Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
MITSUNARI Shigeo
3,129 views
『データ解析におけるプライバシー保護』勉強会
1, 2, 6章
Technology
◦
Related topics:
Data Analytics Insights
•
Read more
4
Save
Share
Embed
Embed presentation
Download
Downloaded 31 times
1
/ 27
2
/ 27
3
/ 27
4
/ 27
5
/ 27
6
/ 27
7
/ 27
8
/ 27
9
/ 27
10
/ 27
11
/ 27
12
/ 27
13
/ 27
14
/ 27
15
/ 27
16
/ 27
17
/ 27
18
/ 27
19
/ 27
20
/ 27
21
/ 27
22
/ 27
23
/ 27
24
/ 27
25
/ 27
26
/ 27
27
/ 27
More Related Content
PPTX
差分プライバシーとは何か? (定義 & 解釈編)
by
Kentaro Minami
PDF
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
PDF
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PDF
ファクター投資と機械学習
by
Kei Nakagawa
PDF
機械学習モデルの判断根拠の説明
by
Satoshi Hara
PDF
最近のディープラーニングのトレンド紹介_20200925
by
小川 雄太郎
差分プライバシーとは何か? (定義 & 解釈編)
by
Kentaro Minami
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
ファクター投資と機械学習
by
Kei Nakagawa
機械学習モデルの判断根拠の説明
by
Satoshi Hara
最近のディープラーニングのトレンド紹介_20200925
by
小川 雄太郎
What's hot
PDF
SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向
by
SSII
PDF
“機械学習の説明”の信頼性
by
Satoshi Hara
PDF
pymcとpystanでベイズ推定してみた話
by
Classi.corp
PDF
パターン認識と機械学習入門
by
Momoko Hayamizu
PDF
[DL輪読会]Deep Learning 第2章 線形代数
by
Deep Learning JP
PDF
多人数不完全情報ゲームにおけるAI ~ポーカーと麻雀を例として~
by
Kenshi Abe
PDF
生成モデルの Deep Learning
by
Seiya Tokui
PDF
暗号文のままで計算しよう - 準同型暗号入門 -
by
MITSUNARI Shigeo
PDF
4 データ間の距離と類似度
by
Seiichi Uchida
PDF
負の二項分布について
by
Hiroshi Shimizu
PDF
Bayesian Neural Networks : Survey
by
tmtm otm
PDF
深層生成モデルと世界モデル(2020/11/20版)
by
Masahiro Suzuki
PDF
数学カフェ 確率・統計・機械学習回 「速習 確率・統計」
by
Ken'ichi Matsui
PDF
ブラックボックス最適化とその応用
by
gree_tech
PDF
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
PPTX
【DL輪読会】Flow Matching for Generative Modeling
by
Deep Learning JP
PDF
AIによるアニメ生成の挑戦
by
Koichi Hamada
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PDF
【DL輪読会】マルチエージェント強化学習における近年の 協調的方策学習アルゴリズムの発展
by
Deep Learning JP
PDF
20160417dlibによる顔器官検出
by
Takuya Minagawa
SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向
by
SSII
“機械学習の説明”の信頼性
by
Satoshi Hara
pymcとpystanでベイズ推定してみた話
by
Classi.corp
パターン認識と機械学習入門
by
Momoko Hayamizu
[DL輪読会]Deep Learning 第2章 線形代数
by
Deep Learning JP
多人数不完全情報ゲームにおけるAI ~ポーカーと麻雀を例として~
by
Kenshi Abe
生成モデルの Deep Learning
by
Seiya Tokui
暗号文のままで計算しよう - 準同型暗号入門 -
by
MITSUNARI Shigeo
4 データ間の距離と類似度
by
Seiichi Uchida
