Downloaded 32 times





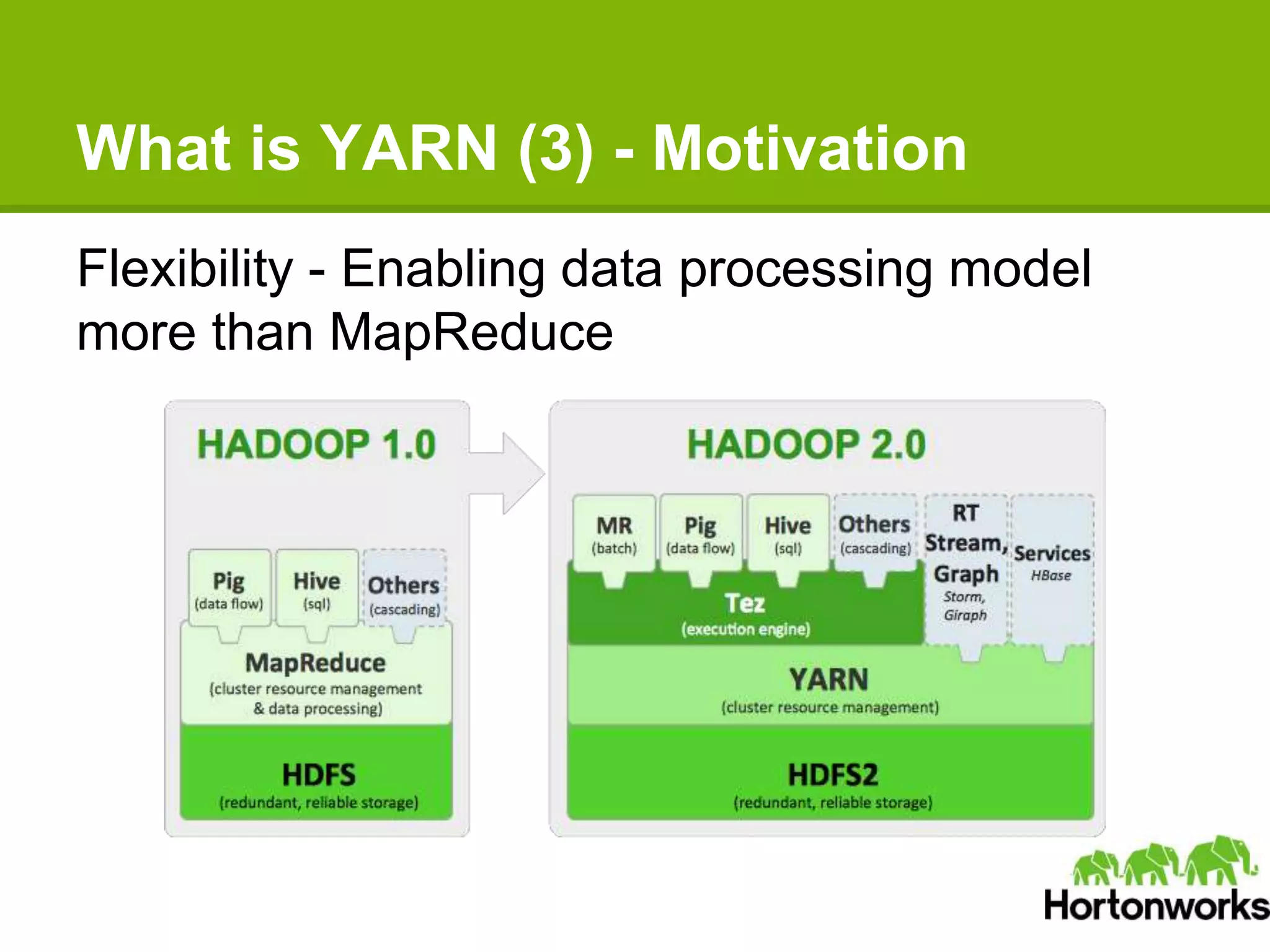
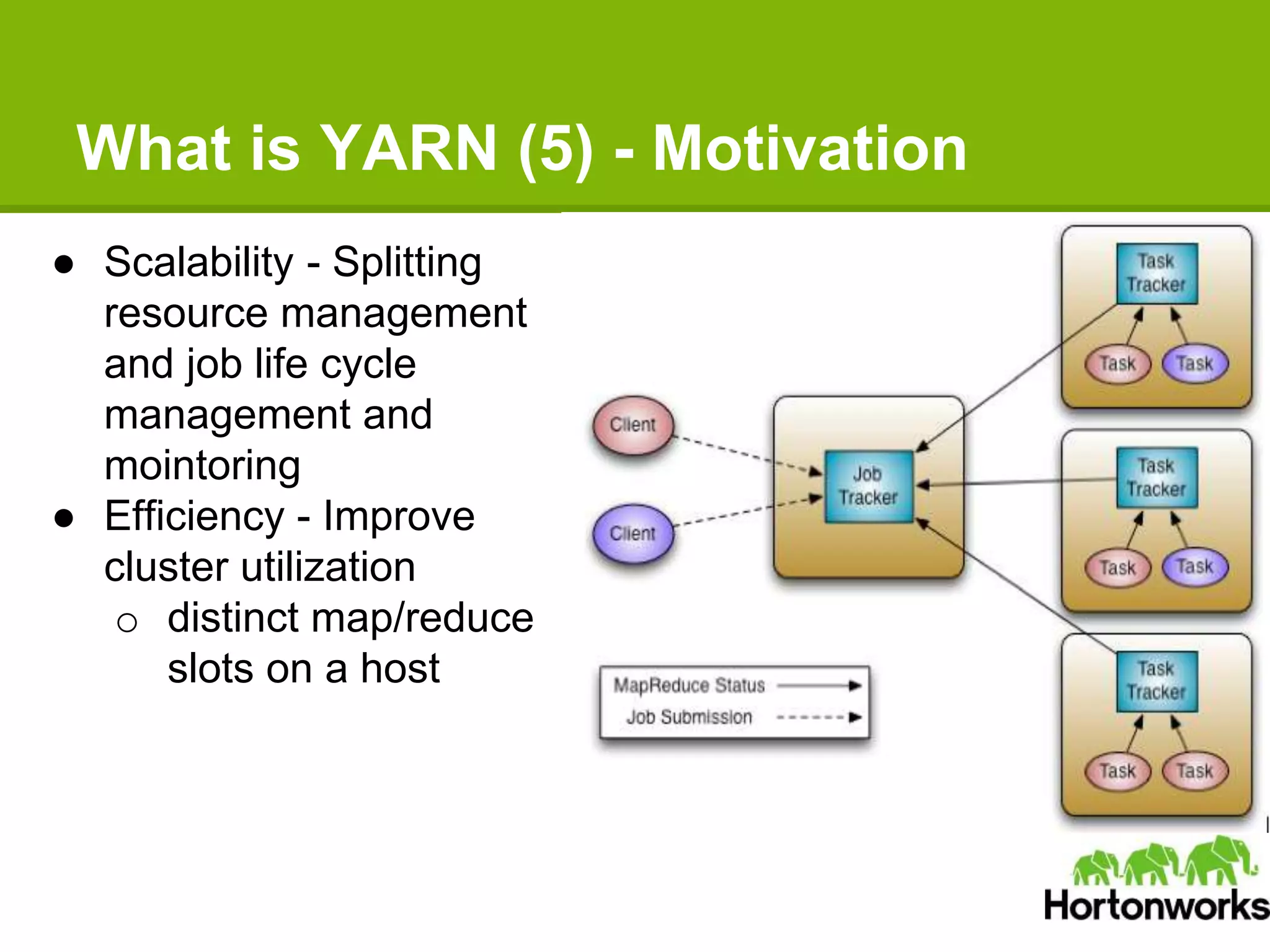
