This document presents an overview of optimization algorithms on Riemannian manifolds. It begins by introducing concepts such as vector transport and retraction mappings that are used to generalize algorithms from Euclidean spaces to manifolds. It then summarizes several classical optimization methods including gradient descent, conjugate gradient, and variants of quasi-Newton methods adapted to the Riemannian setting using these geometric concepts. The convergence of the Fletcher-Reeves method is analyzed under standard assumptions on the objective function. Overall, the document provides a conceptual and mathematical foundation for optimization on manifolds.



![Rn
ηk
∇f, ∇2
f f
ηk := −∇f(xk).
ηk η ∈ Rn
∇2
f(xk)[η] = −∇f(xk)
⎧
⎪⎪⎨
⎪⎪⎩
η0 := −∇f(x0),
ηk+1 := −∇f(xk+1) + βk+1ηk, k ≥ 0.
βk
( ) 2016 3 10 5 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-6-320.jpg)









![f grad f(x)
M f x grad f(x) TxM
D f(x)[ξ] = gx(grad f(x), ξ), ξ ∈ TxM
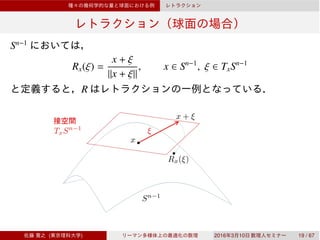
Sn−1
f(x) = xT
Ax A
f Rn ¯f
¯f(x) = xT
Ax, x ∈ Rn
.
¯f Rn
∇¯f(x) = 2Ax
ξ ∈ TxSn−1
Df(x)[ξ] = 2xT
Aξ = 2xT
A(In − xxT
)ξ = gx(2(In − xxT
)Ax, ξ)
grad f(x) = 2 In − xxT
Ax.
( ) 2016 3 10 17 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-18-320.jpg)
![R : TM → M
R [Absil et al., 2008]
2.1
R : TM → M R
Rx := R|TxM R TxM
Rx(0x) = x, ∀x ∈ M. 0x TxM
DRx(0x)[ξ] = ξ, ∀x ∈ M, ξ ∈ TxM.
x ∈ M, ξ ∈ TxM γ(t) = Rx(tξ)
γ(0) = Rx(0) = x γ(t) x
˙γ(0) = DRx(0)[ξ] = ξ γ(t) ξ
( ) 2016 3 10 18 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-19-320.jpg)

![Vector transport
Vector transport
M vector transport T TM ⊕ TM → TM
x ∈ M
[Absil et al., 2008]
1 R π(Tηx
(ξx)) = R(ηx).
π(Tηx
(ξx)) Tηx
(ξx)
2 T0x
(ξx) = ξx, ξx ∈ TxM.
3 Tηx
(aξx + bζx) = aTηx
(ξx) + bTηx
(ζx), a, b ∈ R.
vector transport
( ) 2016 3 10 22 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-23-320.jpg)
![Vector transport
Vector transport
M R
T R
ηx
(ξx) := DRx(ηx)[ξx]
T R
vector transport
T T R
( ) 2016 3 10 23 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-24-320.jpg)



![0 < c1 < c2 < 1
M xk ∈ M ηk
⟨grad f(xk), ηk⟩xk
< 0
f(Rxk
(αkηk)) ≤ f(xk) + c1αk⟨gradf(xk), ηk⟩xk
, (8)
⟨grad f(Rxk
(αkηk)), DRxk
(αkηk)[ηk]⟩xk
≥ c2⟨grad f(xk), ηk⟩xk
, (9)
|⟨grad f(Rxk
(αkηk)), DRxk
(αkηk)[ηk]⟩xk
| ≤ c2|⟨grad f(xk), ηk⟩xk
|. (10)
[Absil et al., 2008] (8)
[Sato, 2015] (8) (9)
[Ring & Wirth, 2012] (8) (10)
DRxk
(αkηk)[ηk] = T R
αkηk
(ηk)
( ) 2016 3 10 27 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-28-320.jpg)
![βk
Rn
βk
gk := ∇f(xk), yk := gk+1 − gk
βHS
k+1 =
gT
k+1yk
ηT
k yk
. [Hestenes & Stiefel, 1952]
βFR
k+1 =
∥gk+1∥2
∥gk∥2
. [Fletcher & Reeves, 1964]
βPRP
k+1 =
gT
k+1yk
∥gk∥2
. [Polak, Ribi`ere, Polyak, 1969]
βCD
k+1 =
∥gk+1∥2
−ηT
k gk
. [Fletcher, 1987]
βLS
k+1 =
gT
k+1yk
−ηT
k gk
. [Liu & Storey, 1991]
βDY
k+1 =
∥gk+1∥2
ηT
k yk
. [Dai & Yuan, 1999]
( ) 2016 3 10 28 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-29-320.jpg)