負の二項分布について
by
Hiroshi Shimizu
Bayesian Neural Networks : Survey
by
tmtm otm
深層生成モデルと世界モデル(2020/11/20版)
by
Masahiro Suzuki
数学カフェ 確率・統計・機械学習回 「速習 確率・統計」
by
Ken'ichi Matsui
ブラックボックス最適化とその応用
by
gree_tech
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
【DL輪読会】Flow Matching for Generative Modeling
by
Deep Learning JP
AIによるアニメ生成の挑戦
by
Koichi Hamada
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
【DL輪読会】マルチエージェント強化学習における近年の 協調的方策学習アルゴリズムの発展
by
Deep Learning JP
20160417dlibによる顔器官検出
by
Takuya Minagawa
Viewers also liked
PDF
『データ解析におけるプライバシー保護』勉強会 #2
by
MITSUNARI Shigeo
PDF
Cybozu Tech Conference 2016 バグの調べ方
by
MITSUNARI Shigeo
PDF
プライバシー保護のためのサンプリング、k-匿名化、そして差分プライバシー
by
Hiroshi Nakagawa
PDF
差分プライバシーによる時系列データの扱い方
by
Hiroshi Nakagawa
PDF
居場所を隠すために差分プライバシーを使おう
by
Hiroshi Nakagawa
PDF
情報ネットワーク法学会2017大会第8分科会発表資料
by
Hiroshi Nakagawa
『データ解析におけるプライバシー保護』勉強会 #2
by
MITSUNARI Shigeo
Cybozu Tech Conference 2016 バグの調べ方
by
MITSUNARI Shigeo
プライバシー保護のためのサンプリング、k-匿名化、そして差分プライバシー
by
Hiroshi Nakagawa
差分プライバシーによる時系列データの扱い方
by
Hiroshi Nakagawa
居場所を隠すために差分プライバシーを使おう
by
Hiroshi Nakagawa
情報ネットワーク法学会2017大会第8分科会発表資料
by
Hiroshi Nakagawa
Similar to 『データ解析におけるプライバシー保護』勉強会
PDF
PPDM-2006
by
Hiroshi Nakagawa
PDF
17.01.18_論文紹介_Discrimination- and privacy-aware patterns
by
LINE Corp.
PDF
『データ解析におけるプライバシー保護』勉強会 秘密計算
by
MITSUNARI Shigeo
PPT
Provable Security2
by
Satoshi Hada
PDF
差分プライベート最小二乗密度比推定
by
Hiroshi Nakagawa
PDF
経済学のための実践的データ分析 3.データの可用性とプライバシー
by
Yasushi Hara
PPTX
学術会議 ITシンポジウム資料「プライバシー保護技術の概観と展望」
by
Hiroshi Nakagawa
PPTX
数式を使わないプライバシー保護技術
by
Hiroshi Nakagawa
ODP
安全なデータ公開のために
by
Tsugio Wakamatsu
PDF
プライバシを考慮した移動系列情報解析のための安全性の提案
by
Junpei Kawamoto
PPTX
情報検索における質問者の プライバシー保護 :Private Information Retrieval
by
Hiroshi Nakagawa
PPT
VLDB09勉強会 Session27 Privacy2
by
Junpei Kawamoto
PDF
Deep learning _linear_algebra___probablity___information
by
takutori
PDF
[DL輪読会]Semi-supervised Knowledge Transfer for Deep Learning from Private Trai...
by
Deep Learning JP
PPT
Provable Security1
by
Satoshi Hada
PPT
Provable Security3
by
Satoshi Hada
PPT
R04 Security II
by
Chiemi Watanabe
PDF
データベース設計徹底指南
by
Mikiya Okuno
PPTX
Information retrieval model
by
Yuku Takahashi
PDF
安全なデータ公開のために
by
Wakamatz
PPDM-2006
by
Hiroshi Nakagawa
17.01.18_論文紹介_Discrimination- and privacy-aware patterns
by
LINE Corp.
