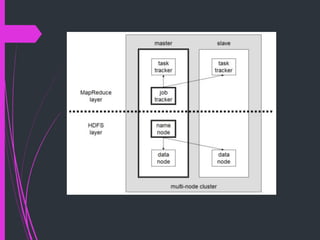
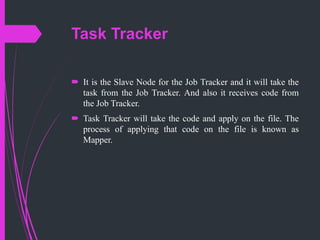
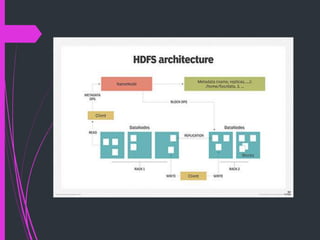
The document summarizes Hadoop Distributed File System (HDFS). HDFS is the primary data storage system used by Hadoop applications to provide scalable and reliable access to data across large clusters. It uses a master-slave architecture with a NameNode that manages file metadata and DataNodes that store file data blocks. HDFS supports big data analytics applications by enabling distributed processing of large datasets in a fault-tolerant manner.