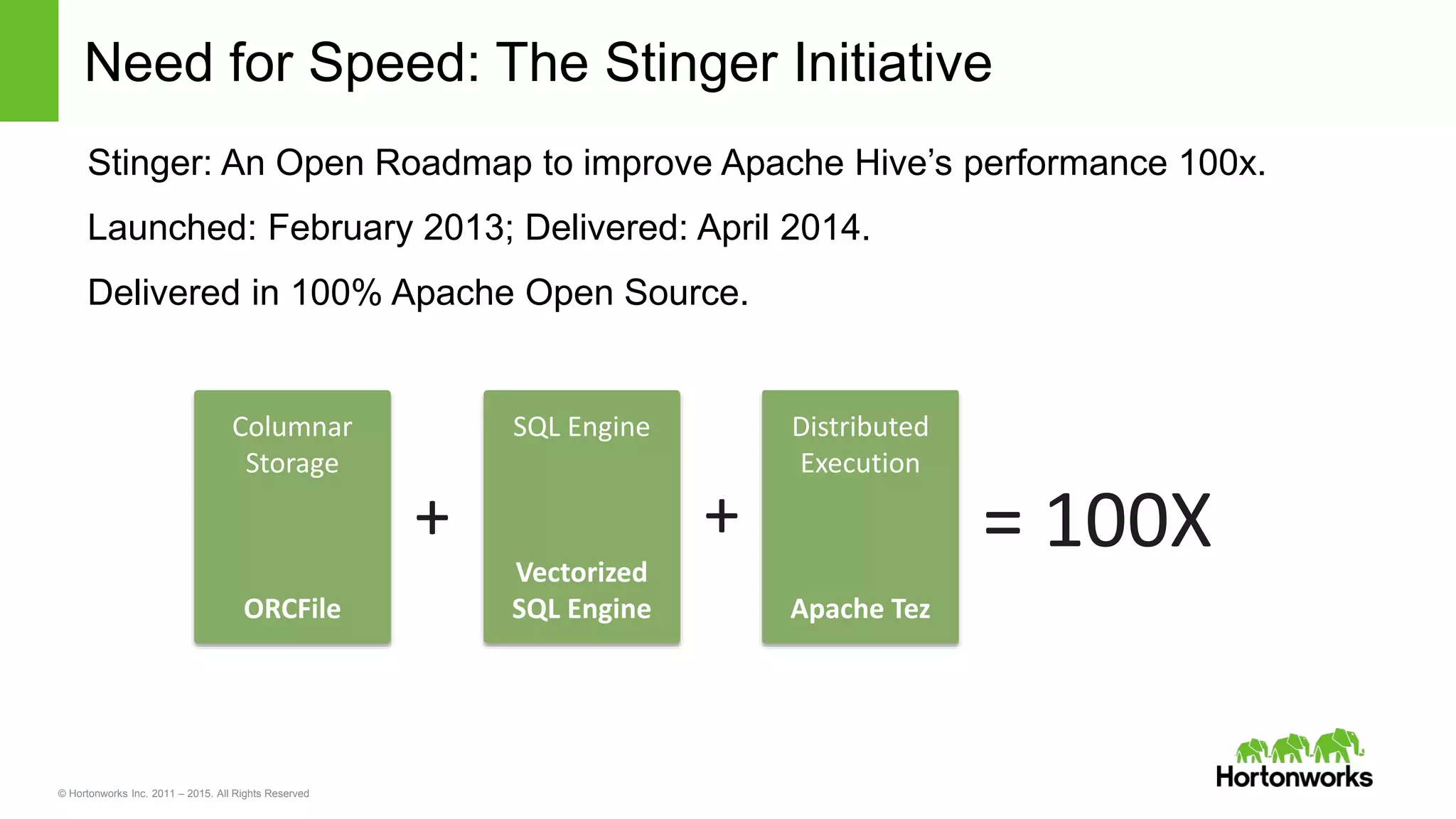
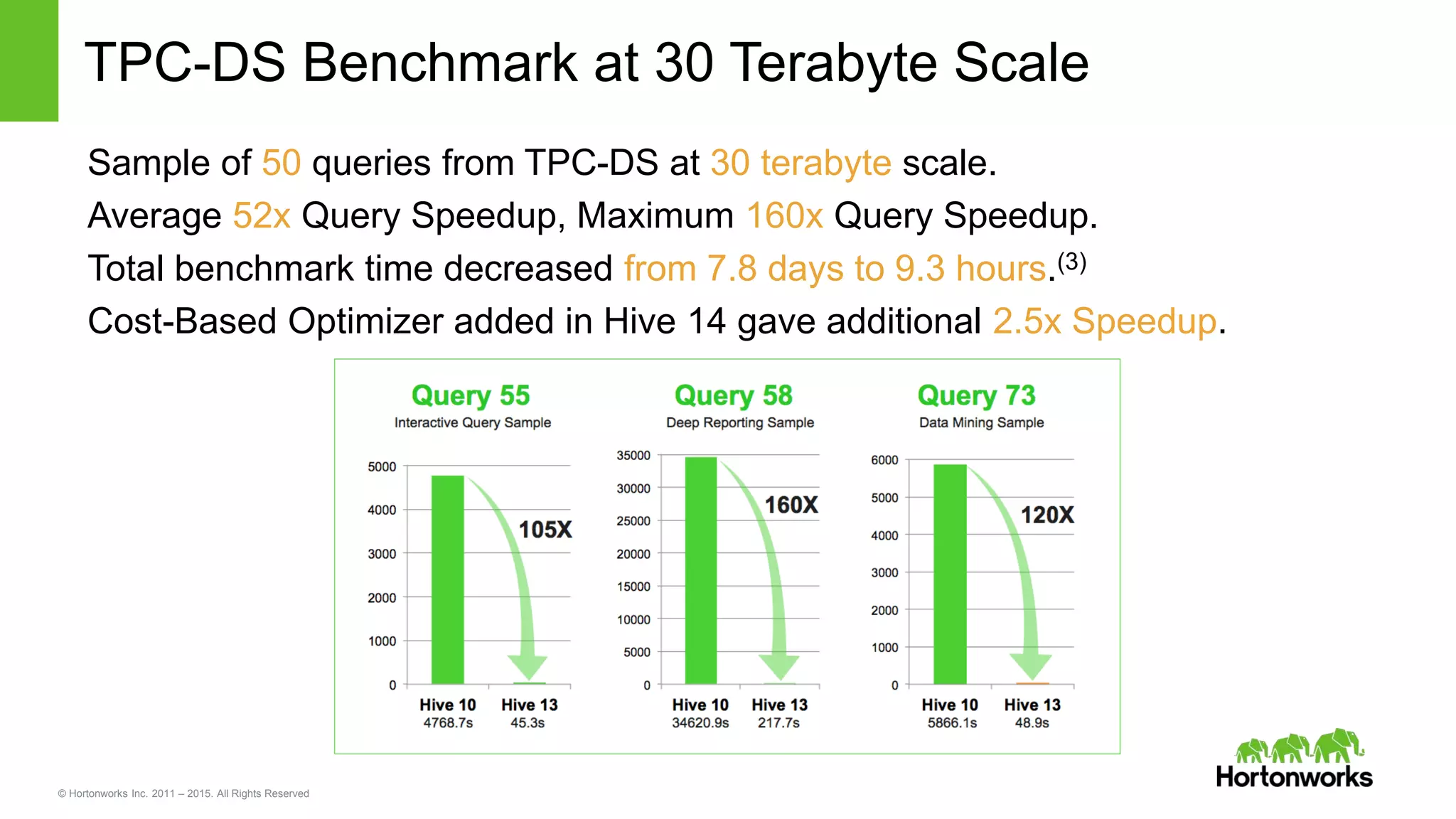


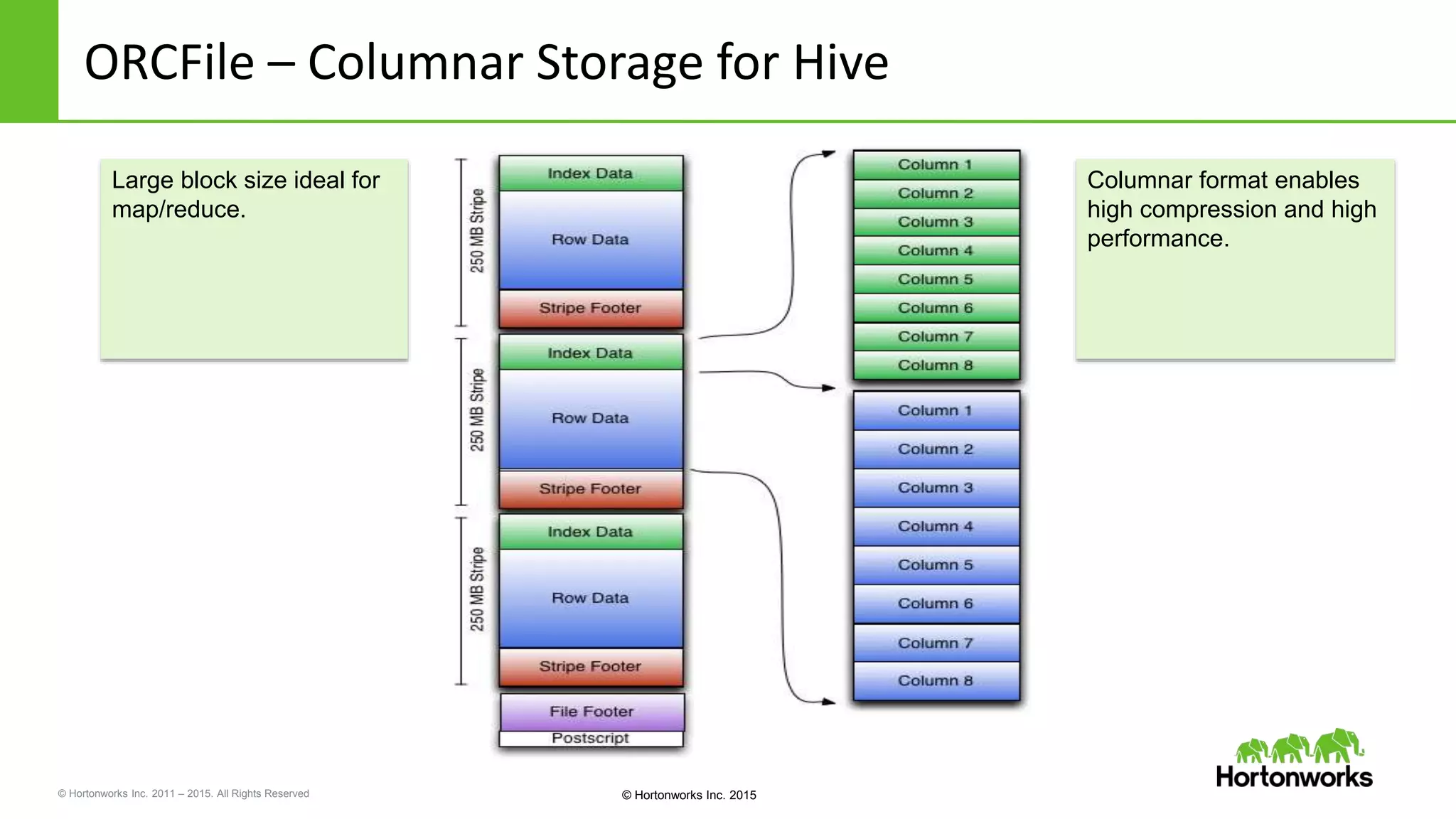



