Downloaded 392 times





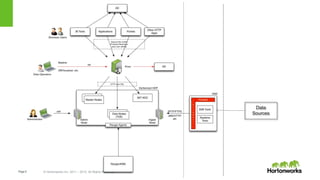

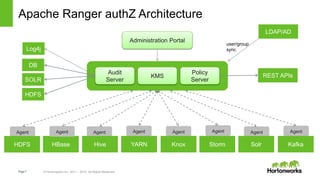
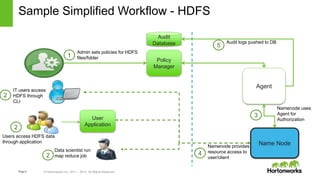










The document provides an overview of Apache Ranger, detailing its role in managing security for Hadoop environments through centralized policy definition for resource access. It covers key components, best practices for authorization, and audit locations to monitor user activity. Additionally, it includes practical guidance on implementing encryption and utilizing user synchronization effectively.














































































