Download to read offline









![Примеры
API
Basic
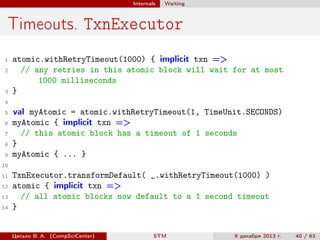
1
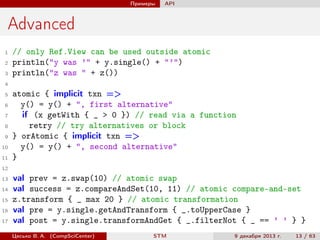
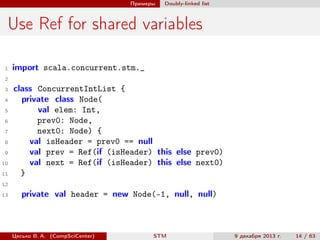
import scala.concurrent.stm._
2
3
4
5
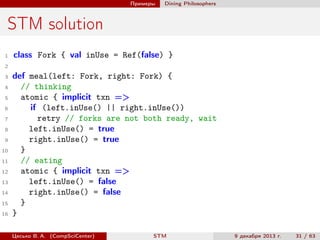
val x = Ref(0) // allocate a Ref[Int]
val y = Ref.make[String]() // type-specific default
val z = x.single // Ref.View[Int]
6
7
8
9
10
11
12
13
14
15
16
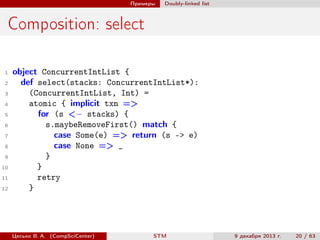
atomic { implicit txn =>
val i = x() // read
y() = "x was " + i // write
val eq = atomic { implicit txn => // nested atomic
// both Ref and Ref.View can be used inside atomic
x() == z()
}
assert(eq)
y.set(y.get + ", long-form access")
}
Цесько В. А. (CompSciCenter)
STM
9 декабря 2013 г.
12 / 63](https://image.slidesharecdn.com/13-stm-131209130435-phpapp01/85/Software-Transactional-Memory-12-320.jpg)

![Примеры
Doubly-linked list
Wait for multiple events
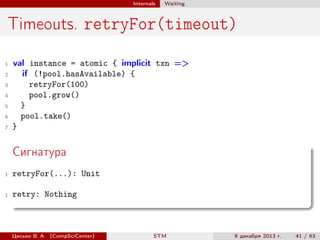
1
2
3
4
5
6
7
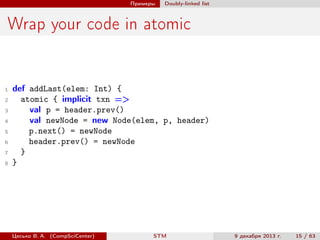
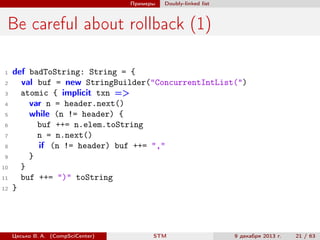
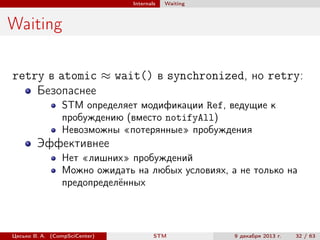
def maybeRemoveFirst(): Option[Int] = {
atomic { implicit txn =>
Some(removeFirst())
} orAtomic { implicit txn =>
None
}
}
Цесько В. А. (CompSciCenter)
STM
9 декабря 2013 г.
19 / 63](https://image.slidesharecdn.com/13-stm-131209130435-phpapp01/85/Software-Transactional-Memory-19-320.jpg)

