Downloaded 16 times














![• The score for this sequence can be computed as
The joint probability for our unknown sequence is therefore
P(A,B,A,Red,Green,Red) =
[P(y_0=A) P(x_0=Red/y_0=A)] [P(y_1=B|y_0=A|)
P(x_1=Green/y_1=B)] [P(y_2=A|y_1=B) P(x_2=Red/y_2=A)]
=(1∗1)∗(1∗0.75)∗(1∗1)(1)(1)=(1∗1)∗(1∗0.75)∗(1∗1)
=0.75(2)(2)=0.75](https://image.slidesharecdn.com/hiddenmarkovmodel-190603011314/85/Hidden-markov-model-16-320.jpg)

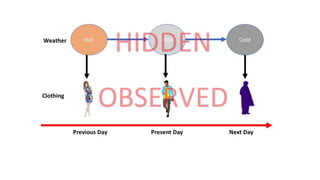
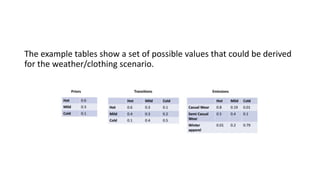
Hidden Markov models (HMMs) are probabilistic graphical models that allow prediction of a sequence of hidden states from observed variables. HMMs make the Markov assumption that the next state depends only on the current state, not past states. They require specification of transition probabilities between hidden states, emission probabilities of observations given states, and initial state probabilities to compute the joint probability of state sequences given observations. The most probable hidden state sequence, determined from these probabilities, is taken as the best inference.






















































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)
















