Downloaded 43 times






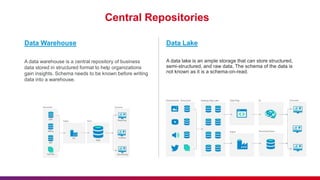




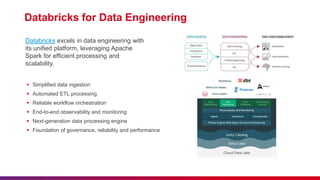
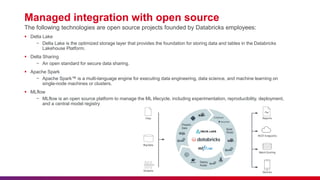
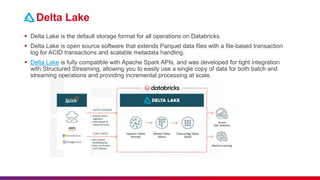
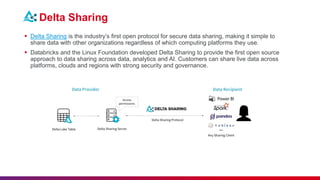






The document provides a comprehensive overview of data engineering, including definitions of data engineers, analysts, and scientists, as well as details about data storage methods like data warehouses, data lakes, and the emerging data lakehouse architecture. It highlights Databricks as a unified analytics platform for data management and mentions key features, such as Delta Lake and integration with platforms like AWS and Azure. Additionally, it emphasizes best practices for etiquette during sessions and the importance of timely attendance and constructive feedback.














![[DSC Europe 22] Overview of the Databricks Platform - Petar Zecevic](https://cdn.slidesharecdn.com/ss_thumbnails/petarzecevic-databricksoverview-221130080703-c60d93de-thumbnail.jpg?width=640&height=640&fit=bounds)








































































