Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
MITSUNARI Shigeo
PDF, PPTX
3,260 views
From IA-32 to avx-512
システムプログラミング会 http://connpass.com/event/34995/
Technology
◦
Read more
5
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 30
2
/ 30
3
/ 30
4
/ 30
5
/ 30
6
/ 30
7
/ 30
8
/ 30
9
/ 30
10
/ 30
11
/ 30
12
/ 30
13
/ 30
14
/ 30
15
/ 30
16
/ 30
17
/ 30
18
/ 30
19
/ 30
20
/ 30
21
/ 30
22
/ 30
23
/ 30
24
/ 30
25
/ 30
26
/ 30
27
/ 30
28
/ 30
29
/ 30
30
/ 30
More Related Content
PDF
LLVM最適化のこつ
by
MITSUNARI Shigeo
PPTX
Prosym2012
by
MITSUNARI Shigeo
PDF
Haswellサーベイと有限体クラスの紹介
by
MITSUNARI Shigeo
PDF
optimal Ate pairing
by
MITSUNARI Shigeo
PDF
Wavelet matrix implementation
by
MITSUNARI Shigeo
PDF
高速な倍精度指数関数expの実装
by
MITSUNARI Shigeo
PDF
汎用性と高速性を目指したペアリング暗号ライブラリ mcl
by
MITSUNARI Shigeo
PDF
emcjp Item 42
by
MITSUNARI Shigeo
LLVM最適化のこつ
by
MITSUNARI Shigeo
Prosym2012
by
MITSUNARI Shigeo
Haswellサーベイと有限体クラスの紹介
by
MITSUNARI Shigeo
optimal Ate pairing
by
MITSUNARI Shigeo
Wavelet matrix implementation
by
MITSUNARI Shigeo
高速な倍精度指数関数expの実装
by
MITSUNARI Shigeo
汎用性と高速性を目指したペアリング暗号ライブラリ mcl
by
MITSUNARI Shigeo
emcjp Item 42
by
MITSUNARI Shigeo
What's hot
PPTX
AVX-512(フォーマット)詳解
by
MITSUNARI Shigeo
PDF
フラグを愛でる
by
MITSUNARI Shigeo
PDF
Intel AVX-512/富岳SVE用SIMDコード生成ライブラリsimdgen
by
MITSUNARI Shigeo
PDF
HPC Phys-20201203
by
MITSUNARI Shigeo
PDF
条件分岐とcmovとmaxps
by
MITSUNARI Shigeo
PDF
LLVMで遊ぶ(整数圧縮とか、x86向けの自動ベクトル化とか)
by
Takeshi Yamamuro
PDF
SSE4.2の文字列処理命令の紹介
by
MITSUNARI Shigeo
PDF
Intro to SVE 富岳のA64FXを触ってみた
by
MITSUNARI Shigeo
PDF
GPUが100倍速いという神話をぶち殺せたらいいな ver.2013
by
Ryo Sakamoto
PDF
llvm入門
by
MITSUNARI Shigeo
PDF
Xeon PhiとN体計算コーディング x86/x64最適化勉強会6(@k_nitadoriさんの代理アップ)
by
MITSUNARI Shigeo
PDF
あなたの知らないnopたち@ラボユース合宿
by
MITSUNARI Shigeo
PDF
ElGamal型暗号文に対する任意関数演算・再暗号化の二者間秘密計算プロトコルとその応用
by
MITSUNARI Shigeo
PDF
Xbyakの紹介とその周辺
by
MITSUNARI Shigeo
PDF
C/C++プログラマのための開発ツール
by
MITSUNARI Shigeo
KEY
関東GPGPU勉強会 LLVM meets GPU
by
Takuro Iizuka
PDF
WASM(WebAssembly)入門 ペアリング演算やってみた
by
MITSUNARI Shigeo
PDF
準同型暗号の実装とMontgomery, Karatsuba, FFT の性能
by
MITSUNARI Shigeo
PDF
研究動向から考えるx86/x64最適化手法
by
Takeshi Yamamuro
PDF
ゆるバグ
by
MITSUNARI Shigeo
AVX-512(フォーマット)詳解
by
MITSUNARI Shigeo
フラグを愛でる
by
MITSUNARI Shigeo
Intel AVX-512/富岳SVE用SIMDコード生成ライブラリsimdgen
by
MITSUNARI Shigeo
HPC Phys-20201203
by
MITSUNARI Shigeo
条件分岐とcmovとmaxps
by
MITSUNARI Shigeo
LLVMで遊ぶ(整数圧縮とか、x86向けの自動ベクトル化とか)
by
Takeshi Yamamuro
SSE4.2の文字列処理命令の紹介
by
MITSUNARI Shigeo
Intro to SVE 富岳のA64FXを触ってみた
by
MITSUNARI Shigeo
GPUが100倍速いという神話をぶち殺せたらいいな ver.2013
by
Ryo Sakamoto
llvm入門
by
MITSUNARI Shigeo
Xeon PhiとN体計算コーディング x86/x64最適化勉強会6(@k_nitadoriさんの代理アップ)
by
MITSUNARI Shigeo
あなたの知らないnopたち@ラボユース合宿
by
MITSUNARI Shigeo
ElGamal型暗号文に対する任意関数演算・再暗号化の二者間秘密計算プロトコルとその応用
by
MITSUNARI Shigeo
Xbyakの紹介とその周辺
by
MITSUNARI Shigeo
C/C++プログラマのための開発ツール
by
MITSUNARI Shigeo
関東GPGPU勉強会 LLVM meets GPU
by
Takuro Iizuka
WASM(WebAssembly)入門 ペアリング演算やってみた
by
MITSUNARI Shigeo
準同型暗号の実装とMontgomery, Karatsuba, FFT の性能
by
MITSUNARI Shigeo
研究動向から考えるx86/x64最適化手法
by
Takeshi Yamamuro
ゆるバグ
by
MITSUNARI Shigeo
Viewers also liked
PDF
バックドア耐性のあるパスワード暗号化の提案
by
MITSUNARI Shigeo
PDF
Backdoors with the MS Office file encryption master key and a proposal for a ...