![Fletcher–Reeves
Scaled vector transport
Rn
vector transport T
∥Tαk−1ηk−1
(ηk−1)∥xk
≤ ∥ηk−1∥xk−1
Vector transport
Vector transport T R
scaled vector transport T 0
[Sato & Iwai, 2015]
T 0
η (ξ) =
∥ξ∥x
∥T R
η (ξ)∥Rx(η)
T R
η (ξ), ξ, η ∈ TxM.
( ) 2016 3 10 30 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-31-320.jpg)

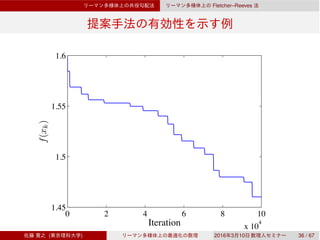
![Fletcher–Reeves
Fletcher–Reeves
3.1 (Sato & Iwai, 2015)
f C1
L > 0
|D(f ◦ Rx)(tη)[η] − D(f ◦ Rx)(0)[η]| ≤ Lt,
η ∈ TxM with ∥η∥x = 1, x ∈ M, t ≥ 0
3.2 {xk}
lim inf
k→∞
∥grad f(xk)∥xk
= 0
( ) 2016 3 10 32 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-33-320.jpg)
![Fletcher–Reeves
[Ring & Wirth, 2012]
k
∥T R
αk−1ηk−1
(ηk−1)∥xk
≤ ∥ηk−1∥xk−1
(11)
vector transport T R
[Sato & Iwai, 2015]
(11) (11) vector
transport scaled vector transport
( ) 2016 3 10 33 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-34-320.jpg)


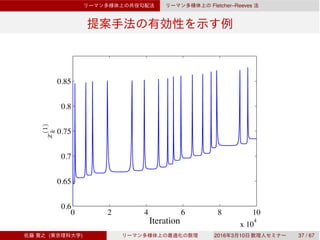
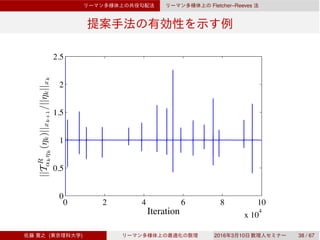
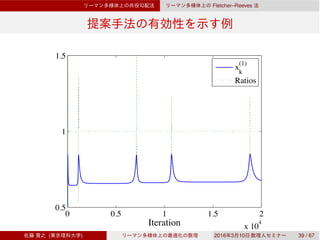
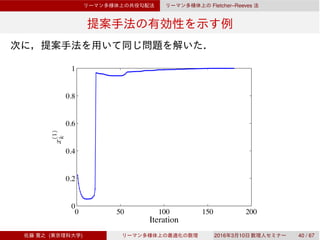
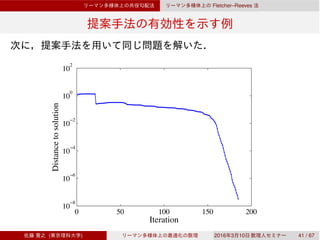


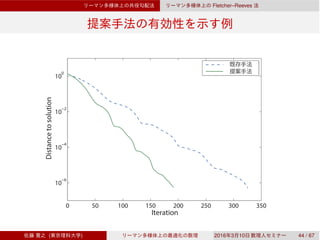
![Dai–Yuan
Rn
Dai–Yuan
3.3 Rn
Dai–Yuan [Dai & Yuan, 1999]
1: x0 ∈ Rn
2: η0 := − grad f(x0).
3: while grad f(xk) 0 do
4: αk xk+1 :=
xk + αkηk
5:
βk+1 =
∥gk+1∥2
ηT
k yk
, ηk+1 := − grad f(xk+1) + βk+1ηk
gk = grad f(xk), yk = gk+1 − gk.
6: k := k + 1.
7: end while
( ) 2016 3 10 45 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-46-320.jpg)