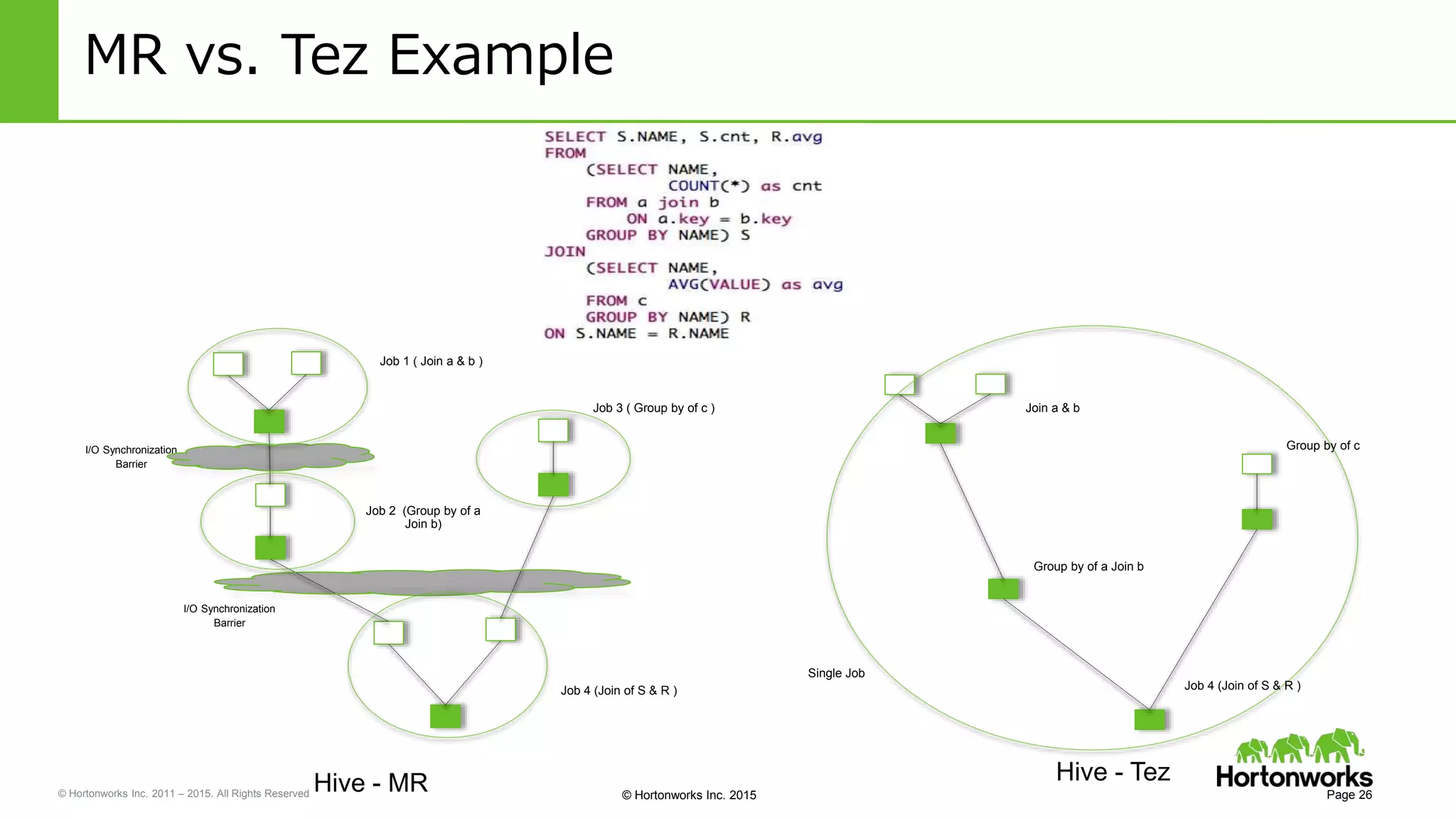



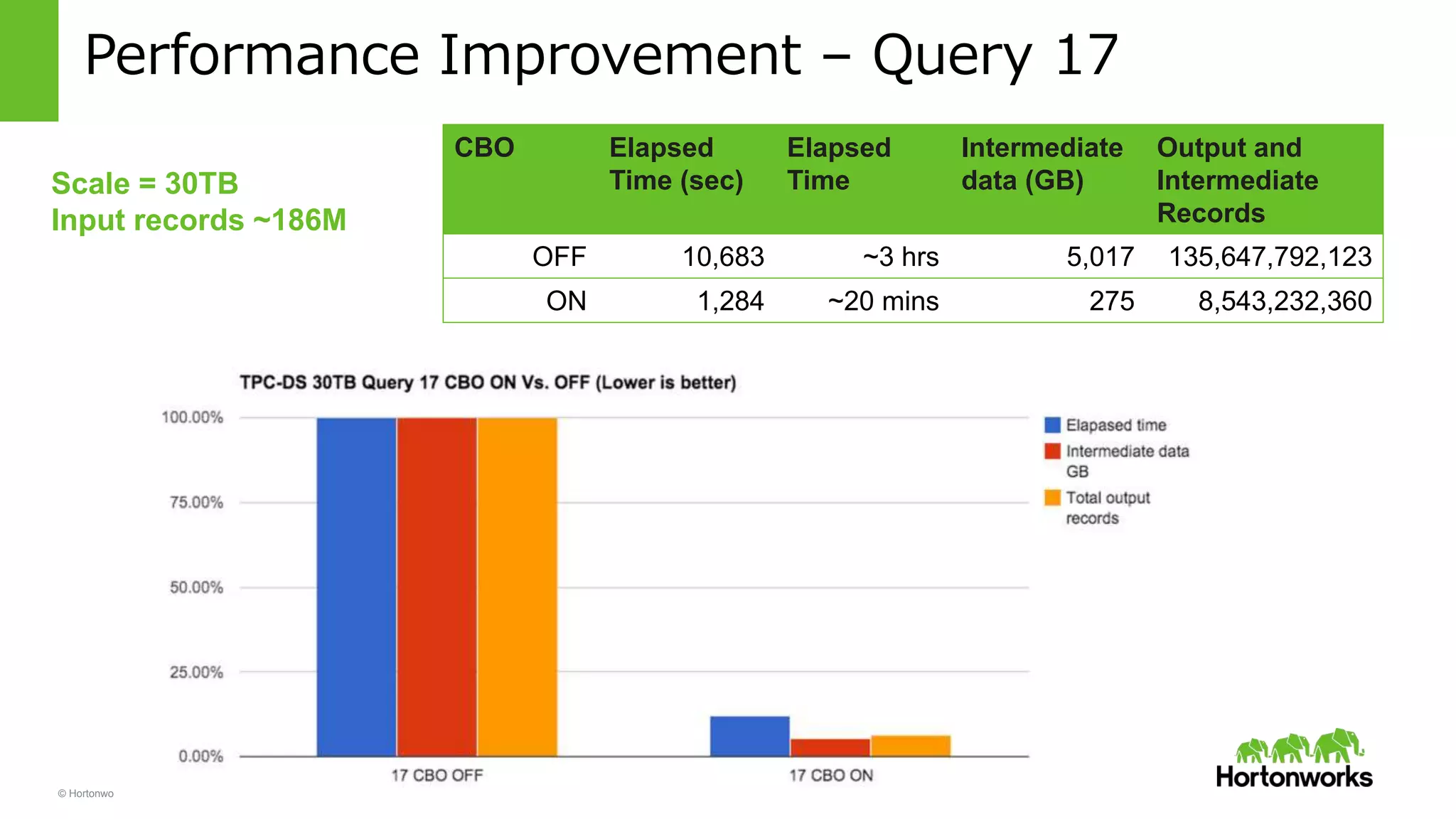






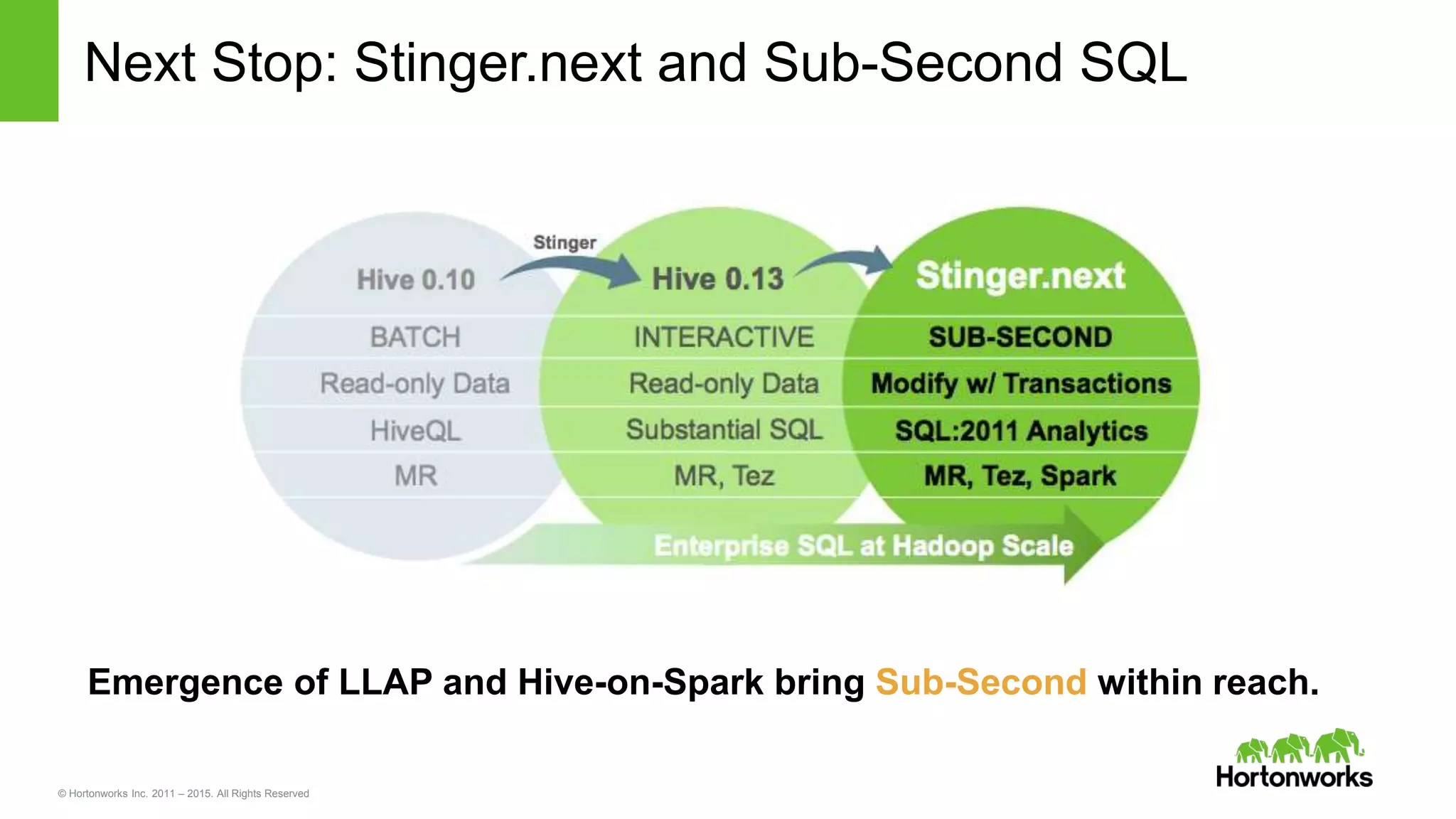
