Downloaded 87 times


![Ewan Higgs
• Software Architect at Western Digital
– Focused on Hadoop Integration
• HDFS Contributions
– Protocol level changes to the Block Token Identifier (HDFS-11026, HDFS-6708, HDFS-9807)
– Provided Storage (HDFS-9806)
• [F]OSS work
– Contributed to: HDFS, Hue, hanythingondemand, …
– My own work: Spark Terasort, spark-config-gen, csv-game
– Co-organized: FOSDEM HPC, Big Data, and Data Science Devroom (201{6,7})](https://image.slidesharecdn.com/april51700wetserndigitaldemoorhiggs-170410123742/75/HDFS-Tiered-Storage-Mounting-Object-Stores-in-HDFS-3-2048.jpg)
![Resources
• Tiered Storage HDFS-9806 [issues.apache.org]
– Design documentation
– List of subtasks, lots of linked tickets – take one!
– Discussion of scope, implementation, and feedback
• Joint work Microsoft – Western Digital
– {thomas.demoor, ewan.higgs}@wdc.om
– {cdoug,vijala}@microsoft.com](https://image.slidesharecdn.com/april51700wetserndigitaldemoorhiggs-170410123742/75/HDFS-Tiered-Storage-Mounting-Object-Stores-in-HDFS-4-2048.jpg)