『データ解析におけるプライバシー保護』勉強会 秘密計算
by
MITSUNARI Shigeo
Provable Security2
by
Satoshi Hada
差分プライベート最小二乗密度比推定
by
Hiroshi Nakagawa
経済学のための実践的データ分析 3.データの可用性とプライバシー
by
Yasushi Hara
学術会議 ITシンポジウム資料「プライバシー保護技術の概観と展望」
by
Hiroshi Nakagawa
数式を使わないプライバシー保護技術
by
Hiroshi Nakagawa
安全なデータ公開のために
by
Tsugio Wakamatsu
プライバシを考慮した移動系列情報解析のための安全性の提案
by
Junpei Kawamoto
情報検索における質問者の プライバシー保護 :Private Information Retrieval
by
Hiroshi Nakagawa
VLDB09勉強会 Session27 Privacy2
by
Junpei Kawamoto
Deep learning _linear_algebra___probablity___information
by
takutori
[DL輪読会]Semi-supervised Knowledge Transfer for Deep Learning from Private Trai...
by
Deep Learning JP
Provable Security1
by
Satoshi Hada
Provable Security3
by
Satoshi Hada
R04 Security II
by
Chiemi Watanabe
データベース設計徹底指南
by
Mikiya Okuno
Information retrieval model
by
Yuku Takahashi
安全なデータ公開のために
by
Wakamatz
More from MITSUNARI Shigeo
PDF
暗号技術の実装と数学
by
MITSUNARI Shigeo
PDF
範囲証明つき準同型暗号とその対話的プロトコル
by
MITSUNARI Shigeo
PDF
暗認本読書会13 advanced
by
MITSUNARI Shigeo
PDF
暗認本読書会12
by
MITSUNARI Shigeo
PDF
暗認本読書会11
by
MITSUNARI Shigeo
PDF
暗認本読書会10
by
MITSUNARI Shigeo
PDF
暗認本読書会9
by
MITSUNARI Shigeo
PDF
Intel AVX-512/富岳SVE用SIMDコード生成ライブラリsimdgen
by
MITSUNARI Shigeo
PDF
暗認本読書会8
by
MITSUNARI Shigeo
PDF
暗認本読書会7
by
MITSUNARI Shigeo
PDF
暗認本読書会6
by
MITSUNARI Shigeo
PDF
暗認本読書会5
by
MITSUNARI Shigeo
PDF
暗認本読書会4
by
MITSUNARI Shigeo
PDF
深層学習フレームワークにおけるIntel CPU/富岳向け最適化法
by
MITSUNARI Shigeo
PDF
私とOSSの25年
by
MITSUNARI Shigeo
PDF
WebAssembly向け多倍長演算の実装
by
MITSUNARI Shigeo
PDF
Lifted-ElGamal暗号を用いた任意関数演算の二者間秘密計算プロトコルのmaliciousモデルにおける効率化
by
MITSUNARI Shigeo
PDF
楕円曲線と暗号
by
MITSUNARI Shigeo
PDF
HPC Phys-20201203
by
MITSUNARI Shigeo
PDF
BLS署名の実装とその応用
by
MITSUNARI Shigeo
暗号技術の実装と数学
by
MITSUNARI Shigeo
範囲証明つき準同型暗号とその対話的プロトコル
by
MITSUNARI Shigeo
暗認本読書会13 advanced
by
MITSUNARI Shigeo
暗認本読書会12
by
MITSUNARI Shigeo
暗認本読書会11
by
MITSUNARI Shigeo
暗認本読書会10
by
MITSUNARI Shigeo
暗認本読書会9
by
MITSUNARI Shigeo
Intel AVX-512/富岳SVE用SIMDコード生成ライブラリsimdgen
by
MITSUNARI Shigeo
暗認本読書会8
by
MITSUNARI Shigeo
暗認本読書会7
by
MITSUNARI Shigeo
暗認本読書会6
by
MITSUNARI Shigeo
暗認本読書会5
by
MITSUNARI Shigeo
暗認本読書会4
by
MITSUNARI Shigeo
深層学習フレームワークにおけるIntel CPU/富岳向け最適化法
by
MITSUNARI Shigeo
私とOSSの25年
by
MITSUNARI Shigeo
WebAssembly向け多倍長演算の実装
by
MITSUNARI Shigeo
Lifted-ElGamal暗号を用いた任意関数演算の二者間秘密計算プロトコルのmaliciousモデルにおける効率化
by
MITSUNARI Shigeo
楕円曲線と暗号
by
MITSUNARI Shigeo
HPC Phys-20201203
by
MITSUNARI Shigeo
BLS署名の実装とその応用
by
MITSUNARI Shigeo
『データ解析におけるプライバシー保護』勉強会
1.