![Примеры
Indexed Map
API
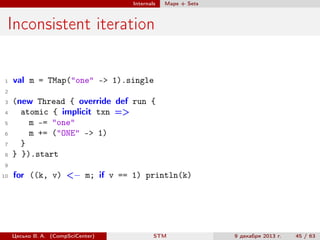
1
2
3
4
5
6
7
8
9
10
11
12
13
14
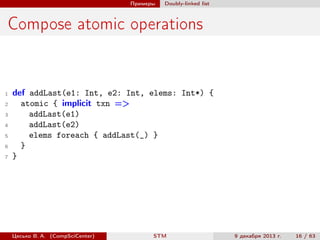
scala> case class User(id: Int, name: String, likes: Set[String])
scala> val m = new IndexedMap[Int, User]
scala> m.put(10, User(10, "alice", Set("scala", "climbing")))
res0: Option[User] = None
scala> val byName = m.addIndex { (id,u) => Some(u.name) }
byName: (String) => Map[Int,User] = <function1>
scala> val byLike = m.addIndex { (id,u) => u.likes }
byLike: (String) => Map[Int,User] = <function1>
scala> m.put(11, User(11, "bob", Set("scala", "skiing")))
res1: Option[User] = None
scala> byName("alice")
res2: Map[Int,User] = Map((10,User(10,alice,Set(scala,
climbing))))
scala> byLike("scala").values map { _.name }
res3: Iterable[String] = List(alice, bob)
Цесько В. А. (CompSciCenter)
STM
9 декабря 2013 г.
24 / 63](https://image.slidesharecdn.com/13-stm-131209130435-phpapp01/85/Software-Transactional-Memory-24-320.jpg)
![Примеры
Indexed Map
A high-level sketch
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
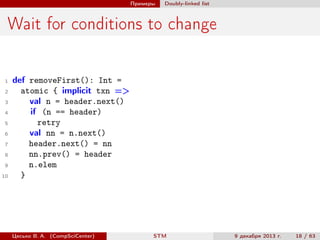
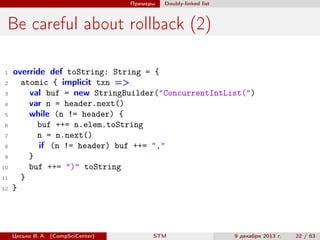
import scala.concurrent.stm._
class IndexedMap[A, B] {
private val contents = TMap.empty[A, B]
// TODO def addIndex(view: ?): ?
def get(key: A): Option[B] = contents.single.get(key)
def put(key: A, value: B): Option[B] =
atomic { implicit txn =>
val prev = contents.put(key, value)
// TODO: update indices
prev
}
def remove(key: A): Option[B] =
atomic { implicit txn =>
val prev = contents.remove(key)
// TODO: update indices
prev
}
}
Цесько В. А. (CompSciCenter)
STM
9 декабря 2013 г.
25 / 63](https://image.slidesharecdn.com/13-stm-131209130435-phpapp01/85/Software-Transactional-Memory-25-320.jpg)
![Примеры
Indexed Map
Types for the view function and index
Помедитируем:
1
2
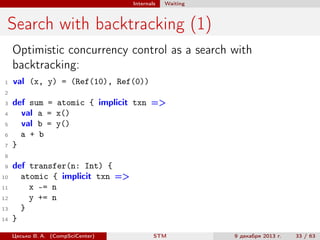
def addIndex(view: ((A, B) => Iterable[C])):
(C => Map[A, B]) = ...
Цесько В. А. (CompSciCenter)
STM
9 декабря 2013 г.
26 / 63](https://image.slidesharecdn.com/13-stm-131209130435-phpapp01/85/Software-Transactional-Memory-26-320.jpg)
 => Iterable[C])
extends (C => Map[A, B]) {
def += (kv: (A, B)) // TODO
def -= (kv: (A, B)) // TODO
}
6
7
private val indices = Ref(List.empty[Index[_]])
8
9
10
11
12
13
14
15
16
def addIndex[C](view: (A, B) => Iterable[C]):
(C => Map[A, B]) =
atomic { implicit txn =>
val index = new Index(view)
indices() = index :: indices()
contents foreach { index += _ }
index
}
Цесько В. А. (CompSciCenter)
STM
9 декабря 2013 г.
27 / 63](https://image.slidesharecdn.com/13-stm-131209130435-phpapp01/85/Software-Transactional-Memory-27-320.jpg)
![Примеры
Indexed Map
Tracking and updating indices (2)
1
2
3
4
5
6
7
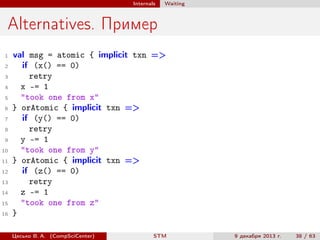
def put(key: A, value: B): Option[B] =
atomic { implicit txn =>
val prev = contents.put(key, value)
for (p <− prev; i <− indices()) i -= (key -> p)
for (i <− indices()) i += (key -> value)
prev
}
8
9
10
11
12
13
14
def remove(key: A): Option[B] =
atomic { implicit txn =>
val prev = contents.remove(key)
for (p <− prev; i <− indices()) i -= (key -> p)
prev
}
Цесько В. А. (CompSciCenter)
STM
9 декабря 2013 г.
28 / 63](https://image.slidesharecdn.com/13-stm-131209130435-phpapp01/85/Software-Transactional-Memory-28-320.jpg)
 => Iterable[C])
extends (C => Map[A, B]) {
val mapping = TMap.empty[C, Map[A, B]]
def apply(derived: C) =
mapping.single.getOrElse(derived, Map.empty[A, B])
def += (kv: (A, B))(implicit txn: InTxn) {
for (c <− view(kv._1, kv._2))
mapping(c) = apply(c) + kv
}
def -= (kv: (A, B))(implicit txn: InTxn) {
for (c <− view(kv._1, kv._2)) {
val after = mapping(c) - kv._1
if (after.isEmpty)
mapping -= c
else
mapping(c) = after
}
}
Цесько В. А. (CompSciCenter)
STM
9 декабря 2013 г.
29 / 63](https://image.slidesharecdn.com/13-stm-131209130435-phpapp01/85/Software-Transactional-Memory-29-320.jpg)








![Internals
Maps + Sets
Manual snapshots
<TMap|TSet>[.View].snapshot() возвращает
immutable.Map/immutable.Set
<TMap|TSet>.clone()
Цесько В. А. (CompSciCenter)
STM
9 декабря 2013 г.
46 / 63](https://image.slidesharecdn.com/13-stm-131209130435-phpapp01/85/Software-Transactional-Memory-46-320.jpg)



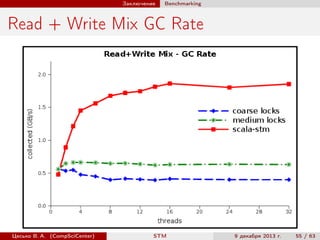
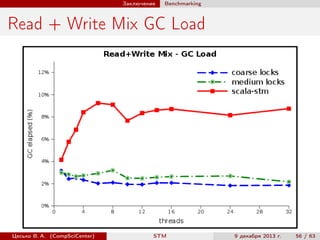






Документ представляет курс по программной транзакционной памяти (Software Transactional Memory, STM), в котором рассматриваются основы, примеры реализации и применения данного подхода в языках программирования, таких как Scala. В нем обсуждаются преимущества и недостатки STM, а также представляются различные примеры использования, включая хранение данных и сопоставление с индексами. Курс также затрагивает вопросы оптимистического управления конкурентностью и обработки транзакций.




























