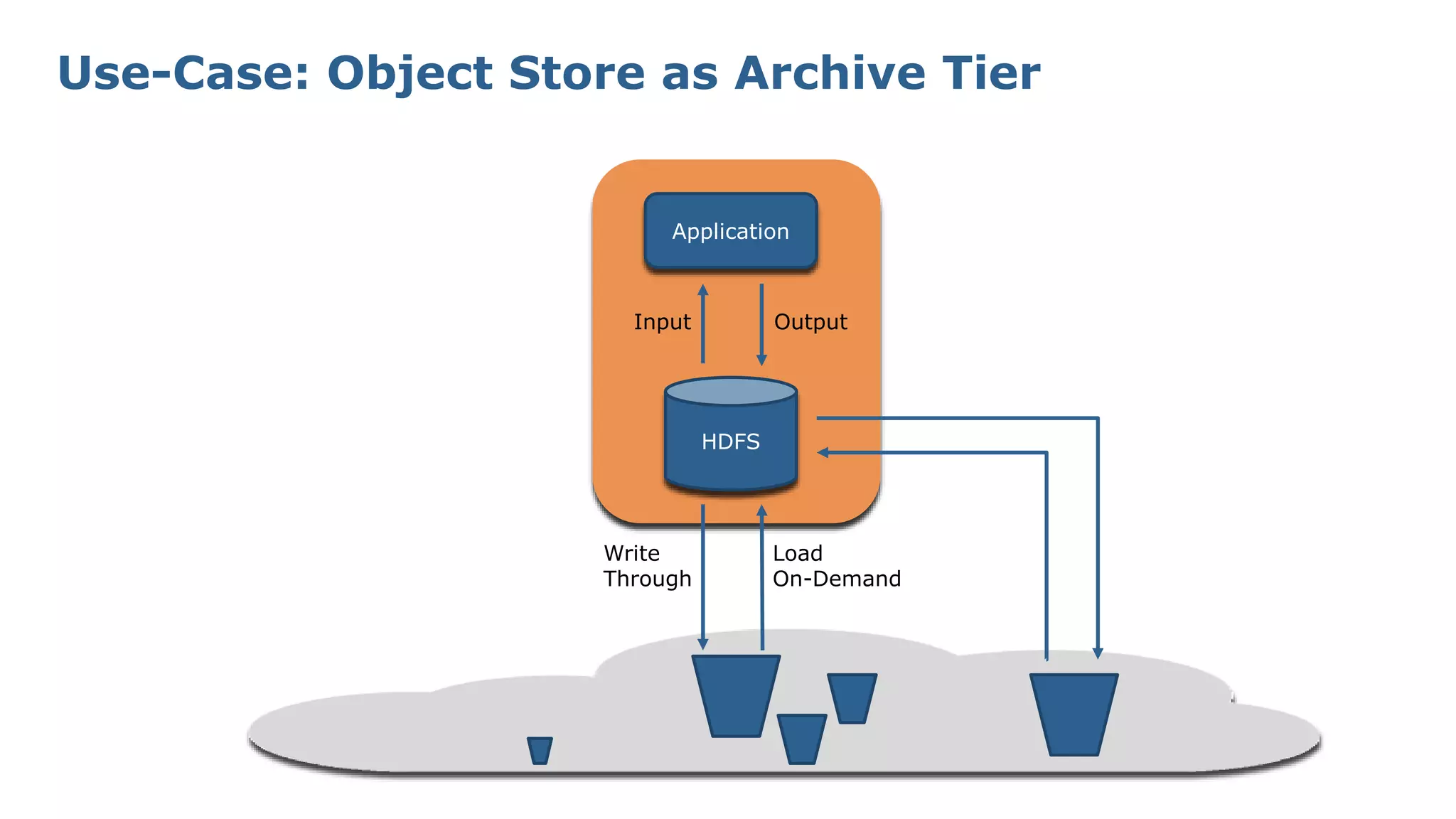



![• Low utilization on clusters running latency-sensitive applications
– Seen at Microsoft (Zhang et. al. [OSDI’16]) and Google (Lo et. al. [ACM TOCS’16])
– Remedy: Co-locate analytics cluster on same hardware, as secondary tenant
• To handle scale (10,000s machines), run multiple HDFS Namenodes in federation
– Related: Router-based HDFS federation (HDFS-10467)
• Require Quality of Service for latency-sensitive application
– Preempt machines running analytics
– E.g., Update the search index kill 1000 nodes of analytics cluster
– Possibility of rapid changes in load on Namenodes => entails re-balancing between Namenodes
• During rebalancing, use tiering to “mount” source sub-tree in the destination
Namenode
– Metadata operation, much faster than moving data (Alt.: run a distcp job, as proposed in HDFS-10467)
– Can lazily copy data to destination NN
– Data available even before the copying is complete
Use-Case: Harvesting spare cycles in datacenters](https://image.slidesharecdn.com/april51700wetserndigitaldemoorhiggs-170410123742/75/HDFS-Tiered-Storage-Mounting-Object-Stores-in-HDFS-14-2048.jpg)