『データ解析における プライバシー保護』 (佐久間淳)1, 2, 6章 2016/9/23 光成滋生
2.
• 『データ解析におけるプライバシー保護技術』 Privacy Preservation
in Data Analytics 以降、略してPPinDA • 大きく三つのPP技術を紹介する本 • 仮名化・匿名化 • 2~5章 • 差分プライバシー • 7~9章 • 秘密計算 • 10~14章 • 6章は攻撃者モデル • とりあえず1~2章→6章→7~9章のあと残りを順に 概要 2/27
3.
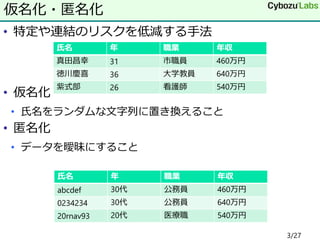
• 特定や連結のリスクを低減する手法 • 仮名化 •
氏名をランダムな文字列に置き換えること • 匿名化 • データを曖昧にすること 仮名化・匿名化 氏名 年 職業 年収 真田昌幸 31 市職員 460万円 徳川慶喜 36 大学教員 640万円 紫式部 26 看護師 540万円 氏名 年 職業 年収 abcdef 30代 公務員 460万円 0234234 30代 公務員 640万円 20rnav93 20代 医療職 540万円 3/27
4.
• 第三者に提供するプライバシー保護技術(PP) • データの1行が個人を表すデータベース(DB
) • 攻撃者 • 個人を特定しようとするデータ取得者 • 特定 • DBの各行がどの人物のものかを結びつけること • 連結 • ある人物を表す行と同一人物の別のデータを結びつけること 三つの技術の概要 4/27
5.
• 背景 • DBの様々な統計量を提供すると 個別の人物の情報が推測されるリスクがある •
例: • 攻撃者の背景知識「全体でN人で看護師は紫式部だけ」 • このとき次の統計量クエリを投げる • Q1. 全員の平均年収は? • Q2. 看護師以外の全員の平均年収は? • すると紫式部の年収が分かる 差分プライバシー(1/2) 5/27
6.
• 統計量が得たときに攻撃者の背景知識にかかわらず 個人の情報が推測化されるリスクを定量評価するため の基準を与える • 攻撃者の推測を妨げる手段を提供する •
先ほどの例 • Q1, Q2の返事にノイズを加えて答える 差分プライバシー(2/2) 6/27
7.
• DBが複数の機関に分散して存在しているとき個別の DBを互いに共有することなく秘密性を保ったまま 統計解析や機械学習などの計算の結果のみを取得する • DB1とDB2それぞれ別の機関が保持 •
両機関が互いに名前を見せずにこんな表を作りたい • 差分プライバシーの技法は別途必要 秘密計算によるデータ解析 氏名 肺癌の有無 真田昌幸 あり 徳川慶喜 なし 紫式部 なし ... ... 氏名 喫煙の有無 真田昌幸 なし 徳川慶喜 あり 紫式部 あり ... ... 喫煙歴なし あり 肺癌なし 1233 837 肺癌あり 715 642 7/27
8.
• 個人情報 • 日本の個人情報保護法における個人情報 •
生存する個人に関する情報で、当該情報に含まれる氏名、 生年月日その他の記述などで特定の個人を識別できるもの • 他の情報と容易に照合できて特定の個人を識別できるもの • メールアドレス、SNSのアカウントなどが個人情報か どうかは明確でない • プライバシー上の問題が存在する種類の情報もある • パーソナルデータという 2章データ提供におけるプライバシー問題 8/27
9.
