Downloaded 17 times





















![Page 27 © Hortonworks Inc. 2011 – 2014. All Rights Reserved
Sample SQL with Hive
SELECT [ALL | DISTINCT] select_expr, select_expr, ...!
FROM table_reference!
[WHERE where_condition]!
[GROUP BY col_list]!
[HAVING having_condition]!
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY
!col_list]]!
[LIMIT number] ; !](https://image.slidesharecdn.com/possconyarn-150501085629-conversion-gate01/85/How-YARN-Enables-Multiple-Data-Processing-Engines-in-Hadoop-27-320.jpg)















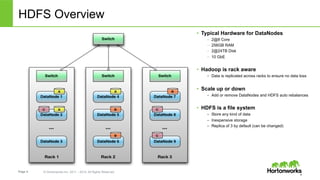
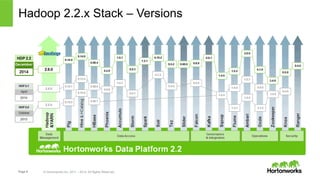
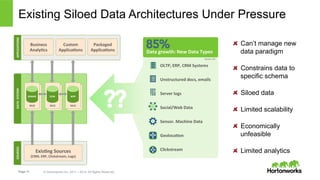
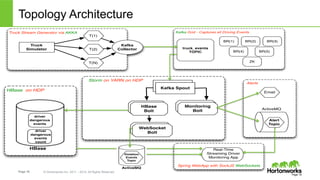
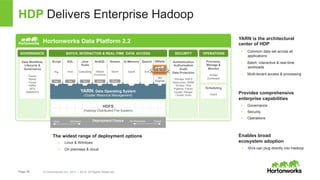
The document discusses how YARN (Yet Another Resource Negotiator) enhances Hadoop's capabilities by providing a resource management framework that supports multiple data processing engines, enabling batch, interactive, and real-time workloads. It details YARN's architecture, which includes components like Resource Manager, Node Manager, and Application Master, alongside HDFS (Hadoop Distributed File System) for storage. Additionally, the document highlights various applications and tools compatible with YARN, fostering a modern data architecture capable of addressing diverse analytical needs.



















































![Discover.hdp2.2.h base.final[2]](https://cdn.slidesharecdn.com/ss_thumbnails/discover-141218155001-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)









![Discover.hdp2.2.ambari.final[1]](https://cdn.slidesharecdn.com/ss_thumbnails/discover-150114162536-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)













































