Master Databricks with AccentFuture! Learn data engineering, ML & analytics using Apache Spark. Get hands-on labs, real projects & expert support. Start your journey to data mastery today!
• Delta Lakeis an open-source storage layer that
brings ACID transactions to Apache Spark and
big data workloads.
• Developed by Databricks to solve reliability
issues in data lakes.
• Built on top of Apache Parquet format.
What is Delta Lake?
+91-96400 01789
contact@accentfuture.com
3.
Why Delta Lake?
•Solves the “Data Lake Reliability” problem.
• Enables atomic writes, schema enforcement, and time travel.
• Improves data quality, consistency, and scalability.
+91-96400 01789
contact@accentfuture.com
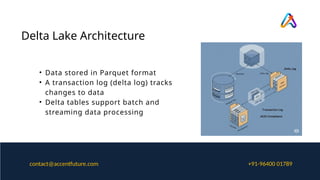
Delta Lake Architecture
•Data stored in Parquet format
• A transaction log (delta log) tracks
changes to data
• Delta tables support batch and
streaming data processing
+91-96400 01789
contact@accentfuture.com
Common Delta LakeOperations
+91-96400 01789
contact@accentfuture.com
8.
Delta Lake UseCases
• Building reliable ETL pipelines
• Powering data warehousing
• Real-time streaming analytics
• Enabling machine learning with clean
data
+91-96400 01789
contact@accentfuture.com
9.
Delta Lake onDatabricks
• Fully integrated into the Databricks Lakehouse Platform
• Easily convert existing Parquet tables to Delta
• Support for Unity Catalog, Auto Optimize, and Streaming
Reads
+91-96400 01789
contact@accentfuture.com
10.
Benefits Summary
• Combinesreliability of data warehouses with scale &
flexibility of data lakes
• Ideal for big data and AI workloads
• Compatible with Apache Spark, Databricks, and other
platforms
+91-96400 01789
contact@accentfuture.com



























![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)


















