• 特定 • ある個人と一意に結びつく情報(マイナンバー、運転免許番 号など)が除外されて個人を特定できないデータから、 そのデータを該当する個人と再び結びつけること •
連結 • ある個人のデータを同一人物の別のデータと結びつけること • 個人が特定されていないこともある • 属性推定 • ある個人のデータの一部が削除されているときに そのデータを復元、推定すること • 個人が特定されていないこともある プライバシーの問題(1/2) 9/27
10.
• 連絡 • あるデータをもつ人がその個人に連絡すること •
訪問、郵便物を送る、電話をかける、メールを送るなど • 特定=連絡のときもある • 直接被害 • あるデータをもつ人がその個人に直接的な被害を与えること • クレジット番号の無断使用、SNSのなりすましなど • 日本の個人情報保護法で明確に守るべきもの • 特定、連絡、直接被害 • クレジット番号、SNSのアカウント名なども配慮が必要 • 配慮したからといって、プライバシー上の懸念が 完全になくなるわけではない プライバシーの問題(2/2) 10/27
11.
• 電子情報通信学会 Vol.99
No.6 • 2013年NICTが大阪ステーションシティにビデオカメラを設置 して災害時における人の流動性を把握する実験を発表 • 反発が大きく実施延期 • 個人情報保護法に違反してなくてもプライバシー権を 違法に侵害していないとは限らない • 公道に体重計を埋め込んで隠し、たまたまその上を通った人 の体重をはかる実証実験はプライバシーの侵害 • 他人に知られなくない情報を無断で取得してはいけない • 「取得者のセキュリティが万全であればプライバシー 侵害にならない」は誤解 • セキュリティスキルの高い盗撮魔 • 盗撮画像が絶対漏れなくてもだめ パーソナルデータの扱い 11/27
12.
• 杜撰に扱ってるのが露顕すると信用の低下 • 個人情報に該当するかグレーであっても個人の不安感 に配慮するのが望ましい パーソナルデータの扱い 12/27
13.
• データ提供者 • 個人に関する多数のパーソナルデータを保持し、 第三者に提供するもの •
データ利用者 • 提供されたデータを利用するもの • 攻撃者 • データ利用者で、 ある個人に関するなんらかの情報を得ようとするもの • 犠牲者 • データ提供者に自身のデータを預けて、 意図せずに自身の情報が明らかにされたもの 用語 13/27
14.
• GIC • 13.5万人の州職員と家族の氏名、性別、郵便番号、 生年月日、人種、医療機関の訪問日、診断結果etc •
このうち氏名を除いた情報を提供 • 選挙人名簿 • 氏名、性別、郵便番号、生年月日、住所、支持政党etc • 二つを合わせると個人が特定できる • 支持政党と病歴が連結される マサチューセッツ州の事例 14/27
15.
• AOL • 65万人の検索ログ(ユーザ名、検索語、クリックURL) 2千万行を提供 •
電話帳 • No.4417749のユーザの検索語にあった 「ジョージア州Lilburnの庭師、Arnold姓」などから 名前を特定 AOLの事例 15/27
16.
• 48万人のユーザの映画の評価データ1億件 • 利用者を特定する情報はレコードからは取り除かれていた •
攻撃者が犠牲者を一意に特定できる条件の算出 • Narayananら • ある個人が与えた次の情報で特定(?)できる確率 • 8個の映画の評価と2週間単位の精度の日付が分かれば99% • 2個の映画の評価と3日単位の精度の日付が分かれば68% • 別の批評データIMDbのデータとの連結も可能 Netflixの事例 16/27
17.
