This document discusses the relationship between control as inference, reinforcement learning, and active inference. It provides an overview of key concepts such as Markov decision processes (MDPs), partially observable MDPs (POMDPs), optimality variables, the evidence lower bound (ELBO), variational inference, and the free energy principle as applied to active inference. Control as inference frames reinforcement learning as probabilistic inference by defining a generative process and performing variational inference to find an optimal policy. Active inference uses the free energy principle and minimizes expected free energy to select actions that resolve uncertainty.
![!
! control as inference active inference
!
!
!
! Christopher L Buckley
!
!
!
2
! On the Relationship Between Active Inference and Control as Inference [Millidge+ 20] Control as inference active inference
! Active inference: demystified and compared [Sajid+ 20] Active inference
! Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review [Levine 18] Control as inference
! Reinforcement Learning as Iterative and Amortised Inference [Millidge+ 20] Control as Inference amortized
! What does the free energy principle tell us about the brain? [Gershman 19] Active inference
! Hindsight Expectation Maximization for Goal-conditioned Reinforcement Learning [Tang+ 20] Control as inference Variational RL](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-2-320.jpg)
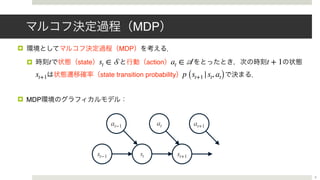

![! MDP policy
! trajectory
!
! reward
!
p (a|s)
T τ = (s1, a1, . . . , sT, aT)
r (st, at)
𝔼p(τ)
[
T
∑
t=1
r (st, at)
]
popt (a|s)
5
p(τ) = p(s1:T, a1:T) =
T
∏
t=1
p(at |st)p(st |st−1, at−1)](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-5-320.jpg)
![! plan
!
! Active inference
!
!
!
π = [a1, . . . , aT]
T τ = (s1:T, π)
π
6
p(τ) = p(π)p(s1:T |π) = p(π)
T
∏
t=1
p(st |st−1, π)](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-6-320.jpg)




![!
!
!
!
p (τ| 𝒪1:T) ∝ p ( 𝒪1:T |τ) p (τ)
𝒪1:T
τ
q(τ)
q(τ)
11
̂q = arg min
q
DKL [q(τ)∥p (τ| 𝒪1:T)]
τ
𝒪1:t
p (τ| 𝒪1:T) ≈ q(τ)
p (τ)
p ( 𝒪1:T |τ)](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-11-320.jpg)
![ELBO
! ELBO
! ELBO
! ELBO
!
q(τ) p(τ)
12
log p ( 𝒪1:T) = log
∫
p ( 𝒪1:T, τ) dτ
= log 𝔼q(τ)
[
p ( 𝒪1:T, τ)
q (τ) ]
≥ 𝔼q(τ) [log p ( 𝒪1:T |τ) + log p (τ) − log q (τ)]
= 𝔼q(τ)
[
T
∑
t=1
r (st, at)
]
− DKL [q(τ)∥p(τ)] =: L(q)
τ
𝒪1:t
p (τ| 𝒪1:T) ≈ q(τ)
p (τ)
p ( 𝒪1:T |τ)](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-12-320.jpg)

![1.
! ELBO
!
!
14
L(ϕ) = 𝔼qϕ(τ)
[
T
∑
t=1
r (st, at)
]
− DKL [qϕ(τ)∥p(τ)]
≥ 𝔼qϕ(τ)
[
T
∑
t=1
r (st, at) − log qϕ(at |st)
]
= 𝔼qϕ(τ)
[
T
∑
t=1
r (st, at) + ℋ (qϕ(at |st))]
J(ϕ) := 𝔼qϕ(τ)
[
T
∑
t=1
r (st, at) + ℋ (qϕ(at |st))]](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-14-320.jpg)
![Soft Actor-Critic
! Soft Actor-Critic SAC [Haarnoja+ 17, 18]
! ELBO off-policy .
! Q
! Q critic actor
!