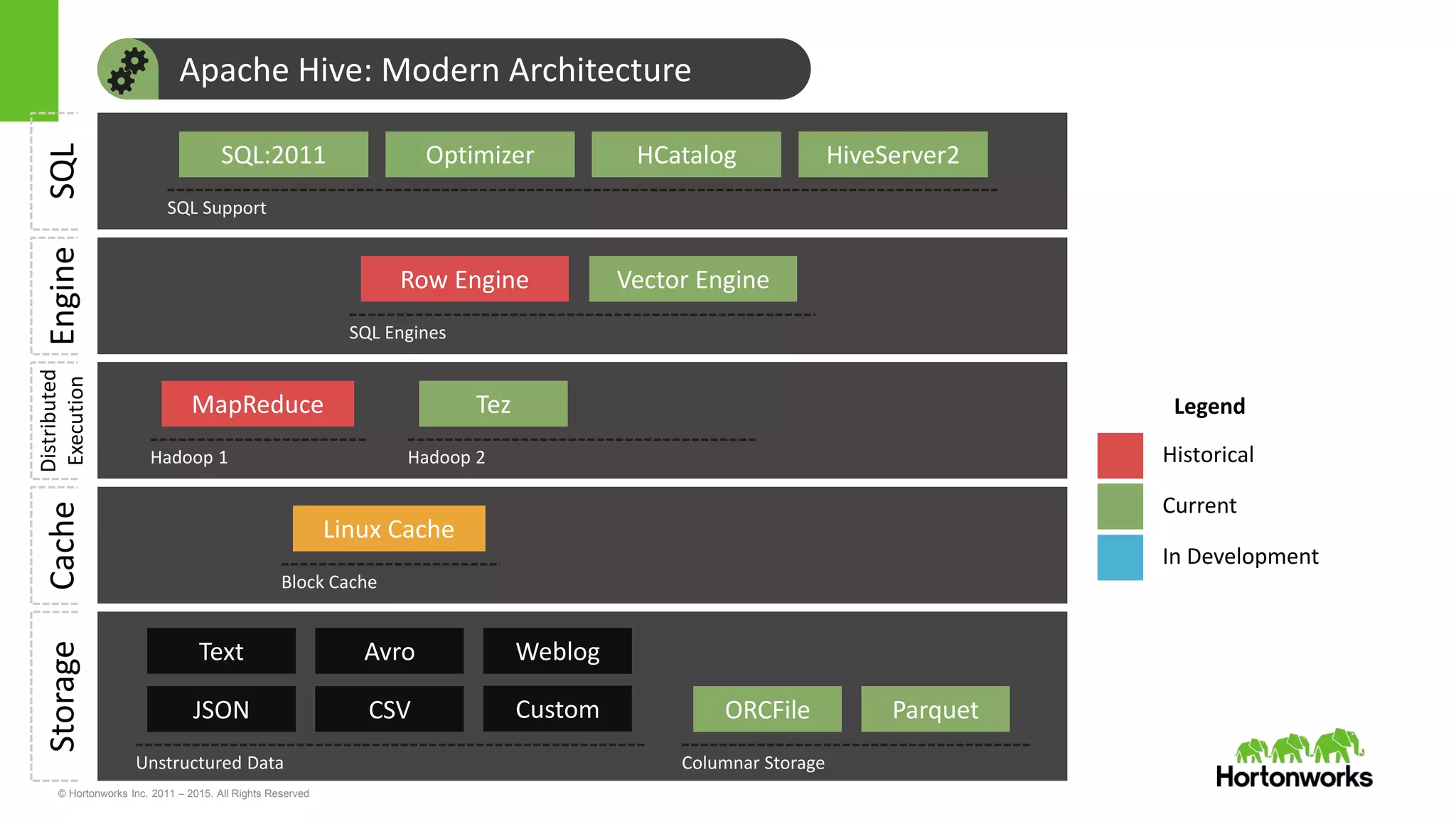
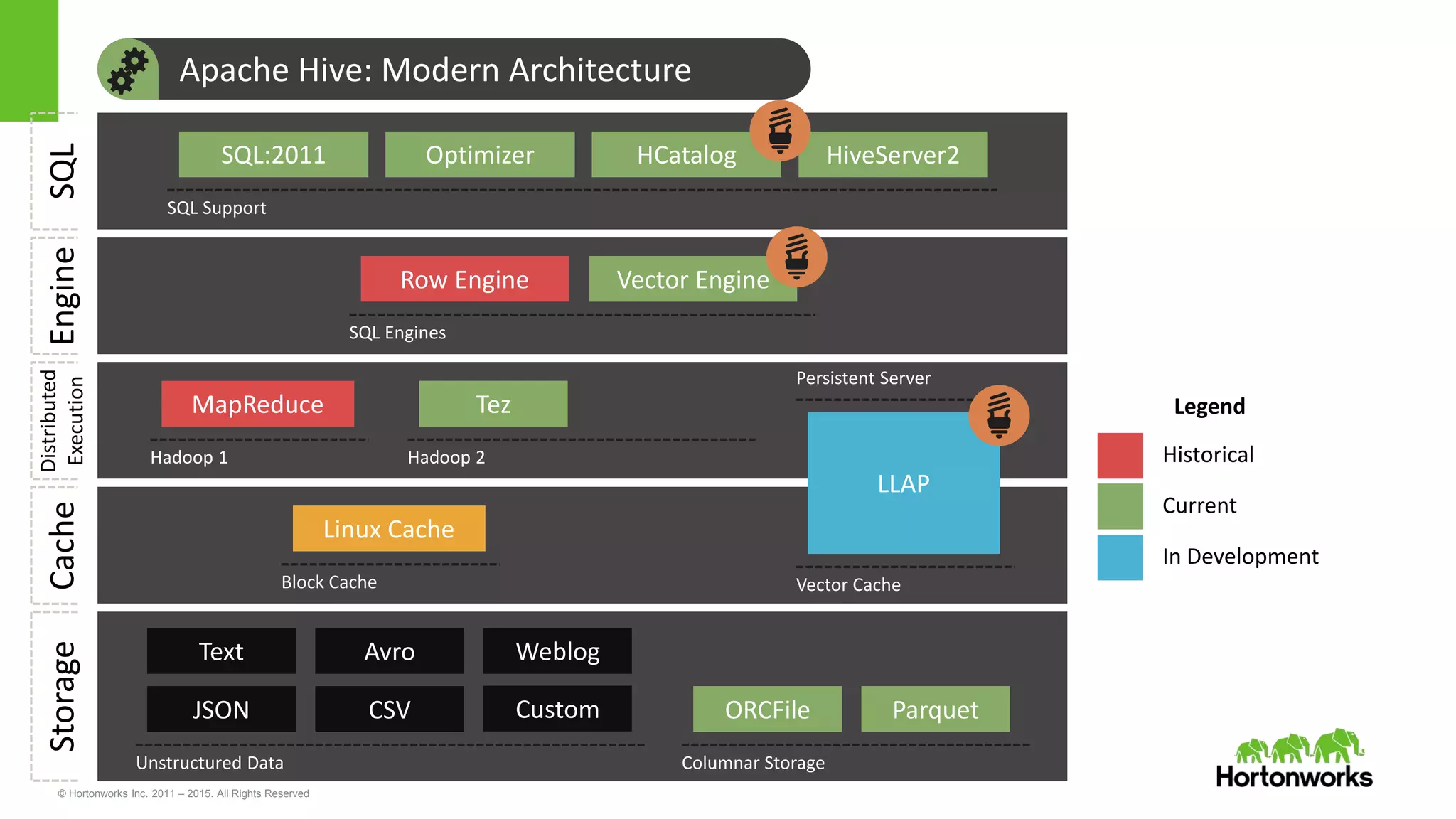
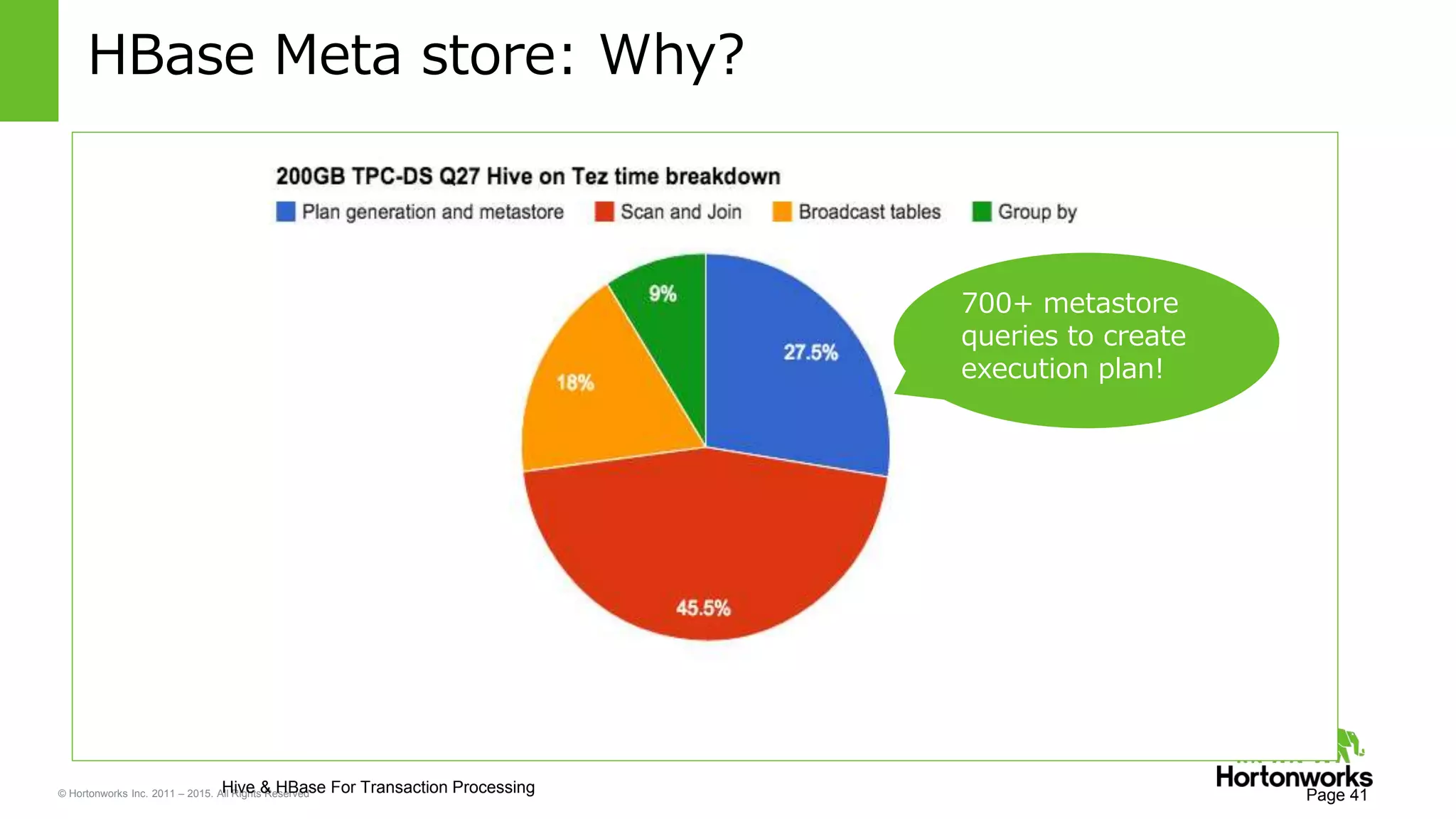
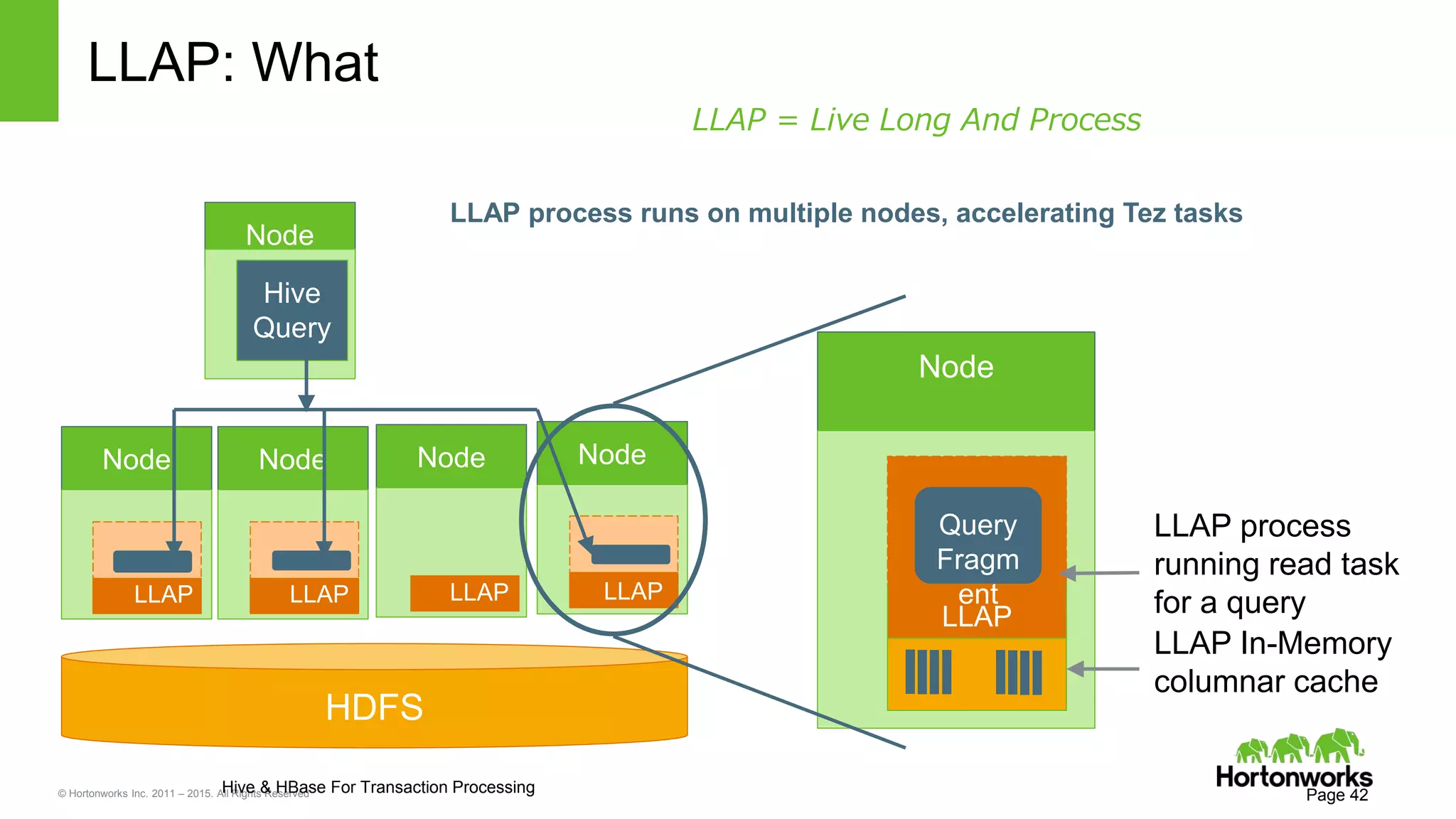