• NYのタクシー会社が情報公開制度に基づいて 1.73億件のタクシーの乗降履歴を提供 • 乗車、降車地点と時刻 •
タクシーの免許番号とナンバープレートはランダム化 • 問題点 • 不完全なランダム化のため元の免許番号やナンバープレート を復元できた • 特定のタクシーの移動履歴からドライバーの住所を推定 • 徴収料金のデータから収入も推測できた • タクシーに乗ろうとしたある乗客の写真があると 番号から行き先を推定可能 • 現在もデータは提供されている NY市Taxi Rideの事例 17/27
18.
• パーソナルデータをサービスに利用したい、 統計解析を実施したい • パーソナルデータの保管や管理が目的なら セキュリティ技術の適用対象 プライバシー保護技術を使う動機 18/27
19.
• 計算と秘匿性 • 入力𝑥に対して関数𝑓の出力𝑦
= 𝑓(𝑥) • 𝑥は秘密で𝑦を公開 • 𝑦から𝑥はどの程度推測されるのか? • 𝑓が暗号アルゴリズム(以下algo)のとき • 𝑥は平文で𝑦は暗号文 • 𝑓がデータ匿名化algoのとき • 𝑦から𝑥に含まれる個人がどこまで推定できるのか • 𝑓が統計的クエリのとき • 𝑥は統計DBで𝑦は平均値、ヒストグラムなど • 𝑓が秘密計算プロトコルのとき • 計算過程でやりとりされた情報から𝑥をどこまで復元できるか 6章 識別不可能性と攻撃者モデル 19/27
20.
• 𝑥 :
入力, 𝒜 : algo, 𝑦 : 出力のとき𝑦 ← 𝒜(𝑥)とかく • 𝑥のサイズを𝑛 ∈ ℕとする. 𝑝𝑜𝑙𝑦(𝑛) : 𝑛の多項式 • 多項式時間algo • 終了までのステップ数が𝑝𝑜𝑙𝑦 𝑛 • 指数時間algo • ステップ数がある𝐶 > 1について𝐶 𝑛 • 多項式領域algoと指数時間algo • 必要なメモリが𝑝𝑜𝑙𝑦(𝑛)と𝐶 𝑛 • 決定的algo • 𝑥が与えられたとき𝑦が一通りに決まるもの • 確率的 : 結果が確率的に決まるもの • PPT(Probabilistic Polynomial Time) 記法 20/27
21.
• 𝑓: ℕ
→ ℝが𝑛について無視できるとは • 任意の𝑝𝑜𝑙𝑦(𝑛)に対してある𝑛 𝑝 ∈ ℕが存在し、 𝑛 > 𝑛 𝑝なる全ての𝑛 ∈ ℕに対して𝑓 𝑛 < 1 𝑝𝑜𝑙𝑦 𝑛 となること • この関数を𝑛𝑒𝑔𝑙(𝑛)とか𝜖(𝑛)とかく 無視できる関数 21/27
22.
• 確率分布𝑑に従う確率変数を𝑋とするとき𝑋~𝑑とかく • 𝑋のとりうる値をΩとする •
𝑋が𝑥となる確率を Pr 𝑋~𝑑 (𝑋 = 𝑥)とかく • Pr( 𝑋 = 𝑥)と略するときもある • 𝑦を関数𝑓で評価した値が𝑧になる確率を Pr 𝑦←𝒜 𝑥 (𝑧 = 𝑓 𝑦 ) とかく 確率 22/27
23.
• ナイーブには 異なる値𝑥 ≠
𝑥′を入力とする𝑓の出力の確率分布 𝑓 𝑥 , 𝑓(𝑥′)を見分けられない • 厳密には • 確率分布𝑑 𝑛, 𝑑 𝑛 ′ に従う定義域 0,1 𝑛の確率変数𝑋 𝑛, 𝑋 𝑛 ′ について • 全ての𝑛 ∈ ℕ, 𝑥 ∈ 0,1 𝑛について Pr 𝑋 𝑛~𝑑 𝑛 𝑋 𝑛 = 𝑥 = Pr 𝑋 𝑛 ′ ~𝑑 𝑛 ′ (𝑋 𝑛 ′ = 𝑥) が成り立つとき 𝑑 𝑛と𝑑 𝑛 ′ は情報理論的識別不可能であるという 情報理論的識別不可能性 23/27
24.