by
MITSUNARI Shigeo
PDF
Slide dist
by
MITSUNARI Shigeo
PDF
Wifiで位置推定
by
nishio
PDF
SGD+α: 確率的勾配降下法の現在と未来
by
Hidekazu Oiwa
PDF
MS Officeファイル暗号化のマスター鍵を利用したバックドアとその対策
by
MITSUNARI Shigeo
PDF
楕円曲線入門 トーラスと楕円曲線のつながり
by
MITSUNARI Shigeo
PDF
Memory sanitizer
by
MITSUNARI Shigeo
PDF
暗号文のままで計算しよう - 準同型暗号入門 -
by
MITSUNARI Shigeo
PDF
『データ解析におけるプライバシー保護』勉強会
by
MITSUNARI Shigeo
PPTX
C言語超入門
by
Mercury Soft
PDF
GoogleのSHA-1のはなし
by
MITSUNARI Shigeo
PDF
Cプログラマのためのカッコつけないプログラミングの勧め
by
MITSUNARI Shigeo
PDF
強化学習その4
by
nishio
PDF
改ざん検知暗号Minalpherの設計とIvy Bridge/Haswellでの最適化
by
MITSUNARI Shigeo
PDF
Cybozu Tech Conference 2016 バグの調べ方
by
MITSUNARI Shigeo
PDF
Emcjp item33,34
by
MITSUNARI Shigeo
PDF
Emcjp item21
by
MITSUNARI Shigeo
PDF
『データ解析におけるプライバシー保護』勉強会 #2
by
MITSUNARI Shigeo
PDF
「ネットワークを作る」 ってどういうこと?
by
nishio
バックドア耐性のあるパスワード暗号化の提案
by
MITSUNARI Shigeo
Backdoors with the MS Office file encryption master key and a proposal for a ...
by
MITSUNARI Shigeo
Slide dist
by
MITSUNARI Shigeo
Wifiで位置推定
by
nishio
SGD+α: 確率的勾配降下法の現在と未来
by
Hidekazu Oiwa
MS Officeファイル暗号化のマスター鍵を利用したバックドアとその対策
by
MITSUNARI Shigeo
楕円曲線入門 トーラスと楕円曲線のつながり
by
MITSUNARI Shigeo
Memory sanitizer
by
MITSUNARI Shigeo
暗号文のままで計算しよう - 準同型暗号入門 -
by
MITSUNARI Shigeo
『データ解析におけるプライバシー保護』勉強会
by
MITSUNARI Shigeo
C言語超入門
by
Mercury Soft
GoogleのSHA-1のはなし
by
MITSUNARI Shigeo
Cプログラマのためのカッコつけないプログラミングの勧め
by
MITSUNARI Shigeo
強化学習その4
by
nishio
改ざん検知暗号Minalpherの設計とIvy Bridge/Haswellでの最適化
by
MITSUNARI Shigeo
Cybozu Tech Conference 2016 バグの調べ方
by
MITSUNARI Shigeo
Emcjp item33,34
by
MITSUNARI Shigeo
Emcjp item21
by
MITSUNARI Shigeo
『データ解析におけるプライバシー保護』勉強会 #2
by
MITSUNARI Shigeo
「ネットワークを作る」 ってどういうこと?
by
nishio
Similar to From IA-32 to avx-512
PDF
PFI Seminar 2010/02/18
by
Preferred Networks
PDF
d-kami x86-1
by
Daisuke Kamikawa
PDF
V6 unix in okinawa
by
magoroku Yamamoto
PDF
Boost.SIMD
by
Akira Takahashi
PDF
いでよ、電卓!
by
Masato Kinugawa
PDF
【学習メモ#3rd】12ステップで作る組込みOS自作入門
by
sandai
PDF
Intel AVX2を使用したailia sdkの最適化
by
HitoshiSHINABE1
PDF
Javaで作る超簡易x86エミュレータ
by
Daisuke Kamikawa
PPT
Altanative macro
by
Motohiro KOSAKI
KEY
core dumpでcode golf
by
Nomura Yusuke
PDF
ただのリンカを書いた話.pdf
by
simotin13 Miyazaki
PDF
Intel GoldmontとMPXとゆるふわなごや
by
Masaki Ota
PPTX
as-5. サブルーチン呼び出しのメカニズム
by
kunihikokaneko1
PPTX
as-4. 条件分岐と繰り返し
by
kunihikokaneko1
PDF
怪しいWindowsプログラミング
by
nagoya313
PDF
実行時のデータ型の表現手法
by
Atusi Maeda
PPT
d-kami x86-2
by
Daisuke Kamikawa
PPTX
ネイティブコードを語る
by
Kenji Imasaki
PDF
セキュアVMの構築 (IntelとAMDの比較、あともうひとつ...) - AVTokyo 2009
by
Tsukasa Oi
PPTX
アセンブラ100 さきゅりてぃ発表用
by
boropon
PFI Seminar 2010/02/18
by
Preferred Networks
d-kami x86-1
by
Daisuke Kamikawa
V6 unix in okinawa
by
magoroku Yamamoto
Boost.SIMD
by
Akira Takahashi
いでよ、電卓!