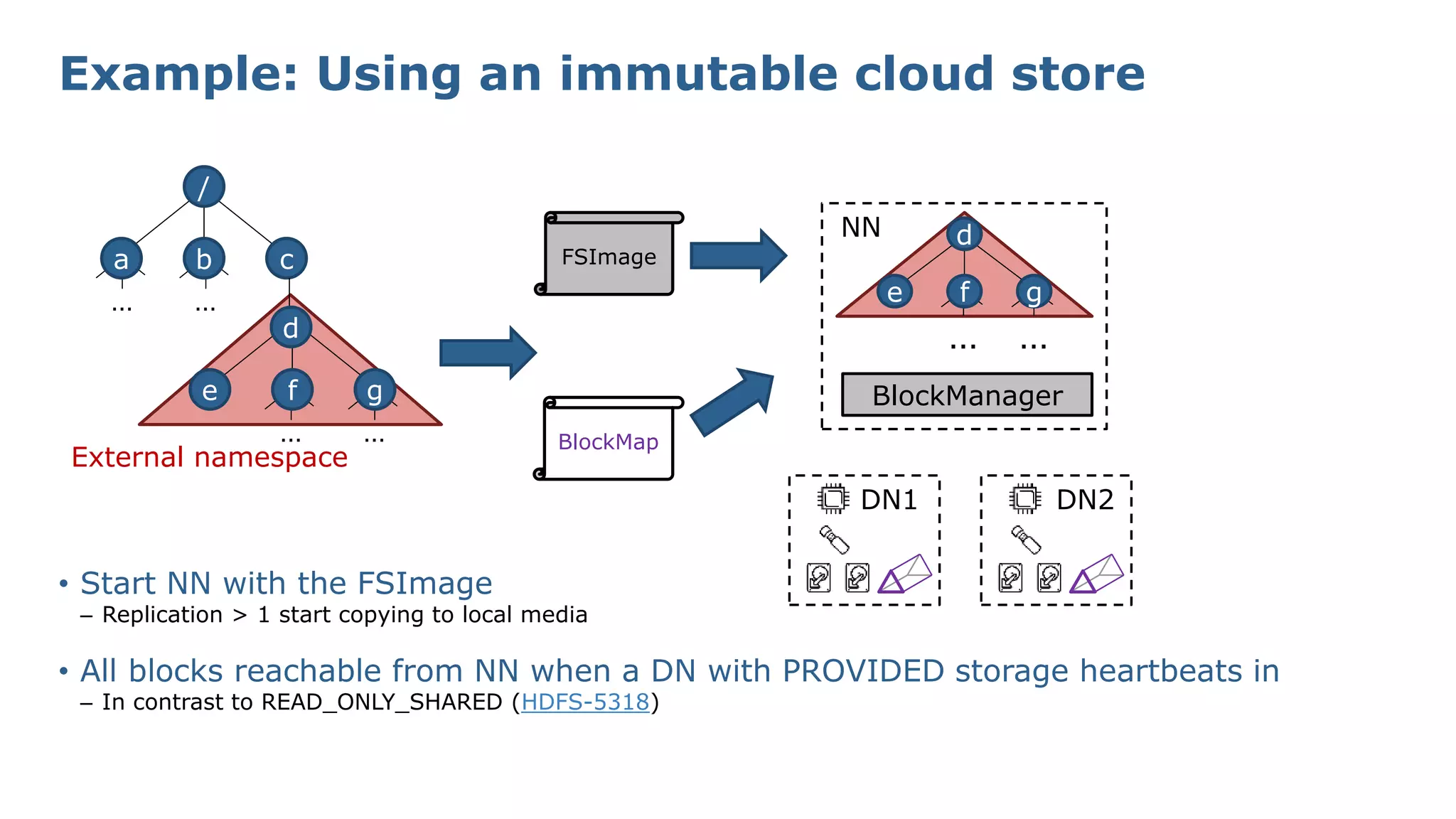
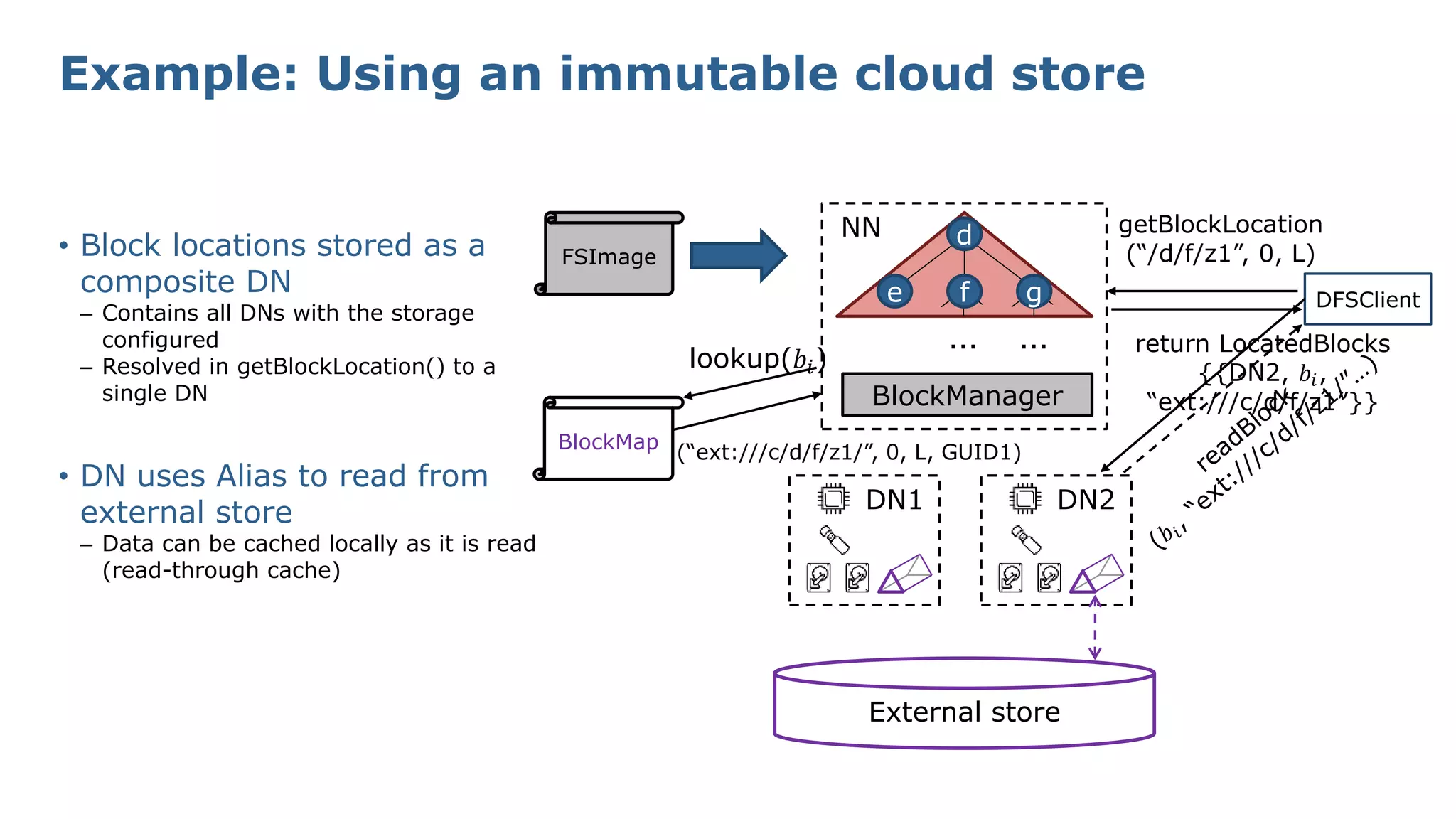





![Resources + Q&A
• Tiered Storage HDFS-9806 [issues.apache.org]
– Design documentation
– List of subtasks, lots of linked tickets – take one!
– Discussion of scope, implementation, and feedback
• Joint work Microsoft – Western Digital
– {thomas.demoor, ewan.higgs}@wdc.om
– {cdoug,vijala}@microsoft.com](https://image.slidesharecdn.com/april51700wetserndigitaldemoorhiggs-170410123742/75/HDFS-Tiered-Storage-Mounting-Object-Stores-in-HDFS-27-2048.jpg)



The document discusses HDFS tiered storage and the integration of object stores such as Amazon S3 within the HDFS ecosystem, emphasizing improved handling of external storage without explicit data copying. Key features include the ability to mount various Hadoop-compatible filesystems, manage multiple clusters effectively, and maintain a unified namespace with transparent caching. The presentation outlines existing contributions, challenges faced with metadata synchronization, and future developments in write paths and dynamic mounting strategies.























































































