Downloaded 36 times








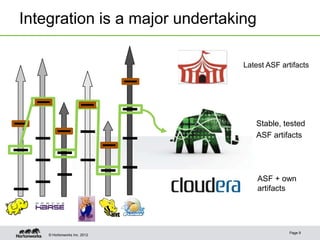


















The document discusses the history and current state of Hadoop development, highlighting its evolution from version 0.20 to the latest 2.x versions. It emphasizes the challenges within the Hadoop ecosystem, including integration, testing, and resistance to changes due to the high stakes of data integrity. The document also calls for contributors with specialized skills to enhance the project and suggests avenues for involvement, such as mentoring programs and developer workshops.










































































