Downloaded 18 times



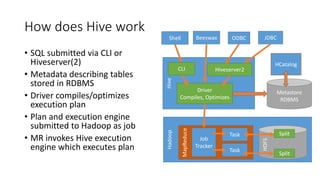









1) Hive is a data warehouse infrastructure built on top of Hadoop for querying large datasets stored in HDFS. It provides SQL-like capabilities to analyze data and supports complex queries using a MapReduce execution engine. 2) Hive compiles SQL queries into a directed acyclic graph (DAG) of MapReduce jobs that are executed by Hadoop. The metadata is stored in a metastore (typically an RDBMS). 3) Hive supports advanced features like partitioning, bucketing, acid transactions, and complex types. It can handle petabyte-scale datasets and integrates with the Hadoop ecosystem but has limitations for low-latency queries.


































































