Downloaded 21 times







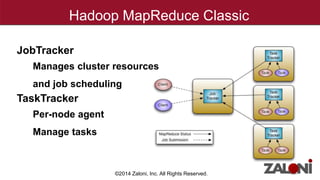

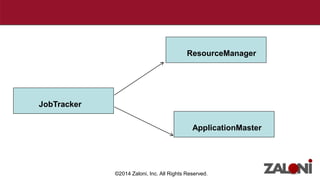
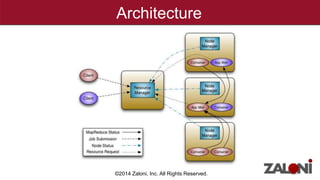







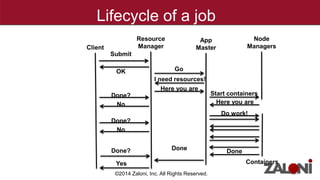
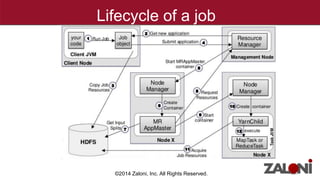










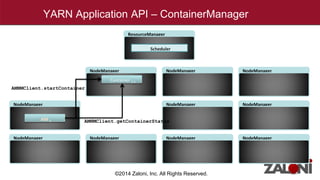










YARN (Yet Another Resource Negotiator) improves on MapReduce by separating cluster resource management from job scheduling and tracking. It introduces the ResourceManager for global resource management and per-application ApplicationMasters to manage individual applications. This provides improved scalability, availability, and allows various data processing frameworks beyond MapReduce to operate on shared Hadoop clusters. Key components of YARN include the ResourceManager, NodeManagers, ApplicationMasters and Containers as the basic unit of resource allocation. MRv2 uses a generalized architecture and APIs to provide benefits like rolling upgrades, multi-tenant clusters, and higher resource utilization.



































































