













![Page © Hortonworks Inc. 2014
© Hortonworks Inc. 2013
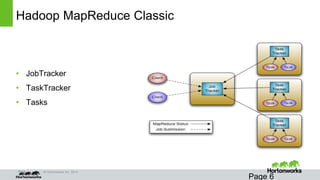
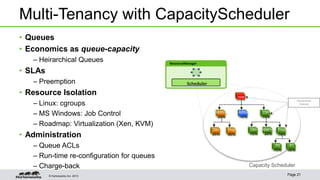
An Example Calculating Node Capacity
Important Parameters
–mapreduce.[map|reduce].memory.mb
– This is the physical ram hard-limit enforced by Hadoop on the task
–mapreduce.[map|reduce].java.opts
– The heapsize of the jvm –Xmx
–yarn.scheduler.minimum-allocation-mb
– The smallest container yarn will allow
–yarn.nodemanager.resource.memory-mb
– The amount of physical ram on the node](https://image.slidesharecdn.com/yarnthug2014-140626064817-phpapp01/85/Yarnthug2014-16-320.jpg)
![Page © Hortonworks Inc. 2014
© Hortonworks Inc. 2013
Calculating Node Capacity Continued
• Lets pretend we need a 1g map and a 2g reduce
• mapreduce[map|reduce].java.opts = [-Xmx 1g | -Xmx 2g]
• Remember a container has more overhead then just your heap!
• Add 512mb to the container limit for overhead
• mapreduce.[map.reduce].memory.mb= [1536 | 2560]
• We have 36g per node and minimum allocations of 512mb
• yarn.nodemanager.resource.memory-mb=36864
• yarn.scheduler.minimum-allocation-mb=512
• Our 36g node can support
• 24 Maps OR 14 Reducers OR any combination
allowed by the resources on the node](https://image.slidesharecdn.com/yarnthug2014-140626064817-phpapp01/85/Yarnthug2014-17-320.jpg)





![Page © Hortonworks Inc. 2014
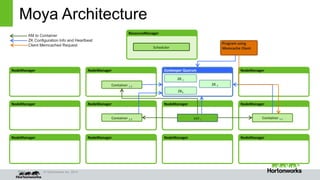
A Look at the Moya Memcached Container
•Simple!
•Join the Zookeeper Moya group with Hostname and Port as member name
//initialize the server
daemon = new MemCacheDaemon<LocalCacheElement>();
CacheStorage<Key, LocalCacheElement> storage;
InetSocketAddress c = new InetSocketAddress(8555);
storage = ConcurrentLinkedHashMap.create(
ConcurrentLinkedHashMap.EvictionPolicy.FIFO, 15000, 67108864);
daemon.setCache(new CacheImpl(storage));
daemon.setBinary(false);
daemon.setAddr(c);
daemon.setIdleTime(120);
daemon.setVerbose(true);
daemon.start();
//StartJettyTest.main(new String[] {}); // Whats this?
// Add self in zookeer /moya/ group
JoinGroup.main( new String[]
{ "172.16.165.155:2181”, "moya », InetAddress.getLocalHost().getHostName() + « : »+ c.getPort() });](https://image.slidesharecdn.com/yarnthug2014-140626064817-phpapp01/85/Yarnthug2014-28-320.jpg)






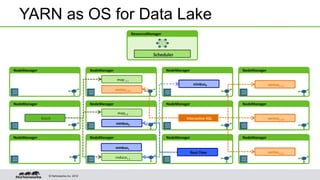
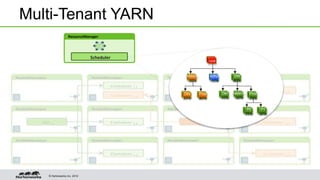
YARN is a resource management framework for Hadoop that allows multiple data processing engines such as MapReduce, Spark, and Storm to run on the same cluster. It introduces a global ResourceManager and per-node NodeManagers to allocate and manage resources across applications. YARN supports multi-tenant clusters with queues that provide resource guarantees and isolation between users and workloads. A demo showed preemption and multi-tenant queues handling different workloads hitting the cluster.




















![[db tech showcase Tokyo 2014] C32: Hadoop最前線 - 開発の現場から by NTT 小沢健史](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014c32ntthadoop-141203014329-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)














































