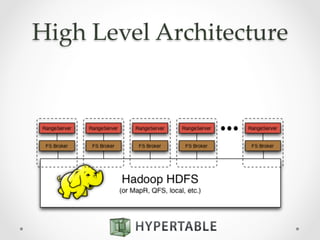
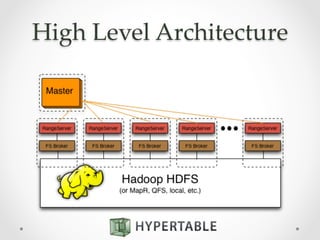
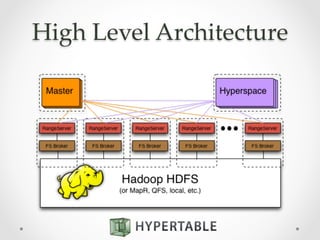
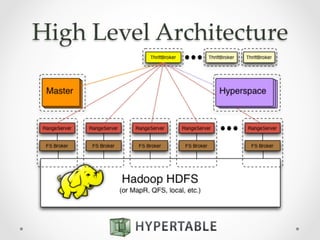
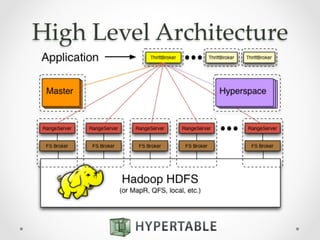
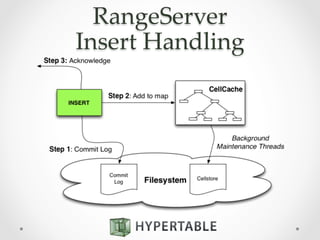
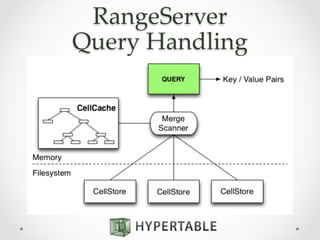
Hypertable is an open source, massively scalable database modeled after Google's Bigtable. It is written in C++ for high performance and supports Apache Thrift interfaces for popular languages. Hypertable is actively developed, has over 8 years of development, and supports features like namespaces, atomic counters, secondary indexes, regex filtering, and Hadoop integration. It is designed for horizontal scalability and sparse data structures, allowing for high throughput on both reads and writes even with large datasets.










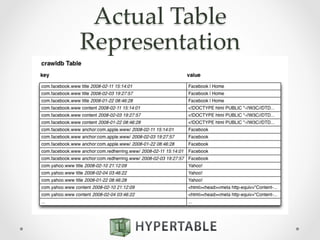





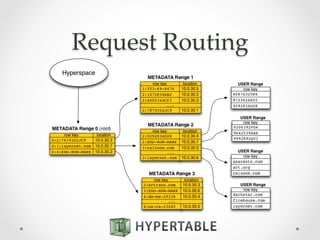


![cluster.def
INSTALL_PREFIX=/opt/hypertable
HYPERTABLE_VERSION=0.9.8.2
PACKAGE_FILE=/tmp/hypertable-0.9.8.2-linux-x86_64.tar.gz
FS=hadoop
HADOOP_DISTRO=cdh4
ORIGIN_CONFIG_FILE=/root/hypertable.cfg
PROMPT_CLEAN=true
role: source test00
role: master test[00-02]
role: hyperspace test[00-02]
role: slave test[03-99] - test37
role: thriftbroker
role: spare
include: "core.tasks"](https://image.slidesharecdn.com/2014-10-21hypertable-141022134800-conversion-gate01-2-151112222510-lva1-app6892/85/Hypertable-massively-scalable-nosql-database-30-320.jpg)


