Download as PDF, PPTX





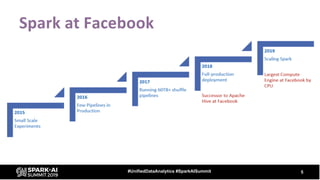
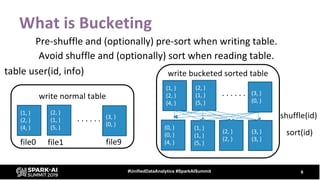

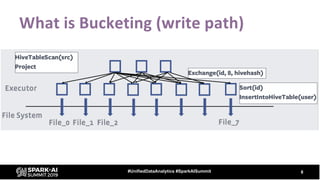
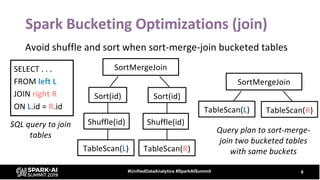
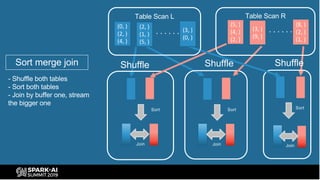
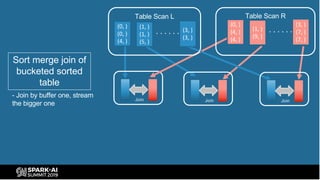
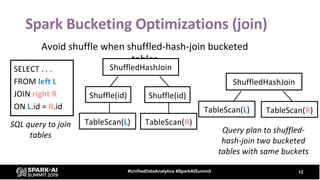
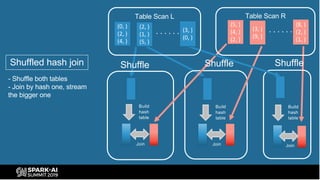
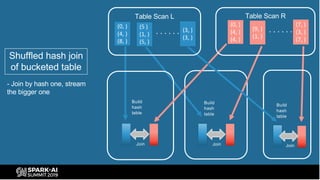

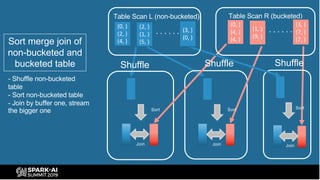

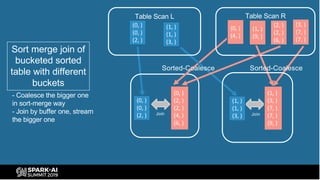

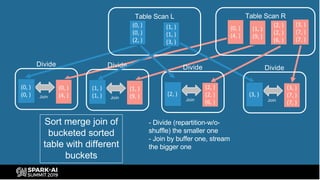

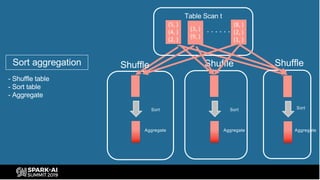
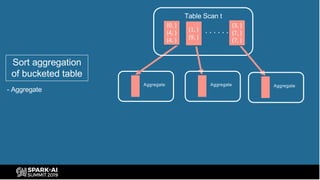
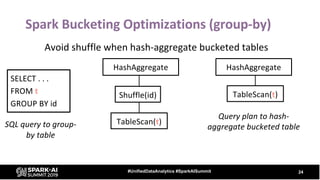
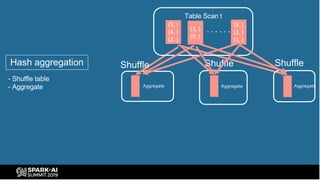
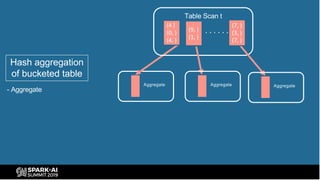
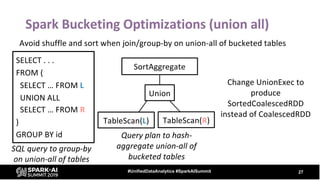
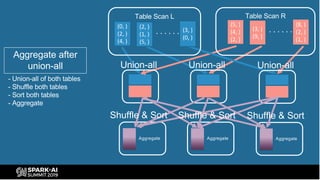
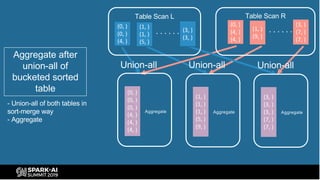

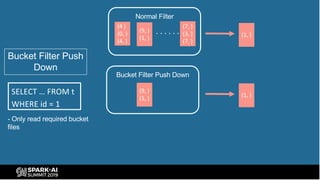
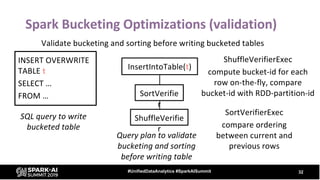
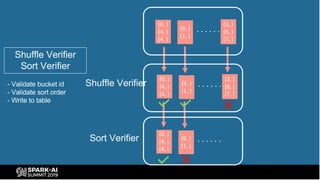






The document provides an overview of bucketing in Spark, as presented by Cheng Su from Facebook at the AI Summit. It covers the concept of bucketing, optimization strategies for Spark bucketing when performing joins and aggregations, and future directions for bucketing compatibility across SQL engines. The agenda includes practical examples and recommendations for effective bucketing implementation.















































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)