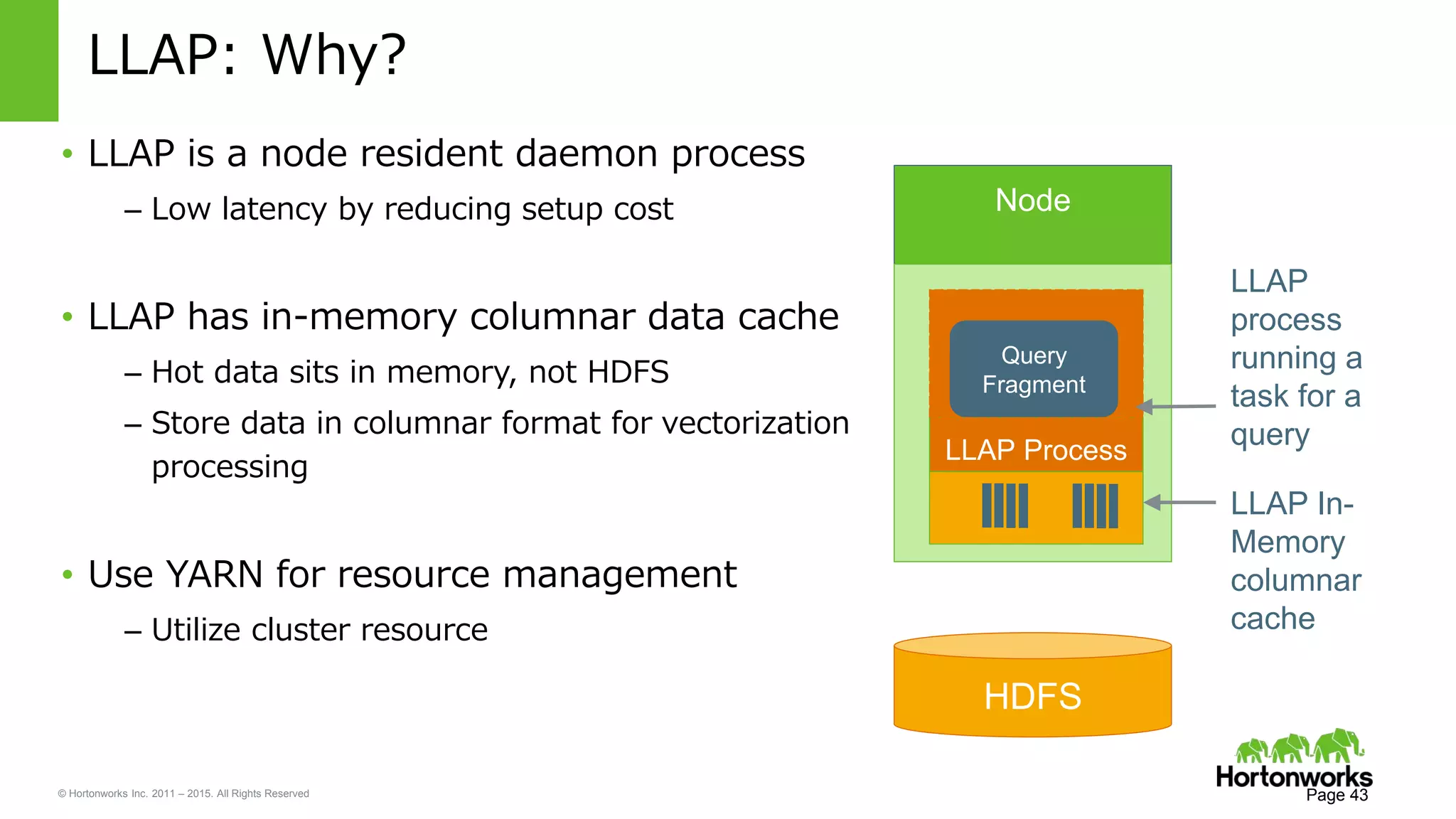
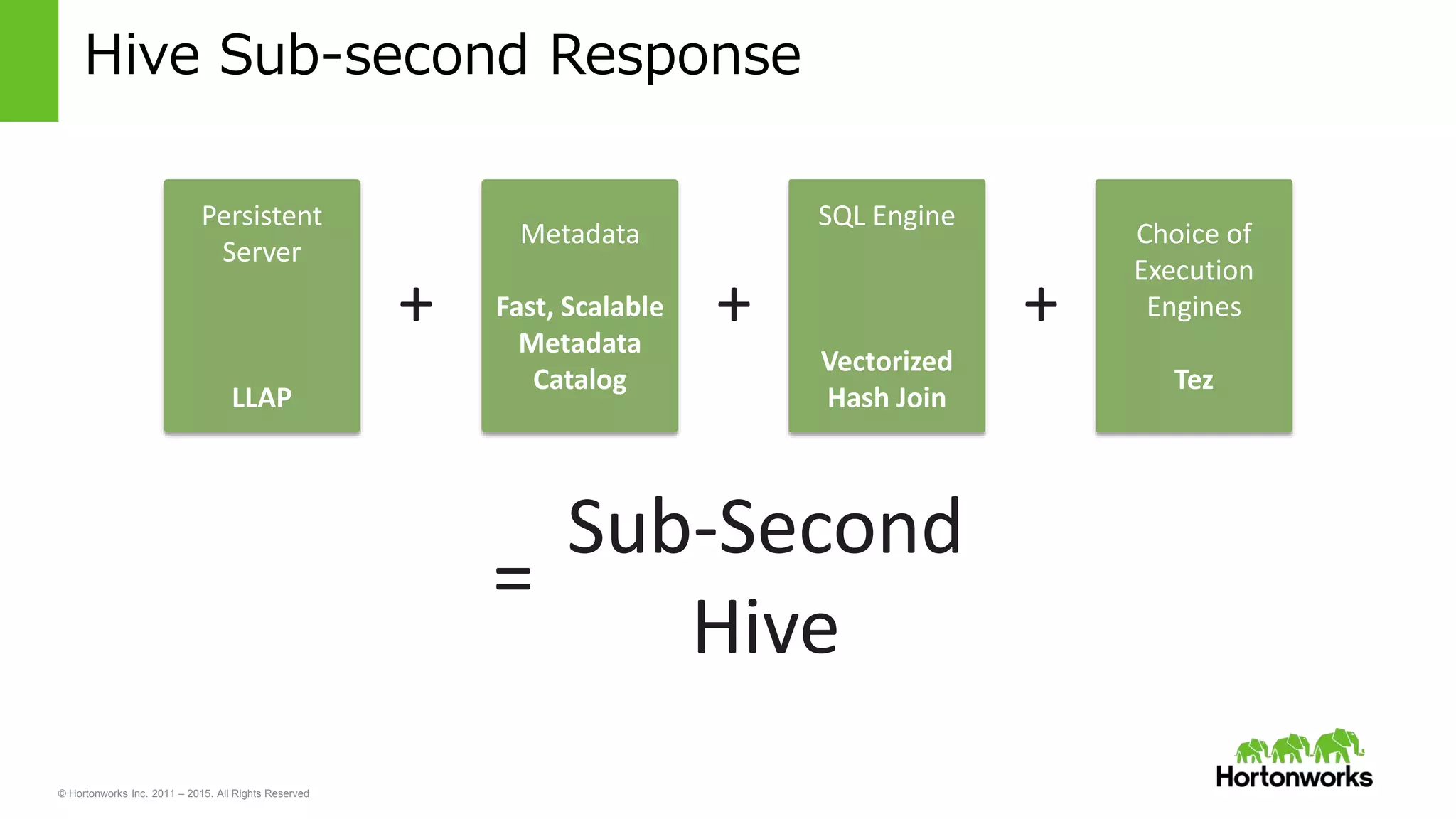





Yifeng Jiang presented on Apache Hive's present and future capabilities. Hive has achieved 100x performance improvements through technologies like ORC file format, Tez execution engine, and vectorized processing. Upcoming features like LLAP caching and a persistent Hive server aim to provide sub-second query response times for interactive analytics. Hive continues to evolve as the standard SQL interface for Hadoop, supporting a wide range of use cases from ETL and reporting to real-time analytics.























































