by
Masato Kinugawa
【学習メモ#3rd】12ステップで作る組込みOS自作入門
by
sandai
Intel AVX2を使用したailia sdkの最適化
by
HitoshiSHINABE1
Javaで作る超簡易x86エミュレータ
by
Daisuke Kamikawa
Altanative macro
by
Motohiro KOSAKI
core dumpでcode golf
by
Nomura Yusuke
ただのリンカを書いた話.pdf
by
simotin13 Miyazaki
Intel GoldmontとMPXとゆるふわなごや
by
Masaki Ota
as-5. サブルーチン呼び出しのメカニズム
by
kunihikokaneko1
as-4. 条件分岐と繰り返し
by
kunihikokaneko1
怪しいWindowsプログラミング
by
nagoya313
実行時のデータ型の表現手法
by
Atusi Maeda
d-kami x86-2
by
Daisuke Kamikawa
ネイティブコードを語る
by
Kenji Imasaki
セキュアVMの構築 (IntelとAMDの比較、あともうひとつ...) - AVTokyo 2009
by
Tsukasa Oi
アセンブラ100 さきゅりてぃ発表用
by
boropon
More from MITSUNARI Shigeo
PDF
深層学習フレームワークにおけるIntel CPU/富岳向け最適化法
by
MITSUNARI Shigeo
PDF
BLS署名の実装とその応用
by
MITSUNARI Shigeo
PDF
WebAssembly向け多倍長演算の実装
by
MITSUNARI Shigeo
PDF
暗認本読書会4
by
MITSUNARI Shigeo
PDF
暗号技術の実装と数学
by
MITSUNARI Shigeo
PDF
私とOSSの25年
by
MITSUNARI Shigeo
PDF
暗認本読書会13 advanced
by
MITSUNARI Shigeo
PDF
暗認本読書会6
by
MITSUNARI Shigeo
PDF
暗認本読書会12
by
MITSUNARI Shigeo
PDF
暗認本読書会11
by
MITSUNARI Shigeo
PDF
暗認本読書会7
by
MITSUNARI Shigeo
PDF
範囲証明つき準同型暗号とその対話的プロトコル
by
MITSUNARI Shigeo
PDF
集約署名
by
MITSUNARI Shigeo
PDF
楕円曲線と暗号
by
MITSUNARI Shigeo
PDF
Lifted-ElGamal暗号を用いた任意関数演算の二者間秘密計算プロトコルのmaliciousモデルにおける効率化
by
MITSUNARI Shigeo
PDF
暗認本読書会5
by
MITSUNARI Shigeo
PDF
暗認本読書会9
by
MITSUNARI Shigeo
PDF
暗認本読書会8
by
MITSUNARI Shigeo
PDF
暗認本読書会10
by
MITSUNARI Shigeo
PDF
LazyFP vulnerabilityの紹介
by
MITSUNARI Shigeo
深層学習フレームワークにおけるIntel CPU/富岳向け最適化法
by
MITSUNARI Shigeo
BLS署名の実装とその応用
by
MITSUNARI Shigeo
WebAssembly向け多倍長演算の実装
by
MITSUNARI Shigeo
暗認本読書会4
by
MITSUNARI Shigeo
暗号技術の実装と数学
by
MITSUNARI Shigeo
私とOSSの25年
by
MITSUNARI Shigeo
暗認本読書会13 advanced
by
MITSUNARI Shigeo
暗認本読書会6
by
MITSUNARI Shigeo
暗認本読書会12
by
MITSUNARI Shigeo
暗認本読書会11
by
MITSUNARI Shigeo
暗認本読書会7
by
MITSUNARI Shigeo
範囲証明つき準同型暗号とその対話的プロトコル
by
MITSUNARI Shigeo
集約署名
by
MITSUNARI Shigeo
楕円曲線と暗号
by
MITSUNARI Shigeo
Lifted-ElGamal暗号を用いた任意関数演算の二者間秘密計算プロトコルのmaliciousモデルにおける効率化
by
MITSUNARI Shigeo
暗認本読書会5
by
MITSUNARI Shigeo
暗認本読書会9
by
MITSUNARI Shigeo
暗認本読書会8
by
MITSUNARI Shigeo
暗認本読書会10
by
MITSUNARI Shigeo
LazyFP vulnerabilityの紹介
by
MITSUNARI Shigeo
From IA-32 to avx-512
1.
From IA-32 to
AVX-512 システムプログラミング会 2016/7/2 光成滋生
2.
• IA-32からAVX-512まで主にレジスタサイズの観点から ゆるゆると観察する小ネタ集 • SIMD成分は少なめ
m(_ _)m 概要 2/30
3.
• Intel初の32bit CPU •
8個の32bit汎用レジスタ eax, ebx, ecx, edx, esi, edi, ebp, esp • もともと8個の16-bit汎用レジスタを拡張したもの • eaxの下位16bitがax • axの下位8bitがal • レジスタ間はmovで移動 • これが全ての"始まり"かもしれない i386(Intel 386) eax ax alah ; eax = 0x99887766のとき mov al, 12h ; eax = 0x99887712, ax = 0x7712 mov ah, 34h ; eax = 0x99883412, ax = 0x3412 3/30
4.
• 命令のフォーマットの一つ • 8個のレジスタなので3bit •
src(ソース)とdst(デスティネーション)それぞれ必要 • レジスタ間のときはmod = 0b11 ModRM 7 6 5 4 3 2 1 0 +------+------+------+------+------+------+------+------+ | mod | src | reg | +------+------+------+------+------+------+------+------+ 4/30
5.
• 参考文献 • Intel
64 and IA-32 Architectures Software Developer’s Manual • mov eax, ecxならeax = 0, ecx = 1なので ModRM = 0b11 001 000 = 0xc8だから8b c8 movの場合 89 /r MOV r/m32,r32 MR ; Move r32 to r/m32 >cat test.asm mov eax, ecx >nasm -l a.lst -f win32 test.asm >cat a.lst 1 00000000 89C8 mov eax, ecx 5/30
6.
• 486DX • FPU内蔵タイプ •
8個の80bit浮動小数点数レジスタ st0, st1, ..., st7 • Pentium with MMX • 8個の64bit SIMDレジスタ mm0, ...., mm7 • 整数演算演算のみサポート • movd mm0, eaxなど • K6-2の3D Now! • AMDがMMXレジスタで浮動小数点数を扱えるように拡張 機能追加 6/30
7.
• 8個の128-bit SIMDレジスタ •
SSE<=>MMX間はmovdq2q, movq2dqなど • OSの対応が必要 • SSEレジスタの退避、復元が必要 • MMXレジスタはOSの対応は不要だった • なんで? • FPUと共用 • 代わりにemms, femmsが必要 • MMXで壊した状態でFPUを使う前にリセット SSE 7/30
8.