! Control as Inference https://deeplearning.jp/reinforcement_cource-2020s/
! Control as Inference https://www.slideshare.net/DeepLearningJP2016/dlcontrol-as-inference-201266247
Qθ (st, at) = r(st, at) + 𝔼p(st+1|st,at) [V(st+1)]
Qθ (st, at) qϕ(at |st)
15
Jq
t (ϕ) = 𝔼qϕ(at|st)p(st) [
log (qϕ (at |st)) − Qθ (st, at)]
JQ
t (θ) = 𝔼qϕ(at|st)p(st)
[(
r (st, at) + 𝔼p(st+1|st,at) [V¯θ (st+1)] − Qθ (st, at))
2
]
Vθ(st+1) = 𝔼qϕ(at+1|st+1) [Qθ(st+1, at+1) − log qϕ(at+1 |st+1)]
Q](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-15-320.jpg)
![POMDP
! Control as inference POMDP
! VAE
16
! SLAC[Lee+ 19]
! RNN
!
! [Han+ 19]
! RNN VRNN[Chung+ 16]
! variational recurrent model VRMat](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-16-320.jpg)
![CAI
! CAI
! Mirror descent [Bubeck, 14]
=> Variational Inference Model Predictive Control VI-MPC [Okada+ 19]
!
π
𝒲(π) = 𝔼q(τ)[p(𝒪1:T |τ)]
p(𝒪1:T |τ) := f(r(τ))
17
q(i+1)
(π) ←
q(i)
(π) ⋅ 𝒲 (π) ⋅ q(i)
(π)
𝔼q(i)(π) [ 𝒲 (π) ⋅ q(i) (π)]
[Okada+ 19]](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-17-320.jpg)
![Control as inference
! CAI
! SAC VI-MPC
! amortized [Kingma+ 13]
! [Millidge+ 20]
! amortized
18](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-18-320.jpg)
![2.
! CAI
! ELBO
! ELBO
!
=> Variational RL
p (at ∣ st)
q θ
19
pθ(τ) :=
T
∏
t=1
pθ (at ∣ st) p (st ∣ st−1, at−1)
L(θ, q) = 𝔼q(τ)
[
T
∑
t=1
r (st, at)
]
− DKL [q(τ)∥pθ(τ)]](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-19-320.jpg)
![EM
! E
!
! M
! E ELBO
!
! MPO[Abdolmaleki+ 18] V-MPO[Song+ 19]
! M E
θ θ = θold
θ
θ
20
̂θ = max
θ
𝔼q(τ)[log pθ(τ)] = max
θ
𝔼q(τ)
[
T
∑
t=1
log pθ (at ∣ st)
]
q(τ) = pθold (τ| 𝒪1:T) =
p ( 𝒪1:T ∣ τ) pθold
(τ)
∑τ
p ( 𝒪1:T ∣ τ) pθold
(τ)](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-20-320.jpg)
![MPO E
! Maximum a posteriori Policy Optimization MPO [Abdolmaleki+ 18]
!
! E Q
! Q off-policy
! MPO DL
! https://www.slideshare.net/DeepLearningJP2016/dlhyper-parameter-agnostic-methods-in-reinforcement-learning
θold pθold
(at ∣ st) ̂Qθold
(st, at)
21
q(τ) =
T
∏
t=1
q (at ∣ st) p (st ∣ st−1, at−1)
q(at |st) ∝ pθold
(at ∣ st)exp
̂Qθold
(st, at)
η
η > 0](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-21-320.jpg)





![!
!
! Bayesian surprise
! active learning
!
!
a o a
u(o) = DKL[p(s ∣ o, a)||p(s ∣ a)] I(a)
a
I(a) a s o
I(a)
27
I(a) :=
∑
o
p(o ∣ a)DKL[p(s ∣ o, a)||p(s ∣ a)] = 𝔼p(o∣a)[u(o)]](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-27-320.jpg)
![!
.
!