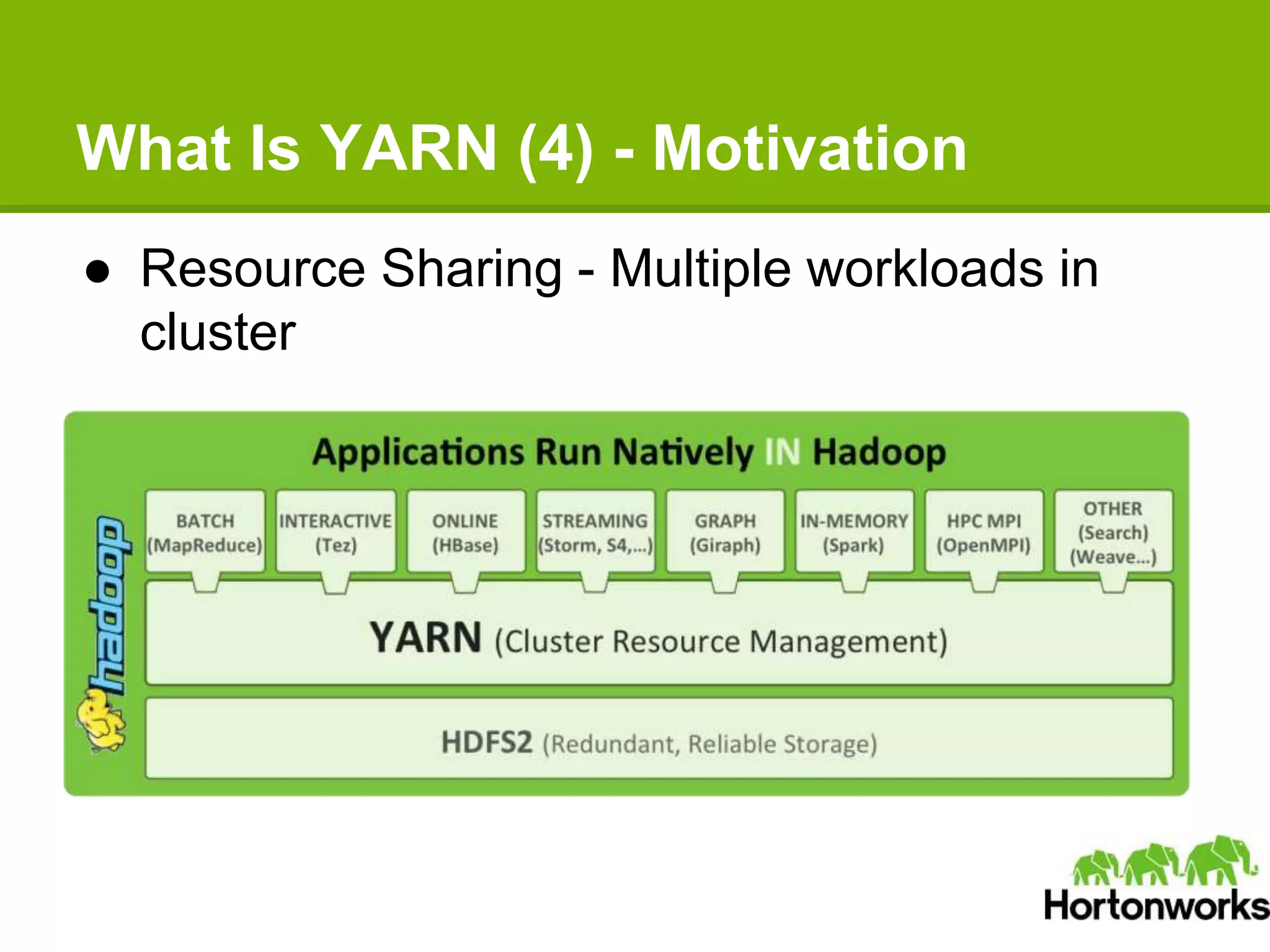

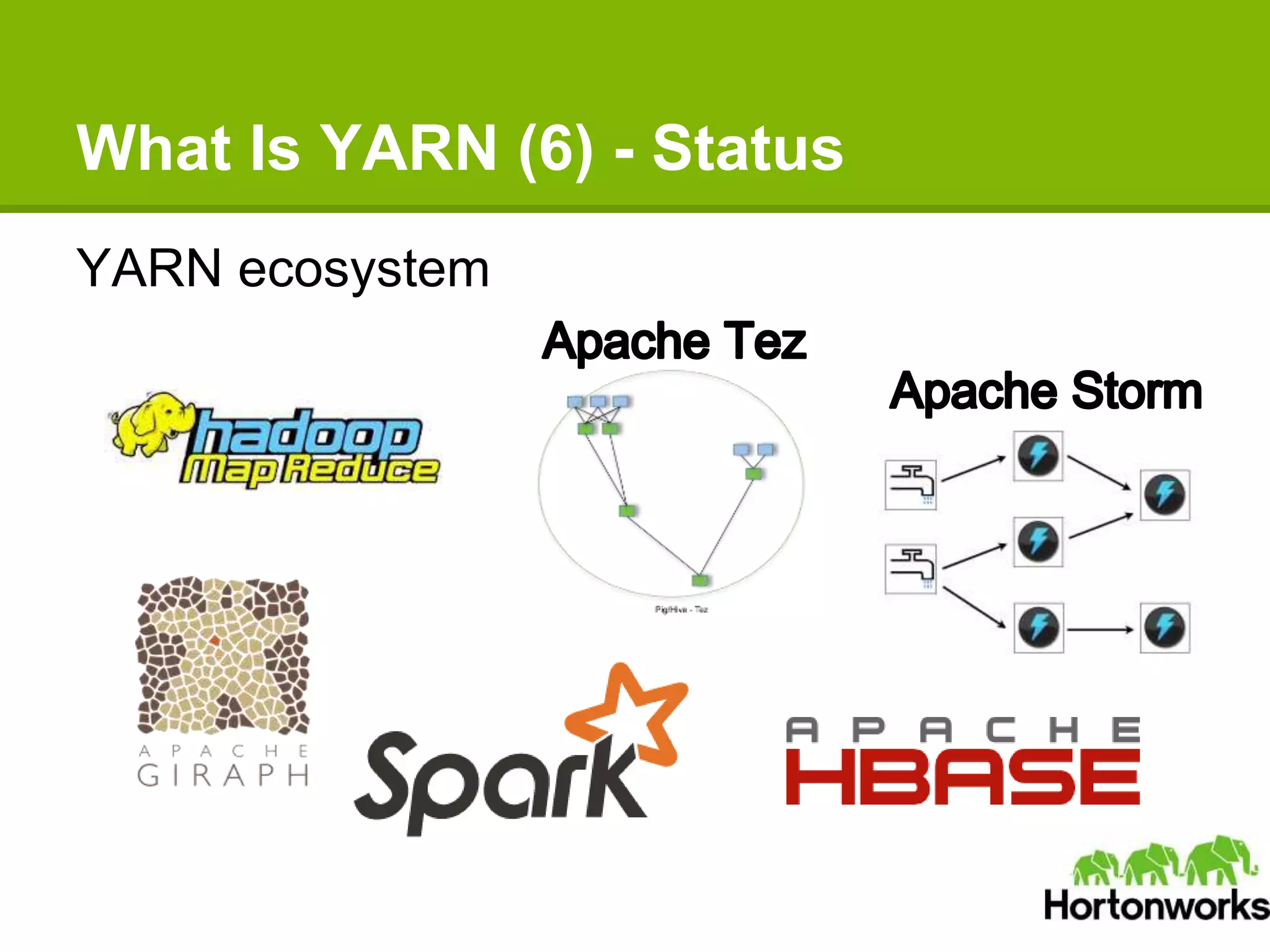


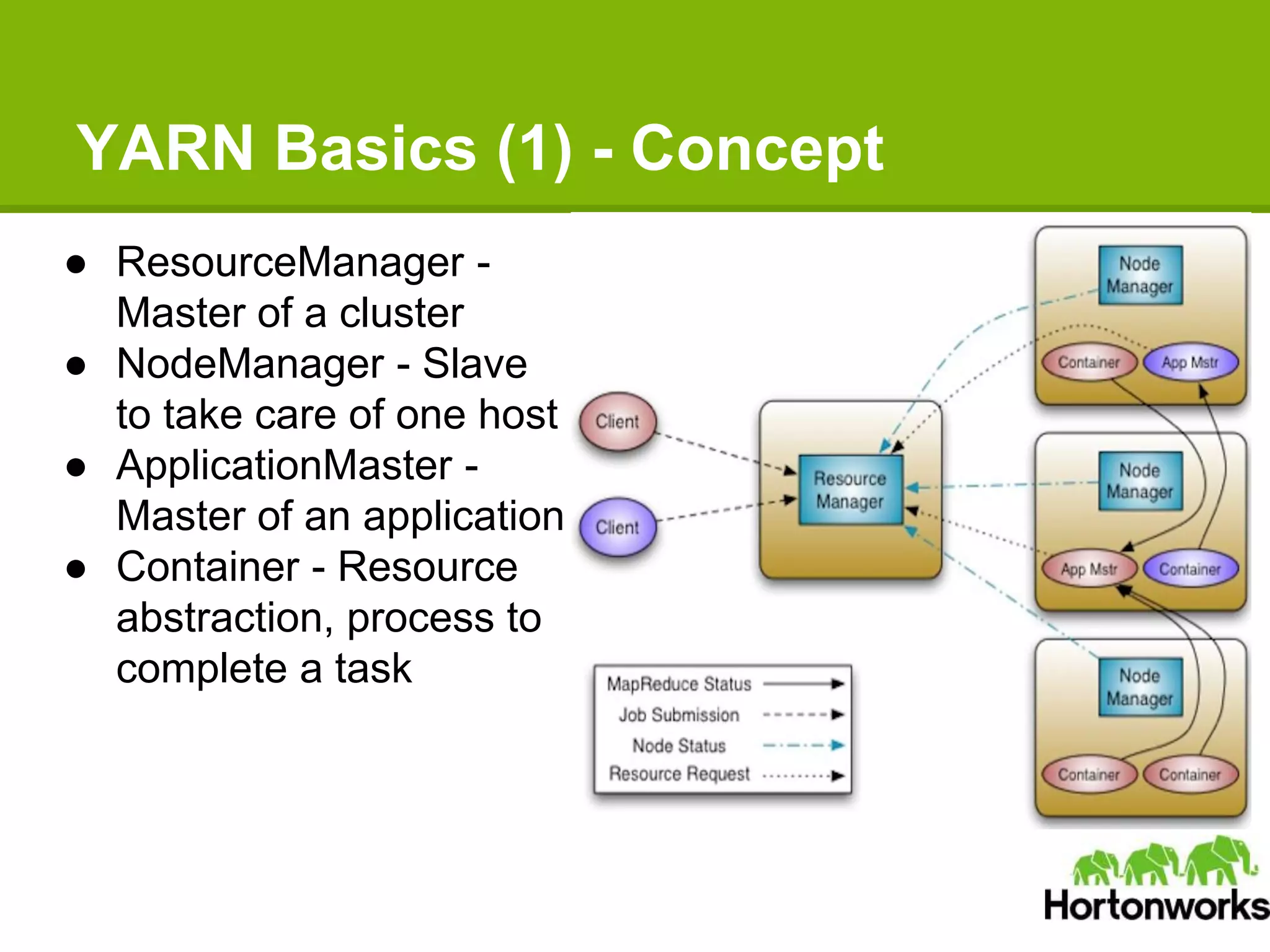