• elfバイナリに文字列を埋め込んでみる • https://github.com/herumi/misc/blob/master/emb/ •
構想20年 実装3時間w • 32bitバイナリa.outを用意する(手抜きで64bit不可) • a.outにhelloという文字列を埋め込んでembファイルを作る • もちろんembはa.outと同じ動きをする • embには"hello"が埋め込まれている 小ネタ >python embed-str.py a.out -o emb -s hello >python embed-str.py emb hello >python embed-str.py a.out // 何も表示されない 8/30
9.
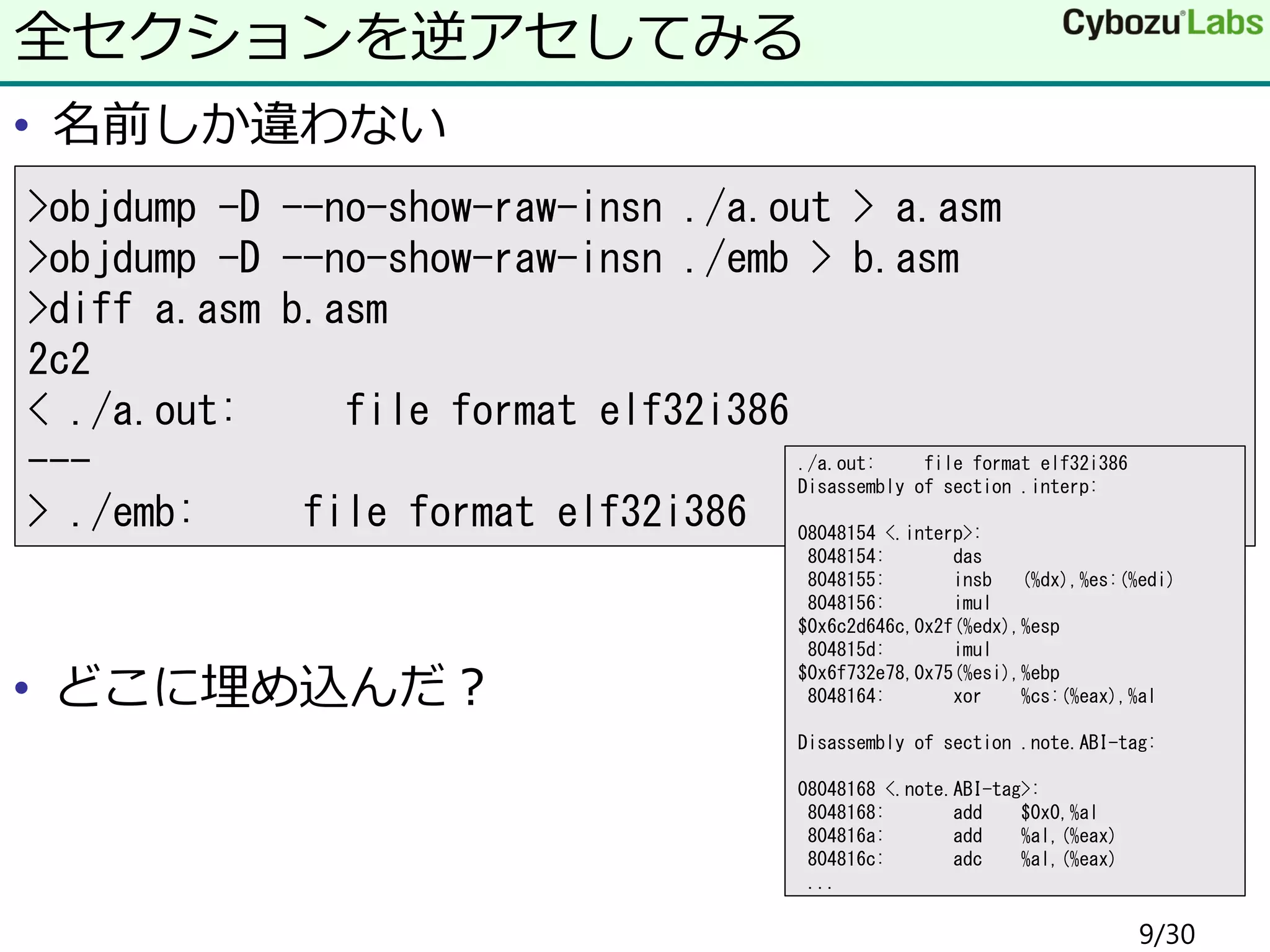
• 名前しか違わない • どこに埋め込んだ? 全セクションを逆アセしてみる >objdump
-D --no-show-raw-insn ./a.out > a.asm >objdump -D --no-show-raw-insn ./emb > b.asm >diff a.asm b.asm 2c2 < ./a.out: file format elf32i386 --- > ./emb: file format elf32i386 ./a.out: file format elf32i386 Disassembly of section .interp: 08048154 <.interp>: 8048154: das 8048155: insb (%dx),%es:(%edi) 8048156: imul $0x6c2d646c,0x2f(%edx),%esp 804815d: imul $0x6f732e78,0x75(%esi),%ebp 8048164: xor %cs:(%eax),%al Disassembly of section .note.ABI-tag: 08048168 <.note.ABI-tag>: 8048168: add $0x0,%al 804816a: add %al,(%eax) 804816c: adc %al,(%eax) ... 9/30
10.
• movのフォーマット • add,
adc, and, xor, or, sbb, sub, cmp, movなど • @shinhさんコメント • http://www1.cs.columbia.edu/~angelos/Papers/hydan.pdf オペランドによって複数の種類がる 89 /r MOV r/m32,r32 MR ; Move r32 to r/m32 8B /r MOV r32,r/m32 RM ; Move r/m32 to r32 89C8 mov eax, ecx 8BC1 mov eax, ecx 10/30
11.