!
o1:T π = [a1, . . . , aT]
U(o1:T) =
T
∑
t=1
u (ot)
28
I(π) = 𝔼p(o1:T∣π) [U(o1:T)] =
∑
o1:T
p(o1:T ∣ π)U(o1:T)](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-28-320.jpg)
![!
! ELBO
! ELBO variational free energy
! free energy principle
!
!
q(s)
−log p(o)
29
log p(o) ≥ 𝔼q(s) [
log
p(o, s)
q(s) ]
F(o, q) := − 𝔼q(s) [
log
p(o, s)
q(s) ]](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-29-320.jpg)
![!
!
!
! 1
!
!
! 2
o
−log p(o)
q
q(s)
30
F(o, q) = − log p(o) + DKL[q(s)||p(s|o)]](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-30-320.jpg)
![! POMDP
!
!
!
!
π = [a1, . . . , aT]
31
p(o1:T, s1:T |π) =
T
∏
t=1
p(ot |st)p(st |st−1, π)
q(s1:T |π) =
T
∏
t=1
q(st |π)
F(o1:T, π) = − 𝔼q(s1:T|π)
[
log
p(o1:T, s1:T |π)
q(s1:T |π) ]
st−1 st st+1
at−1 at at+1
ot−1 ot ot+1
π](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-31-320.jpg)
![!
! expected free energy
32
G(π):= 𝔼p(o1:T ∣ s1:T, π) [F (o1:T, π)]
= − 𝔼p(o1:T ∣ s1:T, π)
𝔼q(s1:T |π)
[
log
p (o1:T, s1:T |π)
q (s1:T |π) ]
= − 𝔼q(o1:T, s1:T |π)
[
log
p (o1:T, s1:T |π)
q (s1:T |π) ]](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-32-320.jpg)
![Active inference
!
! active inference AIF
t Gt
q(st |ot, π) ≈ p(st |ot, π)
33
Gt(π) = − 𝔼q(ot, st ∣ π)
[
log
p (ot, st ∣ π)
q (st ∣ π) ]
≈ − 𝔼q(ot, st ∣ π)
[
log
p (ot |π) q (st ∣ ot, π)
q (st ∣ π) ]
= − 𝔼q(ot, st ∣ π) [log p (ot ∣ π)] − 𝔼q(ot ∣ π) [
DKL [q (st ∣ ot, π)||q (st ∣ π)]]](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-33-320.jpg)
![Active inference
!
! 1
!
! active inference
!
! 1 0
q = p
34
Gt(π) = − 𝔼q(ot, st ∣ π) [log p (ot ∣ π)] − 𝔼q(ot ∣ π) [
DKL [q (st ∣ ot, π)||q (st ∣ π)]]
= − 𝔼p(ot, st ∣ π) [log p (ot ∣ π)] − 𝔼p(ot ∣ π) [
DKL [p (st ∣ ot, π)||p (st ∣ π)]]
= 𝔼p(st ∣ π) [
ℋ (p (ot ∣ π))]
− I(π) ※ p(st |st−1, π) p(st |π)](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-34-320.jpg)
![Active inference
!
! 1
!
! extrinsic value
! 2
! bayesian surprise
! intrinsic value
=>
35
−Gt(π) = 𝔼q(ot,st|π) [log p(ot |π)] + 𝔼q(ot|π) [DKL[q(st |ot, π)||q(st |π)]]](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-35-320.jpg)
![Active inference
!
!
!
!
!
[Gershman+ 19]
!
36
˜p(o1:T) = exp(r(o1:T))
※ ˜p](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-36-320.jpg)

![active inference
! Active inference AIF [Millidge+ 20]
!
!