![Dai–Yuan
Dai–Yuan
3.3 (Sato, 2015)
f C1
L > 0
|D(f ◦ Rx)(tη)[η] − D(f ◦ Rx)(0)[η]| ≤ Lt,
η ∈ TxM with ∥η∥x = 1, x ∈ M, t ≥ 0
{xk}
lim inf
k→∞
∥grad f(xk)∥xk
= 0
( ) 2016 3 10 50 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-51-320.jpg)
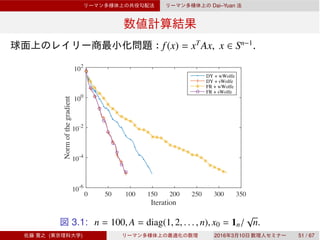
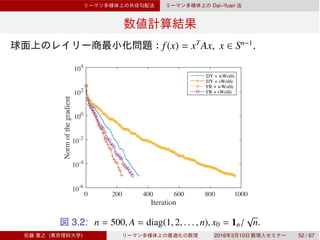
![Rn
βk
βPRP
k+1 =
g⊤
k+1yk
∥gk∥2
, βHS
k+1 =
g⊤
k+1yk
d⊤
k yk
, βLS
k+1 =
g⊤
k+1yk
−d⊤
k gk
,
βFR
k+1 =
∥gk+1∥2
∥gk∥2
, βDY
k+1 =
∥gk+1∥2
d⊤
k yk
, βCD
k+1 =
∥gk+1∥2
−d⊤
k gk
.
Rn
3
[Narushima et al., 2011]
η0 := −g0 k ≥ 0
ηk+1 :=
⎧
⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎩
−gk+1 if g⊤
k+1pk+1 = 0,
−gk+1 + βk+1ηk − βk+1
g⊤
k+1ηk
g⊤
k+1pk+1
pk+1 otherwise.
pk ∈ Rn
( ) 2016 3 10 54 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-55-320.jpg)
![[Sato & Iwai, 2013]
A ∈ Rm×n
, m ≥ n
p ≤ n N = diag(µ1, . . . , µp), µ1 > · · · > µp > 0
4.1
minimize − tr(UT
AVN),
subject to (U, V) ∈ St(p, m) × St(p, n).
(U∗, V∗) U∗, V∗
A p
2
( ) 2016 3 10 56 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-57-320.jpg)
![[Yger et al., 2012]
0 2 X ∈ RT×m
, Y ∈ RT×n
CX = XT
X, CY = YT
Y, CXY = XT
Y
u ∈ Rm
, v ∈ Rn
f = Xu, g = Yv
2 f g ρ
ρ =
Cov(f, g)
Var(f) Var(g)
=
uT
CXYv
√
uTCXu
√
vTCYv
.
ρ
4.2
maximize uT
CXYv,
subject to uT
CXu = vT
CYv = 1.
2
( ) 2016 3 10 57 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-58-320.jpg)
![[Yger et al., 2012]
u, v
4.3
maximize tr(UT
CXYV),
subject to (U, V) ∈ StCX
(p, m) × StCY
(p, n).
n G
StG(p, n)
StG(p, n) = {Y ∈ Rn×p
| YT
GY = Ip}
2
( ) 2016 3 10 58 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-59-320.jpg)
![[Sato & Sato, 2015]
˙x =Ax + Bu,
y =Cx.
u ∈ Rp
y ∈ Rq
x ∈ Rn
˙xm =Amxm + Bmu,
ym =Cmxm.
Am = UT
AU, Bm = UT
B, Cm = CU, U ∈ Rn×m
U
UT
U = Im
( ) 2016 3 10 59 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-60-320.jpg)
![[Sato & Sato, 2015]
4.4
minimize J(U),
subject to U ∈ St(m, n).
J
J(U) := ∥Ge∥2 = tr(CeEcCT
e ) = tr(BT
e EoBe)
Ae =
A 0
0 UT
AU
, Be =
B
UT
B
, Ce = C −CU Ec
Eo
AeEc + EcAT
e + BeBT
e =0, AT
e Eo + EoAe + CT
e Ce = 0.
( ) 2016 3 10 60 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-61-320.jpg)
![[Kasai & Mishra, 2015]
X∗
∈ Rn1×n2×n3
: 3
Ω ⊂ {(i1, i2, i3) | id ∈ {1, 2, . . . , nd}, d ∈ {1, 2, 3}}
X∗
i1i2i3
(i1, i2, i3) ∈ Ω
PΩ(X)(i1,i2,i3) =
⎧
⎪⎪⎨
⎪⎪⎩
Xi1i2i3
if (i1, i2, i3) ∈ Ω
0 otherwise
r = (r1, r2, r3)
4.5
minimize
1
|Ω|
∥PΩ(X) − PΩ(X∗
)∥2
F,
subject to X ∈ Rn1×n2×n3
, rank(X) = r.
( ) 2016 3 10 61 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-62-320.jpg)
![[Kasai & Mishra, 2015]
X ∈ Rn1×n2×n3
r
X = G×1U1×2U2×3U3, G ∈ Rr1×r2×r3
, Ud ∈ St(rd, nd), d = 1, 2, 3.
→ M := St(r1, n1) × St(r2, n2) × St(r3, n3) × Rr1×r2×r3
Od ∈ O(rd), d = 1, 2, 3
(U1, U2, U3, G) → (U1O1, U2O2, U3O3, G ×1 OT
1 ×2 OT
2 ×3 OT
3 )
X
M/(O(r1) × O(r2) × O(r3))
( ) 2016 3 10 62 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-63-320.jpg)
![[Yao et al., 2016]
1
DSIEP (Doubly Stochastic Inverse Eigenvalue Problem):
self-conjugate {λ1, λ2, . . . , λn}
n × n C
λ1, λ2, . . . , λn
λi
( ) 2016 3 10 63 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-64-320.jpg)
![[Yao et al., 2016]
Oblique OB := {Z ∈ Rn×n
| diag(ZZT
) = In}
Λ := diag(λ1, λ2, . . . , λn)
U:
1 Z ⊙ Z, Z ∈ OB
(Z ⊙ Z)T
1n − 1n = 0
Z ⊙ Z λ1, λ2, . . . , λn
Z ⊙ Z = Q(Λ + U)QT
, Q ∈ O(n), U ∈ U
( ) 2016 3 10 64 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-65-320.jpg)
![[Yao et al., 2016]
H1(Z, Q, U) := Z ⊙ Z − Q(Λ + U)QT
, H2(Z) := (Z ⊙ Z)T
1n − 1n
H(Z, Q, U) := (H1(Z, Q, U), H2(Z))
4.6
minimize h(Z, Q, U) :=
1
2
∥H(Z, Q, U)∥2
F,
subject to (Z, Q, U) ∈ OB × O(n) × U.
OB × O(n) × U
( ) 2016 3 10 65 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-66-320.jpg)