• axを操作したあとeaxを使うとペナルティ • 依存関係を切る •
Pentum Pro以降のパイプラインの深くなったCPUで発生 • 最近はそれほど気にしなくてもよいかも • movzxで0拡張するかして幅を揃えるようにする パーシャルレジスタストール mov eax, [esi] mov al, 3 mov ecx, eax ; ペナルティ 11/30
12.
• 16個の64bit汎用レジスタ(r8, ...,
r15) • レジスタを特定するには4bit必要 • ModRMでは1bit足りない • rexプレフィクス登場 x64 7 6 5 4 3 2 1 0 +------+------+------+------+------+------+------+------+ | 0 1 0 0 | REX.w| REX.r| REX.x| REX.b| +------+------+------+------+------+------+------+------+ mov <b>, <r> ; b = [b3:b2:b1:b0], r = [r3:r2:r1:r0] | 0 1 0 0 | 1 !r3 0 !b3 | 0x89 | 1 1 b2 b1 b0 r2 r1 r0| 12/30
13.
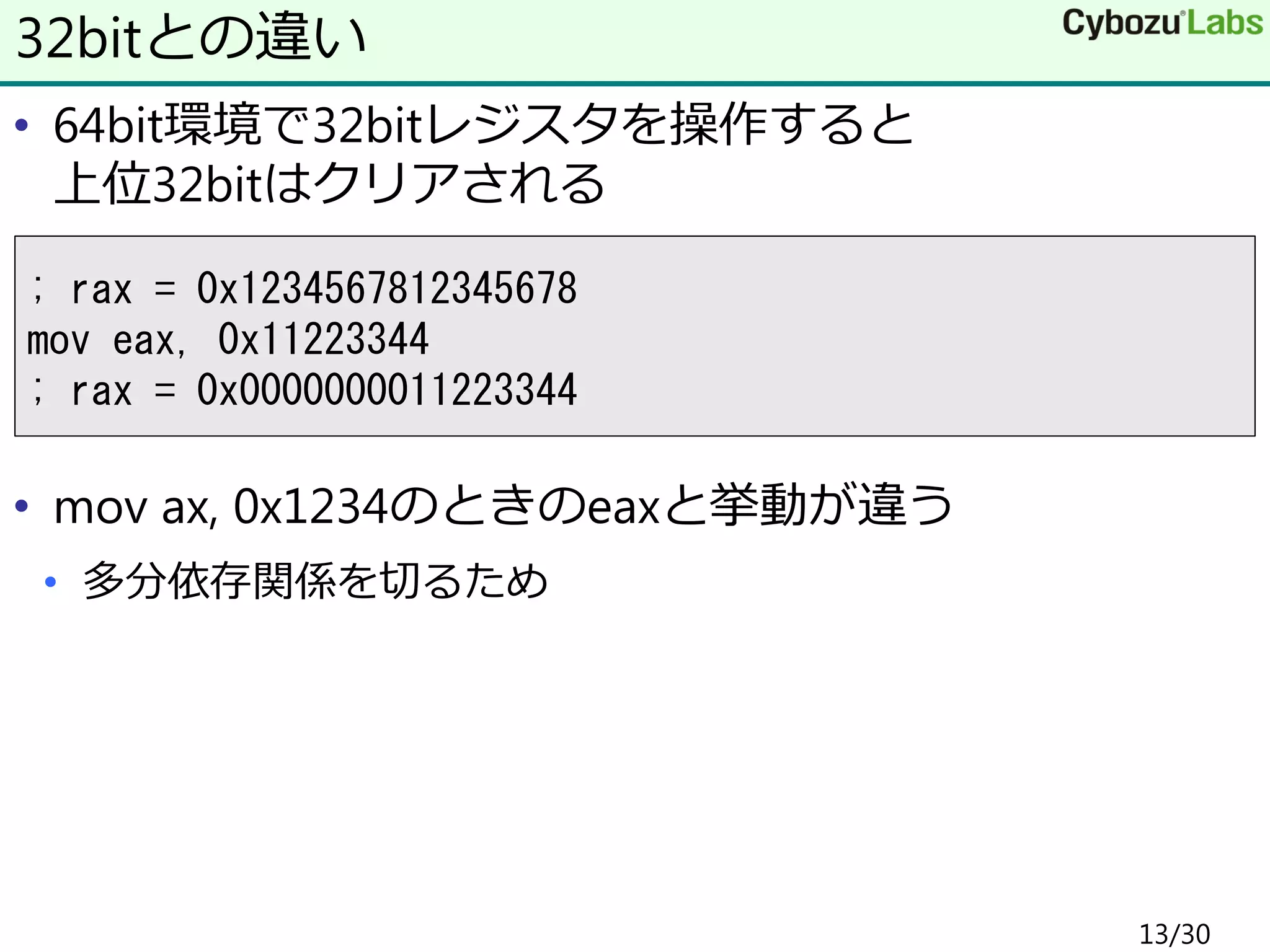
• 64bit環境で32bitレジスタを操作すると 上位32bitはクリアされる • mov
ax, 0x1234のときのeaxと挙動が違う • 多分依存関係を切るため 32bitとの違い ; rax = 0x1234567812345678 mov eax, 0x11223344 ; rax = 0x0000000011223344 13/30
14.
• 何もしない命令(0x90) • 32bit時代はxchg
eax, eaxのエリアス • 64bit自体はeaxの上位がクリアされてしまう! • NOP = 0x90と定義 • mov eax, eaxも同様 • movzx, eax, al(ゼロ拡張と同じ動き) • コンパイラの生成コードを見て 無駄なことしてるなと勘違いしないように NOP 14/30
15.
• 16個の256bit SIMDレジスタ(ymm0,
..., ymm15) • 下位128bitは xmmレジスタでアクセス • 3オペランドの命令体系 • addpd ymm0, ymm1, ymm2 • VEXプレフィクス • レジスタ指定に4bit x 3 + 1(xmmかymmか) = 13bit必要 • かなりややこしい AVX, AVX2 3byte VEX |7 6 5 4 3 2 1 0| |7 6 5 4 3 2 1 0| <code> ModRM... 0xC4 |R|X|B|m-m m m m| |W|v v v v|L|p p| 15/30
16.
