Downloaded 61 times





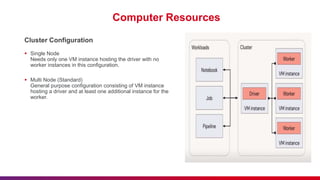



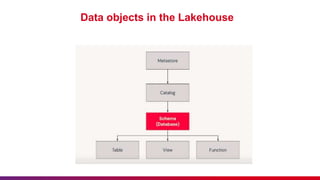



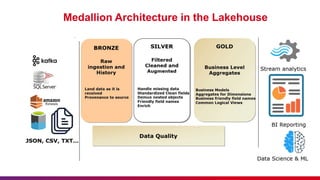






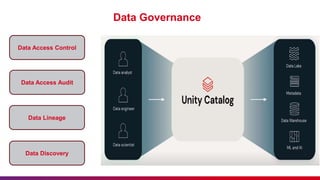
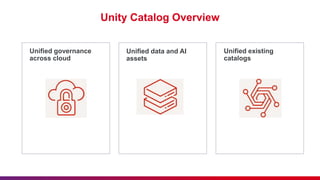
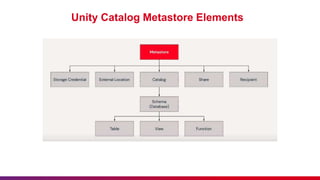
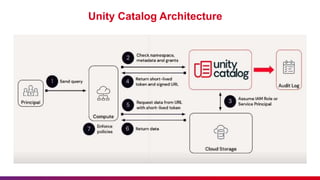


The document outlines guidelines for etiquette during Databricks sessions, emphasizing punctuality, feedback, and minimizing disruptions. It also provides an overview of Databricks features, including multi-node and all-purpose clusters, Delta Lake for object storage management, and Delta Live Tables for building data pipelines. Additionally, it discusses governance aspects like data access control and lineage within the Unity Catalog framework.





![[DSC Europe 22] Overview of the Databricks Platform - Petar Zecevic](https://cdn.slidesharecdn.com/ss_thumbnails/petarzecevic-databricksoverview-221130080703-c60d93de-thumbnail.jpg?width=640&height=640&fit=bounds)

















































