• 𝑓が情報理論的識別不可能性に基づく秘匿性を持つ • 𝑓
∶ 0,1 𝑛 → 0,1 ∗ ; 確率的algo 任意の入力𝑥, 𝑥′, 出力𝑦について次の式を満たす Pr 𝑧←𝑓 𝑥 𝑦 = 𝑧 = Pr 𝑧←𝑓 𝑥′ (𝑦 = 𝑧) • 𝑓(𝑥)と𝑓(𝑥′ )の分布が同じなので区別できない • ワンタイムパッド • 完全秘匿性を持つ秘密鍵暗号 • 𝑘 𝑈 ← 0,1 𝑛 ; 一様ランダム • 平文𝑥 ∈ 0,1 𝑛 に対して𝑓𝑘 𝑥 = 𝑥 ⊕ 𝑘 • 𝑓(𝑥)と𝑓(𝑥′)の分布は同一 完全秘匿 24/27
25.
• 完全秘匿よりは弱い • 二つの分布が異なっていても現実的に区別できないな らそれでいい •
あるサンプル𝑥が分布𝑑と𝑑′のどちからから生成されたのかを 判定するPPT-algo 𝒜を考える • 𝒜 𝑥 = 1if𝑥が𝑑から生成された 0otherwise • 定義 • 確率分布𝑑 𝑛, 𝑑 𝑛 ′ に従う確率変数𝑋 𝑛, 𝑋 𝑛 ′ について任意の𝑛 ∈ ℕ, 𝑥 ∈ 0,1 𝑛, PPT-algo 𝒜に対して次が成り立つとき 𝑋 𝑛と𝑋 𝑛 ′ は計算量的識別不可能であるという | Pr 𝑋 𝑛~𝑑 𝑛 𝒜 𝑥 = 1, 𝑋 𝑛 = 𝑥 − Pr 𝑋 𝑛 ′ ~𝑑 𝑛 ′ (𝒜( 𝑥) = 1, 𝑋′ 𝑛 = 𝑥)| < 𝜖(𝑛) 計算量的識別不可能性 25/27
26.
• 関数𝑓が任意の𝑛 ∈
ℕ, 入力𝑥 𝑛, 𝑥 𝑛 ′ , 出力𝑦, PPT-algo 𝒜に 対して次が成り立つとき𝑓を計算量的識別不可能性に 基づく秘匿性を持つという Pr 𝑦←𝒜 𝑧 ,𝑧←𝑓 𝑥 𝑛 𝑦 = 1 − Pr 𝑦←𝒜 𝑧 ,𝑧←𝑓 𝑥 𝑛 ′ 𝑦 = 1 < 𝜖(𝑛) 計算量的な秘匿性 26/27
27.
• 𝑦 =
𝑓(𝑥)から𝑥を推測しようとするもの • 攻撃者の能力、実行可能性 • 推測に用いる攻撃algo • 計算資源(多項式/指数時間algo, 多項式/指数領域algo) • 背景知識 • 情報理論的識別不可能性は、任意の計算時間と領域を 持つ攻撃者に対して秘匿性を保証する • 仮定 : 出力以外の背景知識を持たない • 攻撃algoは任意でよい • 匿名化algoが想定する攻撃者はより限定的 • データの有用性と秘匿性はトレードオフ • 強力な背景知識を持つ攻撃者には法令などによる制約を科す 攻撃者 27/27
Download




































![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Deep Learning 第2章 線形代数](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearningchapter2-180601014406-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[DL輪読会]Semi-supervised Knowledge Transfer for Deep Learning from Private Trai...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170414iwasawa-170414083300-thumbnail.jpg?width=640&height=640&fit=bounds)

