• SSEの命令はymmレジスタの上位をクリアしない レガシーSSEとAVX addpd xmm0,
xmm1 ; ymm0の上位は変化せず vaddpd xmm0, xmm0, xmm1 ; ymm0の上位はクリア 16/30
17.
• fmath(https://github.com/herumi/fmath) • 高速なexpの近似計算 •
http://www.slideshare.net/herumi/exp-9499790 • 性能劣化 • VS2012からVS2013にしたときに標準関数が遅くなる場面 • もちろん普通に使うと速い 悩んだ問題 VS2012 VS2013 std::exp 62.2 349.8 fmath::exp 33.8 33.0 17/30
18.
• ループ回数が7だと遅くならない • mainでaの値は使われない 最小限のコード(当時) const
struct A { float a[8]; A() { const float x = log(2.0f); for (int i = 0; i < 8; i++) a[i] = x; } } a; int main() { ここでstd::expを関数ポインタ経由で呼び出すと遅くなる } 18/30
19.
• 発現条件 • VC2013は8回のループを展開し vinsertf128というAVXの1命令に置き換えた •
std::expはレガシーなSSEで書かれていた • 理由 • ymmレジスタの上位が0クリアでないと認識されて ペナルティを食らっていた • 解決方法 • コンパイラのバグ(もちろん修正済み) • AVXを使った後SSEを使う可能性があるときはvzeroupperで ゼロクリアしなければならない • ただ混在しないようにするのが理想 • 遅くなる関数自体には問題がないので分かりにくい 何が起こっていたのか 19/30
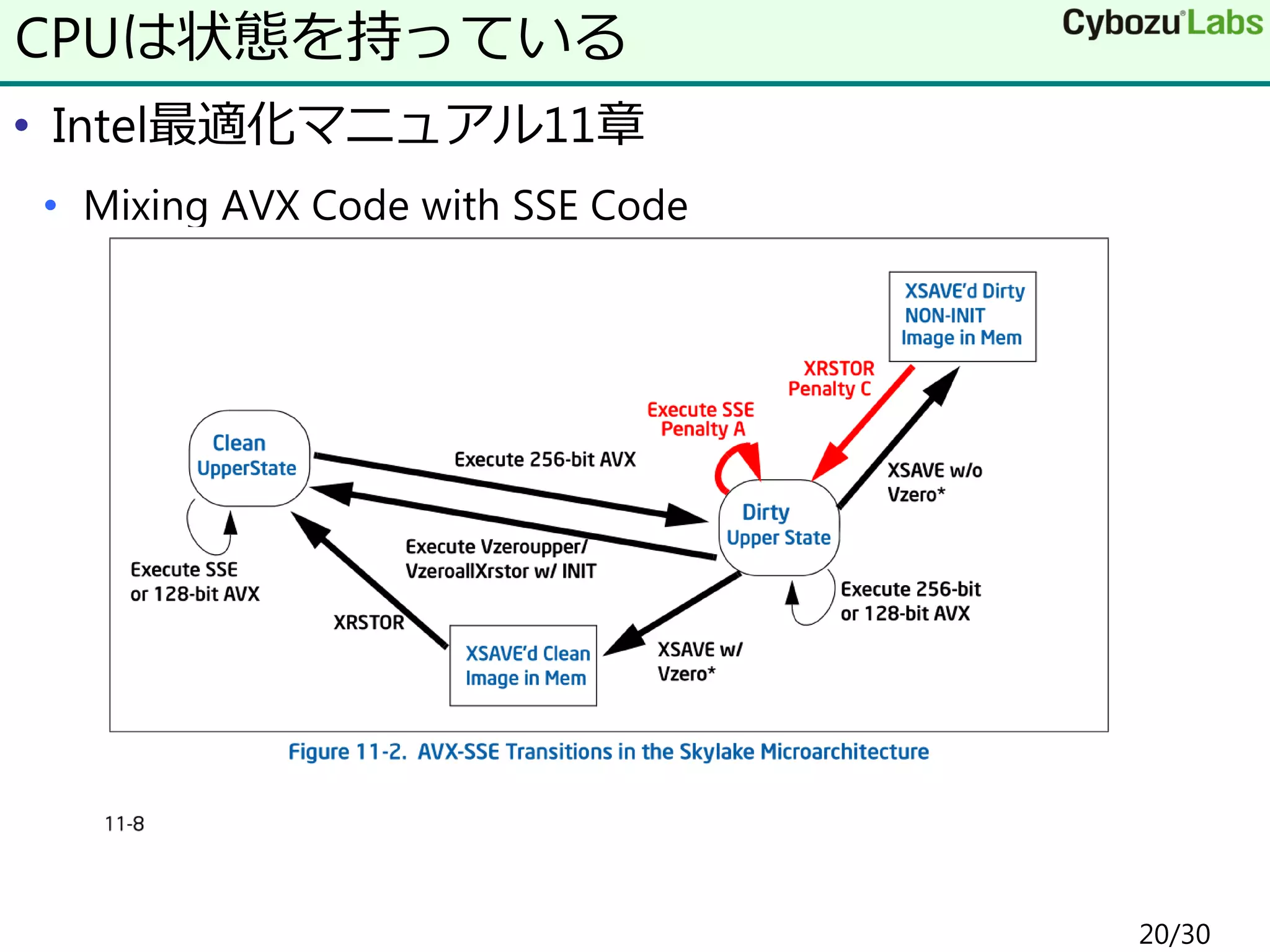
20.
• Intel最適化マニュアル11章 • Mixing
AVX Code with SSE Code CPUは状態を持っている 20/30
21.
• Intelのエミュレータ • https://software.intel.com/en-us/articles/pre-release-license- agreement-for-intel-software-development-emulator-accept- end-user-license-agreement-and-download 検出ツール vzeroupperなし sde
-ast -- nonzero-upper-penalty.exe # AVX_to_SSE_transition_instances: 102 # SSE_to_AVX_transition_instances: 102 vzeroupperあり sde -ast -- nonzero-upper-penalty.exe 1 # AVX_to_SSE_transition_instances: 0 # SSE_to_AVX_transition_instances: 0 21/30
22.