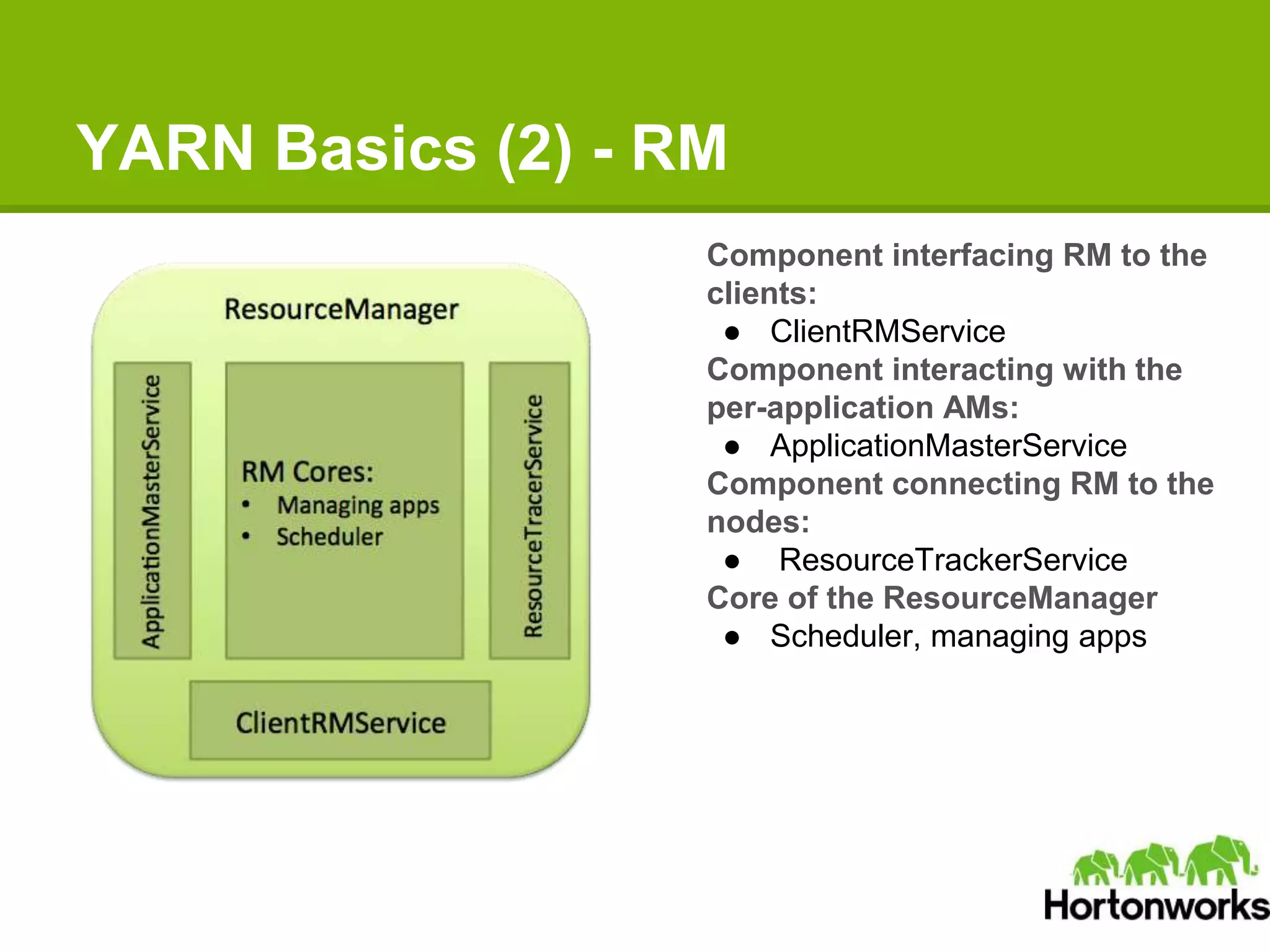







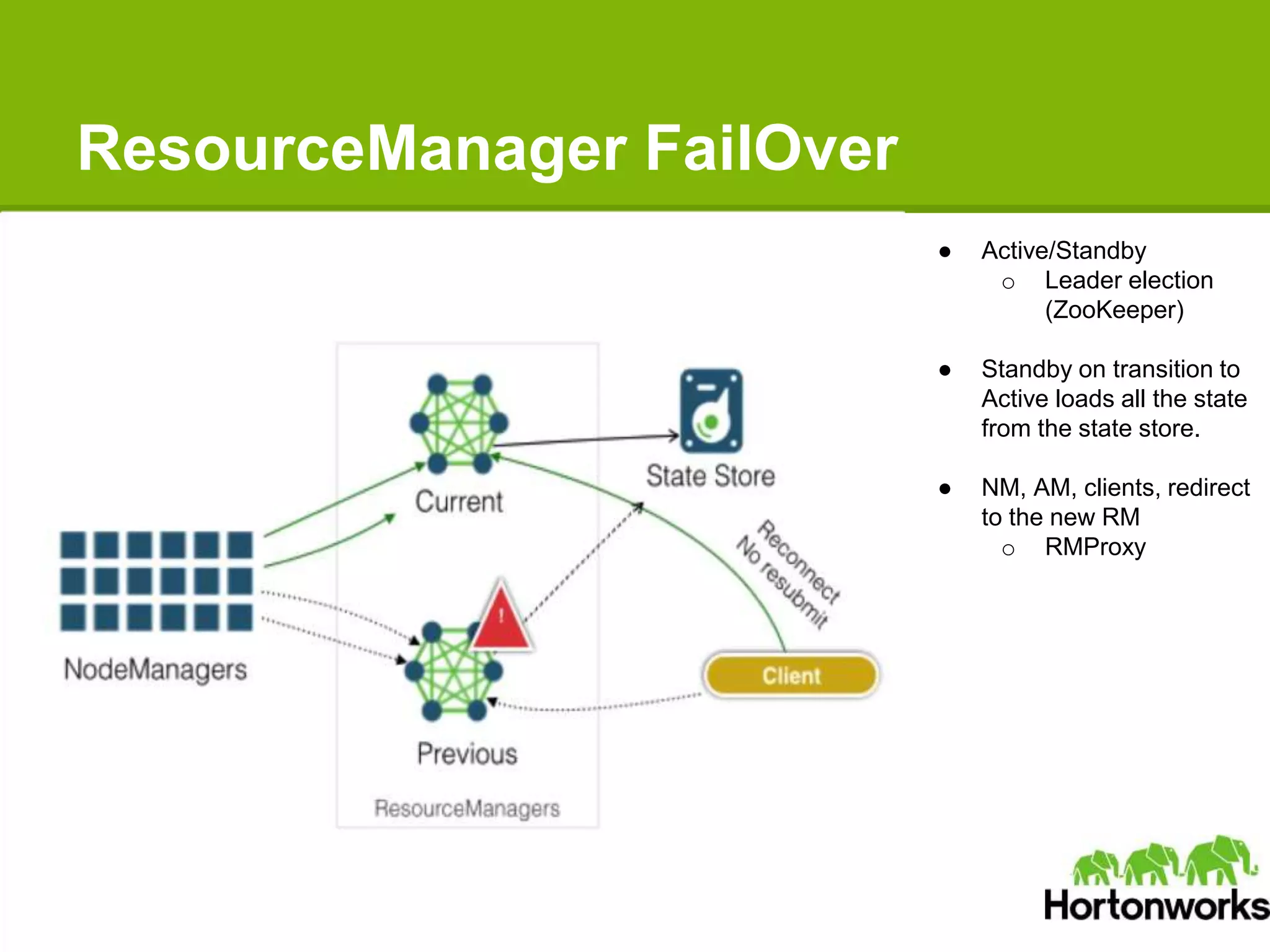


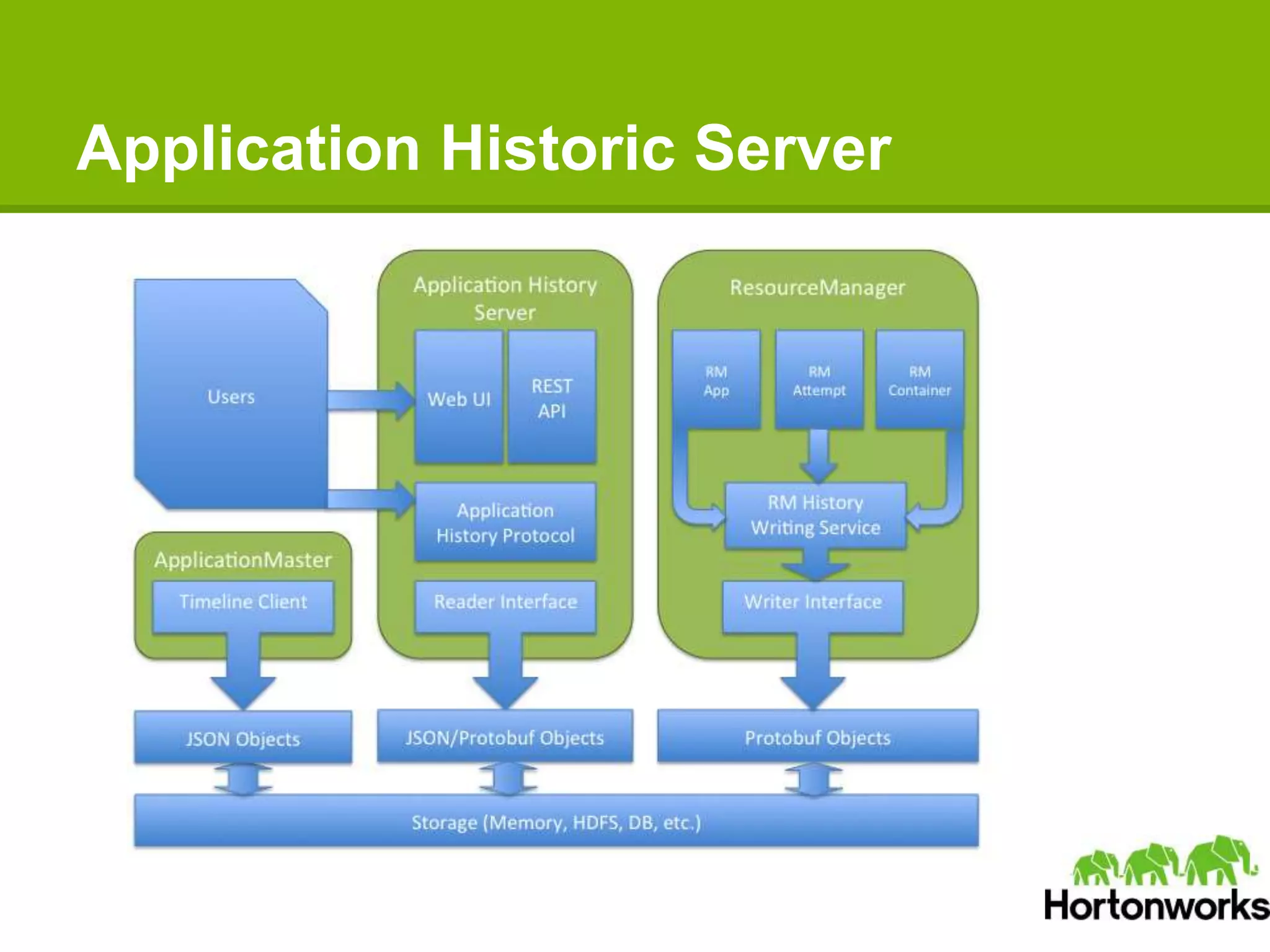
