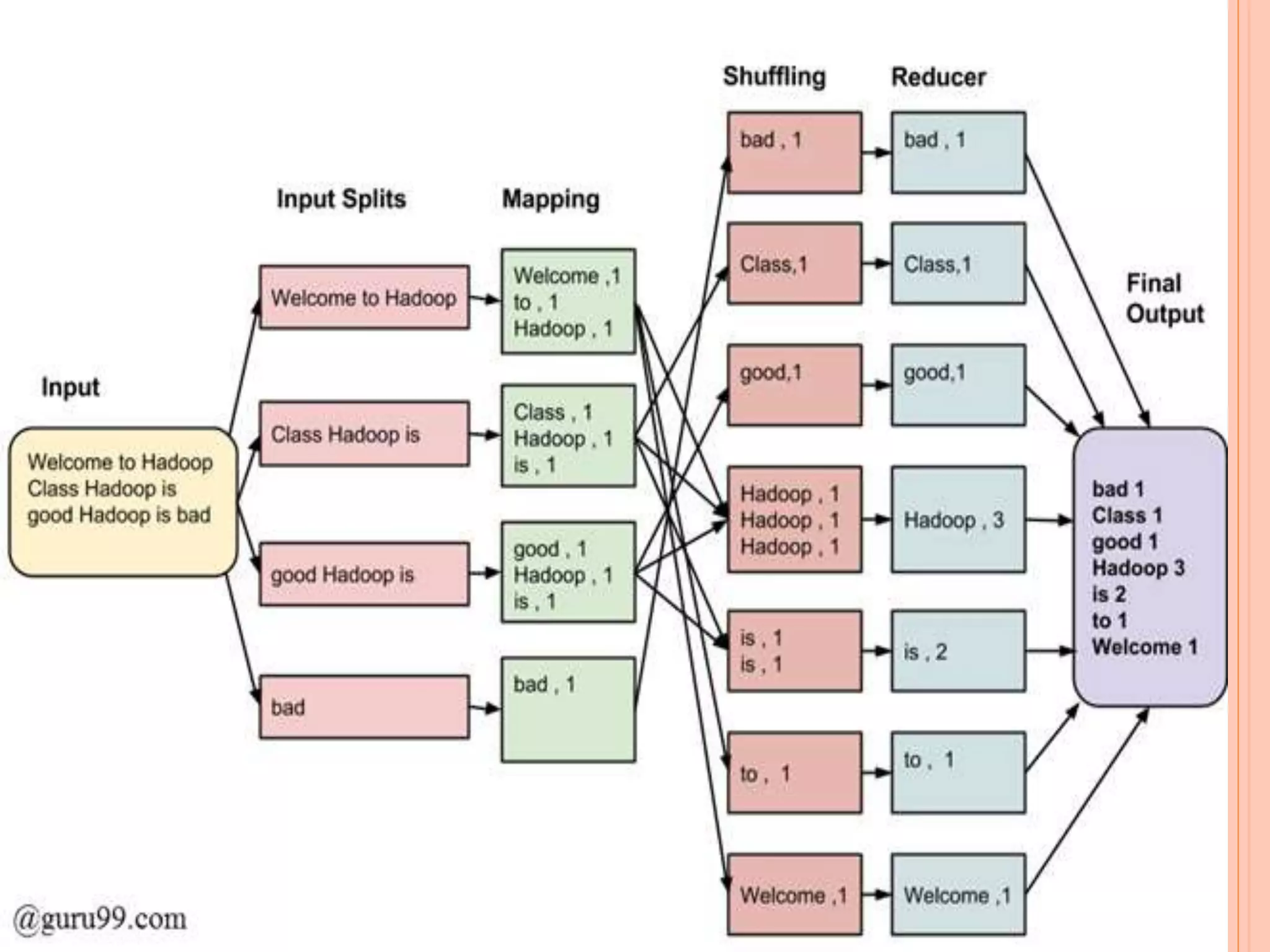
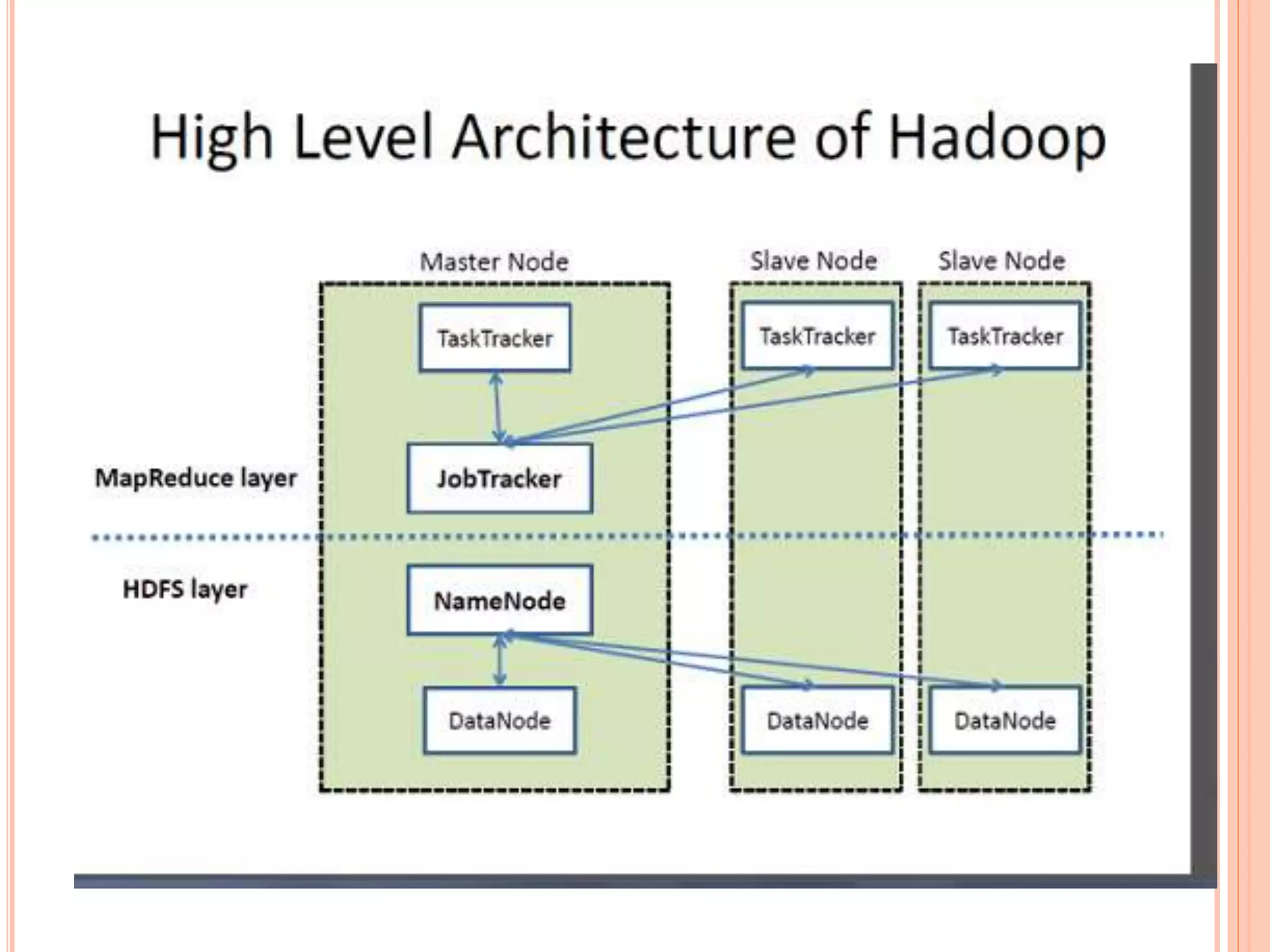
The document discusses MapReduce, a programming model used in distributed computing. It has two main phases - the Map phase and the Reduce phase. In the Map phase, data is processed and broken down into key-value pairs. The Reduce phase combines these pairs into smaller sets of data. MapReduce programs execute in three stages - the Map stage processes input data in parallel, the Shuffle stage consolidates records from Mappers, and the Reduce stage aggregates output to summarize the dataset. Hadoop is an open-source software that uses this model with a master-worker architecture and the HDFS distributed file system.