• https://github.com/herumi/opti/blob/master/nonzero-upper- penalty.cpp • vzeroupperを呼ばないと1.8倍ぐらい遅くなる サンプル struct
Code : public Xbyak::CodeGenerator { explicit Code(bool clear) { vxorpd(ym0, ym0); if (clear) vzeroupper(); mov(eax, N); L("@@"); addpd(xm0, xm0); sub(eax, 1); jnz("@b"); ret(); } }; 22/30
23.
• Intel 64
and IA-32 Architectures Software Developer's Manual, Volume 3 System Programming Guide • 19章Performance-Monitoring Events Linuxのperf Event Umask mnemonic 説明 C1h 08h OTHER_ASSISTS.AVX_TO_SSE AVX-256からSSEへの切り替え回数 C1h 10h OTHER_ASSISTS.SSE_TO_AVX SSEからAVX-256への切り替え回数 perf stat -e r08c1 -e r10c1 ./nonzero-upper-penalty Performance counter stats for './ nonzero-upper-penalty ': 10000001 r08c1 9999978 r10c1 23/30
24.
• 32個の512bit SIMDレジスタ(zmm0,
..., zmm31) • 5bit x 3 + 2(XかYかZか)= 17bit必要 • VEXでは足りないのでEVEX • 7個の64bitマスクレジスタ(k0, ..., k7) • 演算結果の一部をゼロにしたりできる • 指定が自由にできる • マスクレジスタ自体多少の演算ができる • kaddw k1, k2, k3 ; kshiftlq k1, k2, 5 ; etc. • 命令ごとに丸め方法を指定できる • nearest, toward -inf, toward +inf, round to zero • AVX-512は○オペランド? AVX-512 24/30
25.
• 3オペランド? • 丸め方法の指定 •
マスクレジスタの指定 • ゼロで埋めるか 例 vaddpd zmm10, zmm20, zmm30 vaddpd zmm10, zmm20, zmm30, {rd-sae} vaddpd zmm10{k2}, zmm20, zmm30, {rd-sae} vaddpd zmm10{k2}{z}, zmm20, zmm30, {rd-sae} 25/30
26.
• とてもややこしい EVEX | EVEX
| |0x62 P0 P1 P2| opcode ModRM/M [SIB] [Disp] [Imm] | 7 6 5 4 3 2 1 0 | P0 | R | X | B | R'| 0 | 0 | m | m | P1 | W | v | v | v | v | 1 | p | p | P2 | z | L'| L | b | V'| a | a | a | vaddpd [a4 a3 a2 a1 a0],[b4 b3 b2 b1 b0],[c4 c3 c2 c1 c0] 0x62|!a3 !c4 !c3 !a4 0001|1 b3 b2 b1 b0 101|0100 !b4 aaa| <code> |11 a2 a1 a0 c2 c1 c0| ... 26/30
27.
• zmm0=[8:7:6:5:4:3:2:1], [rax]
= [2:1]のときどうなるか ゼロクリアクイズ(問題) 命令 意味 結果 movsd xmm0, xmm0 最下位doubleを移動 movsd xmm0, [rax] 最下位doubleを移動 vmovsd xmm0, xmm0, xmm0 最下位doubleを移動 vmovsd xmm0, [rax] 最下位doubleを移動 addsd xmm0, xmm0 最下位doubleを加算 addpd xmm0, xmm0 double x 2を加算 vaddsd xmm0, xmm0, xmm0 最下位doubleを加算 vaddpd xmm0, xmm0, xmm0 double x 2を加算 vaddpd ymm0, ymm0, ymm0 double x 4を加算 27/30
28.
命令 意味 効果 movsd
xmm0, xmm0 最下位doubleを移動 [8:7:6:5:4:3:2:1] movsd xmm0, [rax] 最下位doubleを移動 [8:7:6:5:4:3:0:1] vmovsd xmm0, xmm0, xmm0 最下位doubleを移動 [0:0:0:0:0:0:2:1] vmovsd xmm0, [rax] 最下位doubleを移動 [0:0:0:0:0:0:0:1] addsd xmm0, xmm0 最下位doubleを加算 [8:7:6:5:4:3:2:2] addpd xmm0, xmm0 double x 2を加算 [8:7:6:5:4:3:4:2] vaddsd xmm0, xmm0, xmm0 最下位doubleを加算 [0:0:0:0:0:0:2:2] vaddpd xmm0, xmm0, xmm0 double x 2を加算 [0:0:0:0:0:0:4:2] vaddpd ymm0, ymm0, ymm0 double x 4を加算 [0:0:0:0:8:6:4:2] ゼロクリアクイズ(答え) • zmm0=[8:7:6:5:4:3:2:1], [rax] = [2:1]のときどうなるか • https://github.com/herumi/opti/tree/master/upper-zero 28/30
29.
• 512bit x
32 = 2048byte = 2KiB! • コンテキストスイッチの度に全部保存? • xsaveopt, xsavec • Vol. 1 13章「Managing State Using the XSAVE Feature Set」 • メモリコピーを減らす仕組み • 各レジスタが変更されたか否かのビット情報を保持 • その情報にしたがって必要なものだけ退避する命令 レジスタの退避・復元 29/30
30.