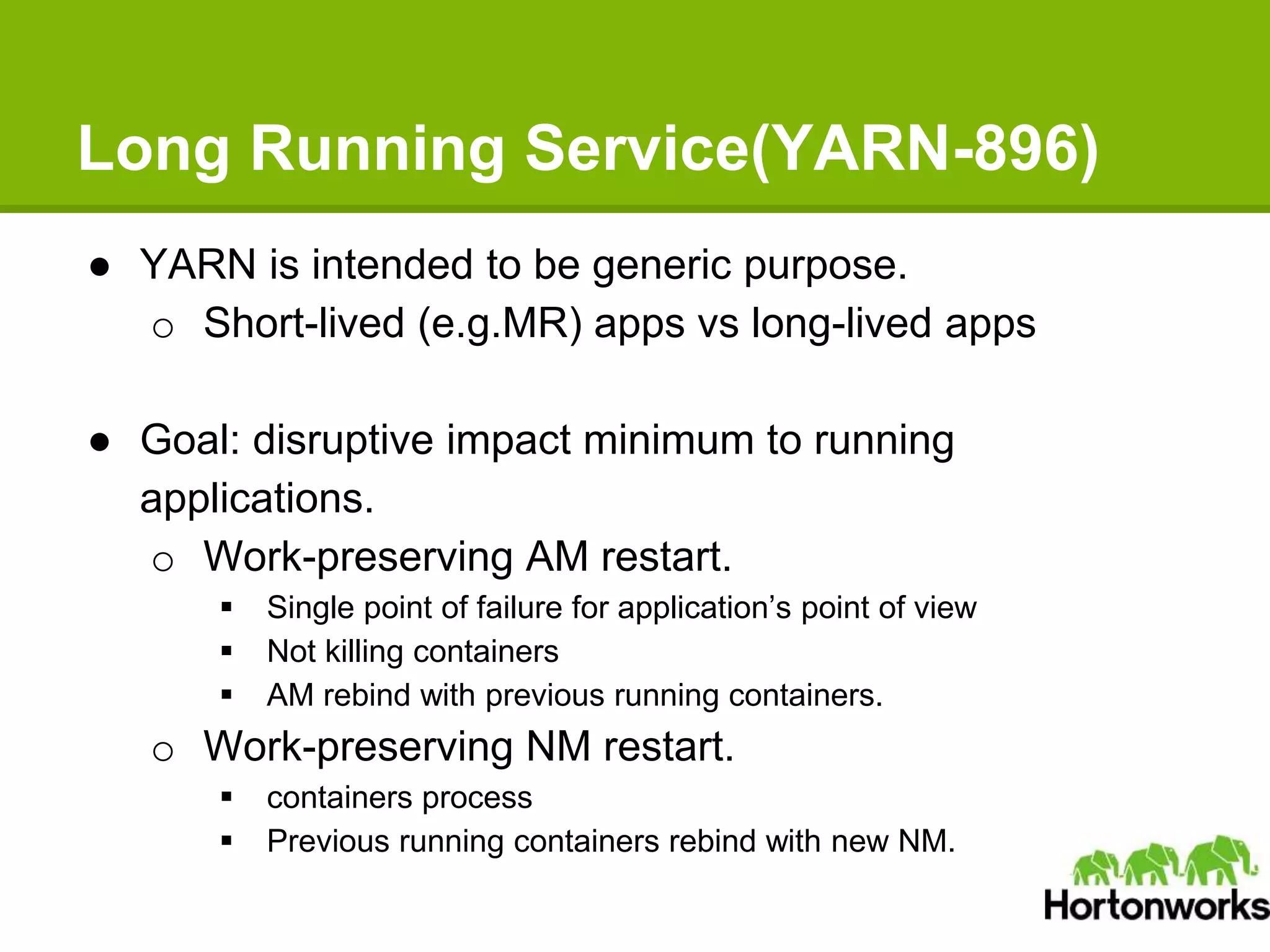

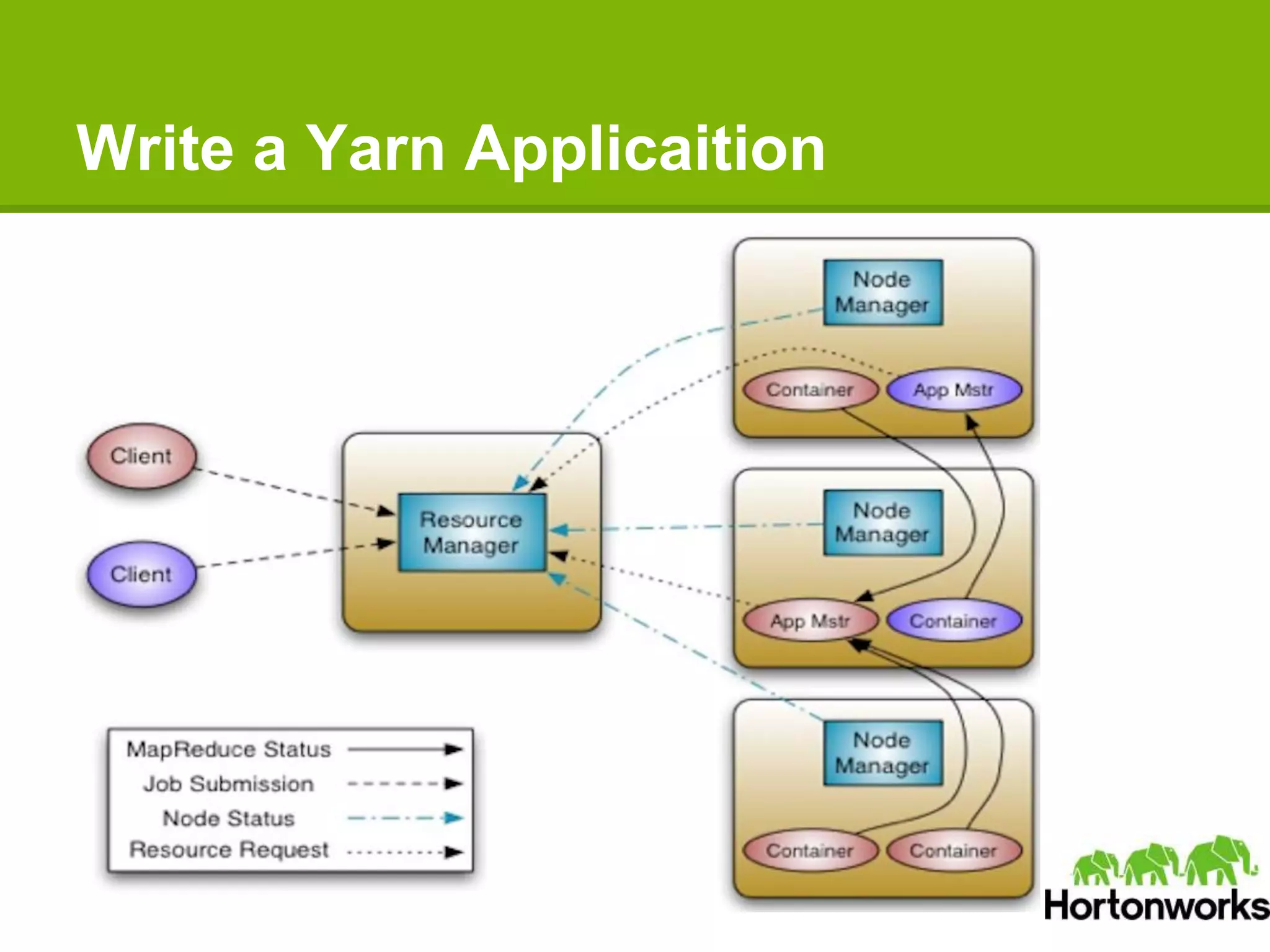













Apache Hadoop YARN is a next-generation distributed operating system designed to enhance resource management and scalability for various data processing applications beyond MapReduce. It separates resource management and job lifecycle management to improve efficiency and cluster utilization, targeting high availability and historical data services. YARN is actively being developed with contributions from a vibrant community, and it is currently in production at major companies like Yahoo and eBay.