Download to read offline




































![Put
•
•
•
•
Put(byte[] row)
Put(byte[] row, RowLock rowLock)
Put(byte[] row, long ts)
Put(byte[] row, long ts, RowLock rowLock)
46](https://image.slidesharecdn.com/09-hbase-131030021932-phpapp01/85/HBase-46-320.jpg)
![Put
•
Put add(byte[] family, byte[] qualifier, byte[]
value)
•
Put add(byte[] family, byte[] qualifier, long
ts, byte[] value)
•
Put add(KeyValue kv)
47](https://image.slidesharecdn.com/09-hbase-131030021932-phpapp01/85/HBase-47-320.jpg)


![What else
•
CAS:
boolean checkAndPut(byte[] row, byte[] family,
•
byte[] qualifier, byte[] value, Put put) throws IOException
Batch:
void put(List<Put> puts) throws IOException
51](https://image.slidesharecdn.com/09-hbase-131030021932-phpapp01/85/HBase-51-320.jpg)

![Row lock
•
•
Region server provide a row lock
Client can ask for explicit lock:
RowLock lockRow(byte[] row) throws IOException;
void unlockRow(RowLock rl) throws IOException;
•
Do not use if you do not have to
53](https://image.slidesharecdn.com/09-hbase-131030021932-phpapp01/85/HBase-53-320.jpg)



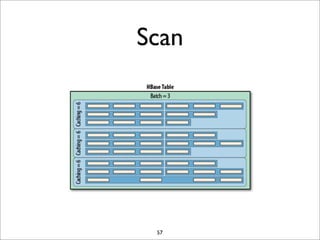






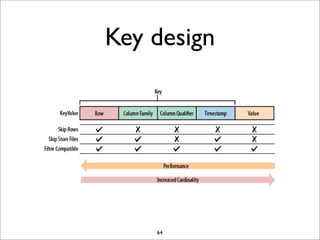









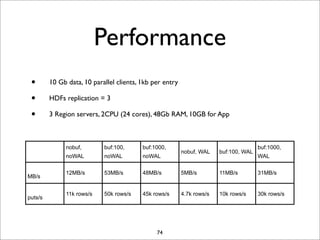



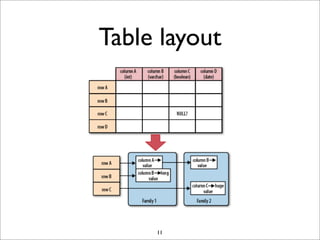
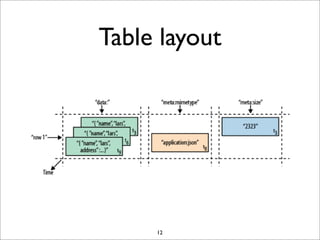
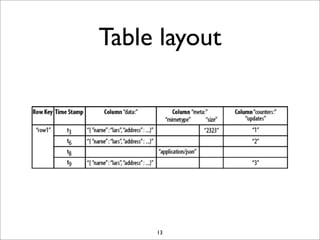
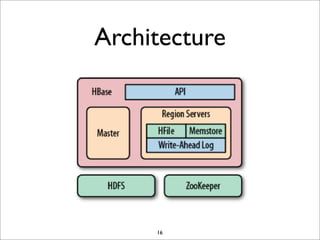
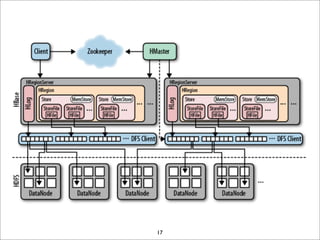
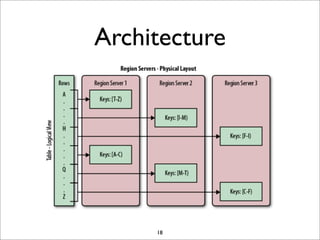
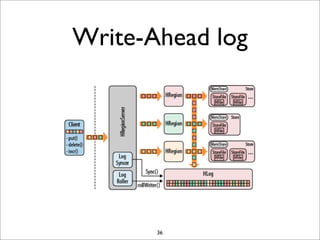
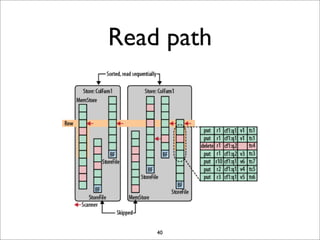
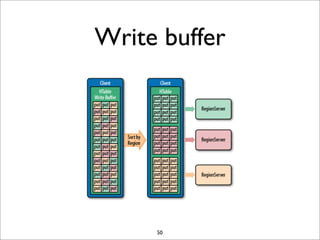
HBase is a distributed, column-oriented database that runs on top of HDFS. It provides random real-time read/write access to big data. HBase tables are sharded into regions distributed across region servers. The master server manages the cluster and schema changes. Clients communicate with the master and region servers to read and write data. Keys are sorted and data is stored in columns within column families.












![[db tech showcase Tokyo 2017] A11: SQLite - The most used yet least appreciat...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-keynote-20170905-170911071000-thumbnail.jpg?width=640&height=640&fit=bounds)




























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)