! t −Gt(ϕ)
38
˜p (st, ot, at) = p(st |ot, at)p(at |st)˜p(ot |at) ≈ q(st |ot, at)p(at |st)˜p(ot |at)
qϕ(st, at) = qϕ (at ∣ st) q(st)
−Gt(ϕ) = 𝔼qϕ(ot, st, at)
[
log
˜p (st, ot, at)
qϕ (st, at) ]
≈ 𝔼qϕ(ot, st, at) [log ˜p (ot |at) + log p (at |st) + log q(st |ot, at) − log qϕ (at |st) − log q(st)]
= 𝔼qϕ(ot, st, at) [log ˜p (ot |at)] − 𝔼qϕ(ot, st, at)
[log qϕ (at |st) − log p(at |st)] + 𝔼qϕ(ot, st, at) [log q(st |ot, at) − log q(st)]
≈ 𝔼q(ot ∣ at) [log ˜p (ot ∣ at)] − 𝔼q(st) [
DKL (qϕ (at ∣ st) ∥p (at ∣ st))]
+ 𝔼q(ot, at ∣ st) [
DKL (q (st ∣ ot, at) ∥q (st ∣ at))]
= 𝔼q(ot ∣ at) [log ˜p (ot ∣ at)] + 𝔼q(st) [
ℋ (qϕ (at ∣ st))]
+ 𝔼q(ot, at ∣ st) [
DKL (q (st ∣ ot, at) ∥q (st ∣ at))]
p (at ∣ st) =
1
| 𝒜|](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-38-320.jpg)
![AIF CAI
! CAI
! AIF
! 1
! 2
! AIF
! AIF 3
! CAI AIF
!
39
𝔼q(st,at) [log p ( 𝒪t |st, at)] + 𝔼q(st) [
ℋ (qϕ(at |st))]
𝔼q(ot ∣ at) [log ˜p (ot ∣ at)] + 𝔼q(st) [
ℋ (qϕ (at ∣ st))]
+ 𝔼q(ot, at ∣ st) [
DKL (q (st ∣ ot, at) ∥q (st ∣ at))]](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-39-320.jpg)
![Likelihood-AIF
! AIF CAI Likelihood-AIF
!
! CAI
˜p(ot) ˜p(ot |st)
−Gt
q(st) = p(st) p (at ∣ st) =
1
| 𝒜|
40
−Gt(ϕ) = 𝔼qϕ(ot, st, at)
[
log
˜p (st, ot, at)
qϕ (st, at) ]
= 𝔼qϕ(ot, st, at) [log ˜p (ot ∣ st) + log p (st) + log p (at ∣ st) − log qϕ (at ∣ st) − log q (st)]
= 𝔼qϕ(st, at) [log ˜p (ot ∣ st)] − DKL (q (st)||p (st)) − 𝔼q(st) [
DKL (qϕ (at ∣ st)||p (at ∣ st))]
−Gt(ϕ) = 𝔼qϕ(st, at) [log ˜p (ot |st)] + 𝔼q(st) [
ℋ (qϕ (at ∣ st))]](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-40-320.jpg)
![Likelihood-AIF CAI
! CAI
! Likelihood-AIF
! 2
! AIF POMDP MDP CAI 1
! CAI
! 2
log ˜p (ot ∣ st) = log p ( 𝒪t |st, at)
41
𝔼qϕ(st,at) [log p ( 𝒪t |st, at)] + 𝔼q(st) [
ℋ (qϕ(at |st))]
𝔼qϕ(st, at) [log ˜p (ot |st)] + 𝔼q(st) [
ℋ (qϕ (at ∣ st))]](https://image.slidesharecdn.com/probablisticinferenceandactionselection-201111102932/85/slide-41-320.jpg)



![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DL輪読会]World Models](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180427003856-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]深層強化学習はなぜ難しいのか?Why Deep RL fails? A brief survey of recent works.](https://cdn.slidesharecdn.com/ss_thumbnails/20210115dlohta-210115054939-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Weakly-Supervised Disentanglement Without Compromises](https://cdn.slidesharecdn.com/ss_thumbnails/20200619akuzawa-200630053016-thumbnail.jpg?width=640&height=640&fit=bounds)






















































