Download to read offline





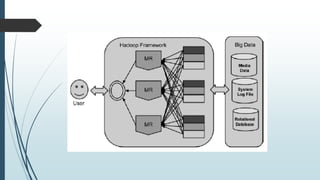



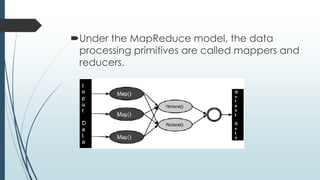
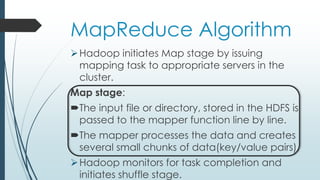



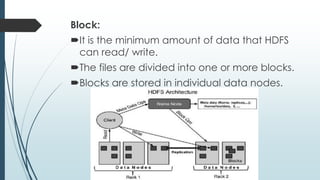


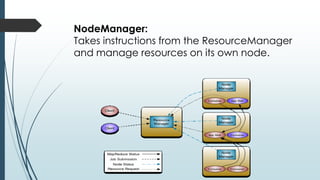








This document defines and describes big data and Hadoop. It states that big data is large datasets that cannot be processed using traditional techniques due to their volume, velocity and variety. It then describes the different types of data (structured, semi-structured, unstructured), challenges of big data, and Hadoop's use of MapReduce as a solution. It provides details on the Hadoop architecture including HDFS for storage and YARN for resource management. Common applications and users of Hadoop are also listed.










































































![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)