![I
[1] Absil, P.A., Mahony, R., Sepulchre, R.: Optimization
Algorithms on Matrix Manifolds. Princeton University Press,
Princeton, NJ (2008)
[2] Dai, Y.H., Yuan, Y.: A nonlinear conjugate gradient method
with a strong global convergence property. SIAM Journal
on Optimization 10(1), 177–182 (1999)
[3] Edelman, A., Arias, T.A., Smith, S.T.: The geometry of
algorithms with orthogonality constraints. SIAM Journal on
Matrix Analysis and Applications 20(2), 303–353 (1998)
[4] Fletcher, R., Reeves, C.M.: Function minimization by
conjugate gradients. The Computer Journal 7(2), 149–154
(1964)
( ) 2016 3 10 68 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-70-320.jpg)
![II
[5] Kasai, H., Mishra, B.: Riemannian preconditioning for
tensor completion. arXiv preprint arXiv:1506.02159v1
(2015)
[6] Narushima, Y., Yabe, H., Ford, J.A.: A three-term conjugate
gradient method with sufficient descent property for
unconstrained optimization. SIAM Journal on optimization
21(1), 212–230 (2011)
[7] Ring, W., Wirth, B.: Optimization methods on Riemannian
manifolds and their application to shape space. SIAM
Journal on Optimization 22(2), 596–627 (2012)
[8] Sato, H.: A Dai–Yuan-type Riemannian conjugate gradient
method with the weak Wolfe conditions. Computational
Optimization and Applications (2015)
( ) 2016 3 10 69 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-71-320.jpg)
![III
[9] Sato, H., Iwai, T.: A Riemannian optimization approach to
the matrix singular value decomposition. SIAM Journal on
Optimization 23(1), 188–212 (2013)
[10] Sato, H., Iwai, T.: A new, globally convergent Riemannian
conjugate gradient method. Optimization 64(4), 1011–1031
(2015)
[11] Sato, H., Sato, K.: Riemannian trust-region methods for H2
optimal model reduction. In: Proceedings of the 54th IEEE
Conference on Decision and Control, pp. 4648–4655
(2015)
[12] Tan, M., Tsang, I.W., Wang, L., Vandereycken, B., Pan,
S.J.: Riemannian pursuit for big matrix recovery. In:
Proceedings of the 31st International Conference on
Machine Learning, pp. 1539–1547 (2014)
( ) 2016 3 10 70 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-72-320.jpg)
![IV
[13] Yao, T.T., Bai, Z.J., Zhao, Z., Ching, W.K.: A Riemannian
Fletcher–Reeves conjugate gradient method for doubly
stochastic inverse eigenvalue problems. SIAM Journal on
Matrix Analysis and Applications 37(1), 215–234 (2016)
[14] Yger, F., Berar, M., Gasso, G., Rakotomamonjy, A.:
Adaptive canonical correlation analysis based on matrix
manifolds. In: Proceedings of the 29th International
Conference on Machine Learning (ICML-12), pp.
1071–1078 (2012)
( ) 2016 3 10 71 / 67](https://image.slidesharecdn.com/hiroyukisato-160528090708/85/Hiroyuki-Sato-73-320.jpg)
















































