• SIMDはテーブル引きに弱い • Haswellで登場(しかし使わない方が速いぐらいだった) •
Skylakeでかなり改善された • AVX-512ではマスクレジスタが登場して大分使いやすくなっ た(ようだ) (おまけ)高速化されたgather命令 int tbl[16]; double a[16], b[16]; for (int i = 0; i < 16; i++) { b[i] = a[tbl[i]]; } vmovdqu zmm0, [rsp + tbl] kxnor k1, k0, k0 ; 全部1をたてる(c ← !(a ^ b)) vpgatherdd zmm2{k1}, [rax + zmm0 * 4] 30/30
Download










![• axを操作したあとeaxを使うとペナルティ
• 依存関係を切る
• Pentum Pro以降のパイプラインの深くなったCPUで発生
• 最近はそれほど気にしなくてもよいかも
• movzxで0拡張するかして幅を揃えるようにする
パーシャルレジスタストール
mov eax, [esi]
mov al, 3
mov ecx, eax ; ペナルティ
11/30](https://image.slidesharecdn.com/ia-32toavx-512-160703105051/75/From-IA-32-to-avx-512-11-2048.jpg)
![• 16個の64bit汎用レジスタ(r8, ..., r15)
• レジスタを特定するには4bit必要
• ModRMでは1bit足りない
• rexプレフィクス登場
x64
7 6 5 4 3 2 1 0
+------+------+------+------+------+------+------+------+
| 0 1 0 0 | REX.w| REX.r| REX.x| REX.b|
+------+------+------+------+------+------+------+------+
mov <b>, <r> ; b = [b3:b2:b1:b0], r = [r3:r2:r1:r0]
| 0 1 0 0 | 1 !r3 0 !b3 | 0x89 | 1 1 b2 b1 b0 r2 r1 r0|
12/30](https://image.slidesharecdn.com/ia-32toavx-512-160703105051/75/From-IA-32-to-avx-512-12-2048.jpg)




![• ループ回数が7だと遅くならない
• mainでaの値は使われない
最小限のコード(当時)
const struct A {
float a[8];
A() {
const float x = log(2.0f);
for (int i = 0; i < 8; i++) a[i] = x;
}
} a;
int main() {
ここでstd::expを関数ポインタ経由で呼び出すと遅くなる
}
18/30](https://image.slidesharecdn.com/ia-32toavx-512-160703105051/75/From-IA-32-to-avx-512-18-2048.jpg)






![• とてもややこしい
EVEX
| EVEX |
|0x62 P0 P1 P2| opcode ModRM/M [SIB] [Disp] [Imm]
| 7 6 5 4 3 2 1 0 |
P0 | R | X | B | R'| 0 | 0 | m | m |
P1 | W | v | v | v | v | 1 | p | p |
P2 | z | L'| L | b | V'| a | a | a |
vaddpd [a4 a3 a2 a1 a0],[b4 b3 b2 b1 b0],[c4 c3 c2 c1 c0]
0x62|!a3 !c4 !c3 !a4 0001|1 b3 b2 b1 b0 101|0100 !b4 aaa|
<code> |11 a2 a1 a0 c2 c1 c0| ...
26/30](https://image.slidesharecdn.com/ia-32toavx-512-160703105051/75/From-IA-32-to-avx-512-26-2048.jpg)
![• zmm0=[8:7:6:5:4:3:2:1], [rax] = [2:1]のときどうなるか
ゼロクリアクイズ(問題)
命令 意味 結果
movsd xmm0, xmm0 最下位doubleを移動
movsd xmm0, [rax] 最下位doubleを移動
vmovsd xmm0, xmm0, xmm0 最下位doubleを移動
vmovsd xmm0, [rax] 最下位doubleを移動
addsd xmm0, xmm0 最下位doubleを加算
addpd xmm0, xmm0 double x 2を加算
vaddsd xmm0, xmm0, xmm0 最下位doubleを加算
vaddpd xmm0, xmm0, xmm0 double x 2を加算
vaddpd ymm0, ymm0, ymm0 double x 4を加算
27/30](https://image.slidesharecdn.com/ia-32toavx-512-160703105051/75/From-IA-32-to-avx-512-27-2048.jpg)
![命令 意味 効果
movsd xmm0, xmm0 最下位doubleを移動 [8:7:6:5:4:3:2:1]
movsd xmm0, [rax] 最下位doubleを移動 [8:7:6:5:4:3:0:1]
vmovsd xmm0, xmm0, xmm0 最下位doubleを移動 [0:0:0:0:0:0:2:1]
vmovsd xmm0, [rax] 最下位doubleを移動 [0:0:0:0:0:0:0:1]
addsd xmm0, xmm0 最下位doubleを加算 [8:7:6:5:4:3:2:2]
addpd xmm0, xmm0 double x 2を加算 [8:7:6:5:4:3:4:2]
vaddsd xmm0, xmm0, xmm0 最下位doubleを加算 [0:0:0:0:0:0:2:2]
vaddpd xmm0, xmm0, xmm0 double x 2を加算 [0:0:0:0:0:0:4:2]
vaddpd ymm0, ymm0, ymm0 double x 4を加算 [0:0:0:0:8:6:4:2]
ゼロクリアクイズ(答え)
• zmm0=[8:7:6:5:4:3:2:1], [rax] = [2:1]のときどうなるか
• https://github.com/herumi/opti/tree/master/upper-zero
28/30](https://image.slidesharecdn.com/ia-32toavx-512-160703105051/75/From-IA-32-to-avx-512-28-2048.jpg)

![• SIMDはテーブル引きに弱い
• Haswellで登場(しかし使わない方が速いぐらいだった)
• Skylakeでかなり改善された
• AVX-512ではマスクレジスタが登場して大分使いやすくなっ
た(ようだ)
(おまけ)高速化されたgather命令
int tbl[16];
double a[16], b[16];
for (int i = 0; i < 16; i++) {
b[i] = a[tbl[i]];
}
vmovdqu zmm0, [rsp + tbl]
kxnor k1, k0, k0 ; 全部1をたてる(c ← !(a ^ b))
vpgatherdd zmm2{k1}, [rax + zmm0 * 4]
30/30](https://image.slidesharecdn.com/ia-32toavx-512-160703105051/75/From-IA-32-to-avx-512-30-2048.jpg)























































































