Downloaded 89 times





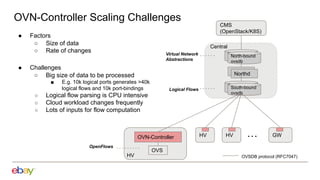
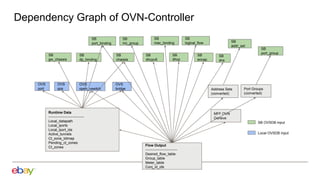


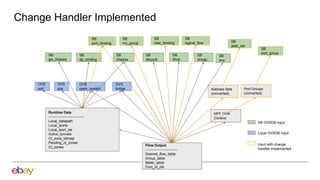
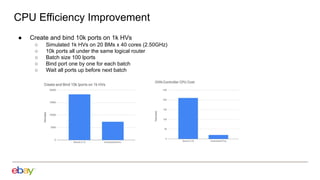

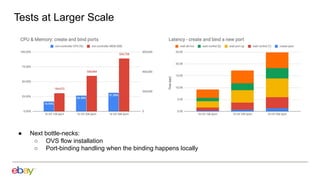


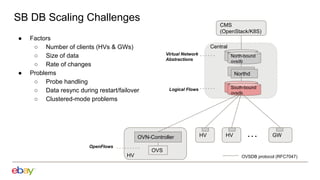

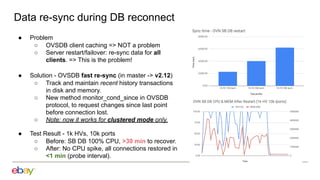






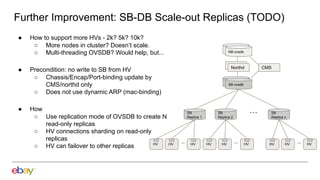
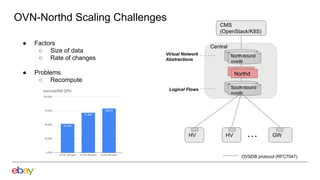

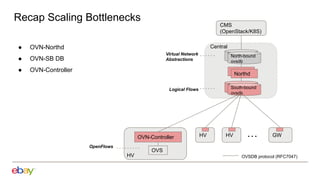





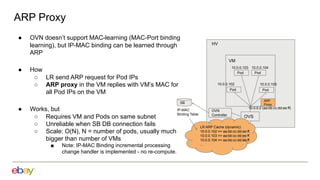
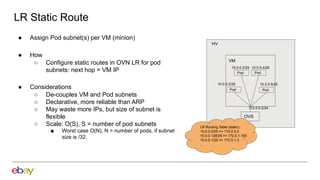

Han Zhou presents problems and solutions for scaling Open Virtual Network (OVN) components in large overlay networks. The key challenges addressed are: 1. Scaling the OVN controller by moving from recomputing all flows to incremental processing based on changes. 2. Scaling the southbound OVN database by increasing probe intervals, enabling fast resync on reconnect, and improving performance of the clustered mode. 3. Further work is planned to incrementally install flows, reduce per-host data, and scale out the southbound database with replicas.










![[2018] 오픈스택 5년 운영의 경험](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra05-190131073350-thumbnail.jpg?width=640&height=640&fit=bounds)





![[OpenInfra Days Korea 2018] (Track 2) Neutron LBaaS 어디까지 왔니? - Octavia 소개](https://cdn.slidesharecdn.com/ss_thumbnails/26octavia-180704054917-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[OSS Upstream Training] 5 open stack liberty_recap](https://cdn.slidesharecdn.com/ss_thumbnails/5openstacklibertyrecap-151227095312-thumbnail.jpg?width=640&height=640&fit=bounds)






