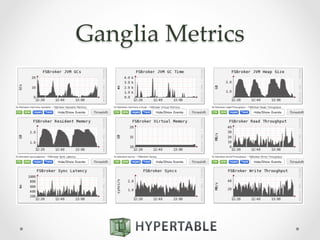

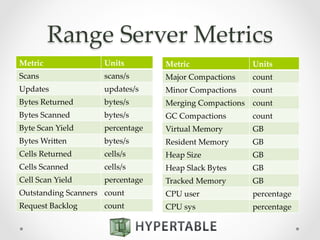
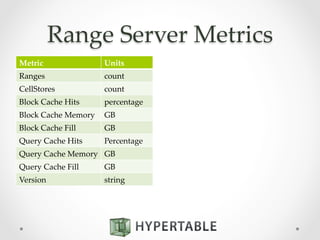




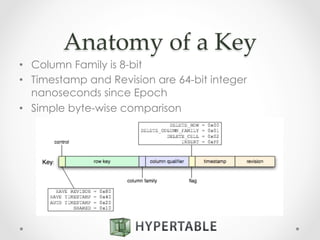
![Atomic Counters
• Column option:
CREATE TABLE counts (
url COUNTER
);
• Modified via existing API using specially
formatted values:
Value Format Description
[+]n Increment counter by n
-n Decrement counter by n
=n Reset counter to n](https://image.slidesharecdn.com/2014-10-21hypertable-141022134800-conversion-gate01-2-151112222510-lva1-app6892/85/Hypertable-massively-scalable-nosql-database-43-320.jpg)



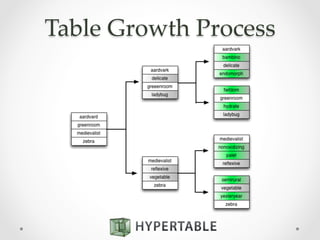
![Secondary Indexes
SELECT title, info:author
FROM products
WHERE info:author =~ /^Stephen [PK]/;
0307743659 title The Shining Mass Market Paperback
0307743659 info:author Stephen King
0321776402 title C++ Primer Plus (6th Edition)
(Developer's Library)
0321776402 info:author Stephen Prata](https://image.slidesharecdn.com/2014-10-21hypertable-141022134800-conversion-gate01-2-151112222510-lva1-app6892/85/Hypertable-massively-scalable-nosql-database-47-320.jpg)
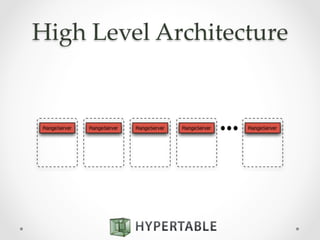
![Secondary Indexes
SELECT title
FROM products
WHERE Exists(info:studio);
B00002VWE0 title Five Easy Pieces (1970)
B000Q66J1M title 2001: A Space Odyssey [Blu-ray]
B002VWNIDG title The Shining (1980)](https://image.slidesharecdn.com/2014-10-21hypertable-141022134800-conversion-gate01-2-151112222510-lva1-app6892/85/Hypertable-massively-scalable-nosql-database-48-320.jpg)

![Secondary Indexes
SELECT title
FROM products
WHERE info:author =~ /^Stephen [PK]/ AND
info:publisher =~ /^Anchor/;
0307743659 title The Shining Mass Market Paperback](https://image.slidesharecdn.com/2014-10-21hypertable-141022134800-conversion-gate01-2-151112222510-lva1-app6892/85/Hypertable-massively-scalable-nosql-database-50-320.jpg)



![Regex Filtering
SELECT title
FROM products
WHERE ROW REGEXP "2";
0321321928 title C++ Common Knowledge: Essential
Intermediate Programming [Paperback]
0321776402 title C++ Primer Plus (6th Edition)
(Developer's Library)
B00002VWE0 title Five Easy Pieces (1970)
B002VWNIDG title The Shining (1980)](https://image.slidesharecdn.com/2014-10-21hypertable-141022134800-conversion-gate01-2-151112222510-lva1-app6892/85/Hypertable-massively-scalable-nosql-database-54-320.jpg)






















































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)







