Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
MITSUNARI Shigeo
782 views
LazyFP vulnerabilityの紹介
暗号とセキュリティ勉強会
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 10
2
/ 10
3
/ 10
4
/ 10
5
/ 10
6
/ 10
7
/ 10
8
/ 10
9
/ 10
10
/ 10
More Related Content
PDF
FreeBSD jail+vnetと戯れた話
by
Masaru Oki
PDF
clu2cは64ビットOSでも使えます (OSC 2012 Hiroshima LT用資料)
by
洋史 東平
PDF
Using Xeon D 10GBase-T
by
Masaru Oki
PPTX
量子情報16
by
Takeru Utsugi
PDF
Kernel bootstrap
by
Kai Sasaki
PDF
[Basic 7] OS の基本 / 割り込み / システム コール / メモリ管理
by
Yuto Takei
PDF
バイナリより低レイヤな話 (プロセッサの心を読み解く) - カーネル/VM探検隊@北陸1
by
Hirotaka Kawata
PDF
OpenSolaris Printing Environment
by
Naruhiko Ogasawara
FreeBSD jail+vnetと戯れた話
by
Masaru Oki
clu2cは64ビットOSでも使えます (OSC 2012 Hiroshima LT用資料)
by
洋史 東平
Using Xeon D 10GBase-T
by
Masaru Oki
量子情報16
by
Takeru Utsugi
Kernel bootstrap
by
Kai Sasaki
[Basic 7] OS の基本 / 割り込み / システム コール / メモリ管理
by
Yuto Takei
バイナリより低レイヤな話 (プロセッサの心を読み解く) - カーネル/VM探検隊@北陸1
by
Hirotaka Kawata
OpenSolaris Printing Environment
by
Naruhiko Ogasawara
More from MITSUNARI Shigeo
PDF
暗号技術の実装と数学
by
MITSUNARI Shigeo
PDF
範囲証明つき準同型暗号とその対話的プロトコル
by
MITSUNARI Shigeo
PDF
暗認本読書会13 advanced
by
MITSUNARI Shigeo
PDF
暗認本読書会12
by
MITSUNARI Shigeo
PDF
暗認本読書会11
by
MITSUNARI Shigeo
PDF
暗認本読書会10
by
MITSUNARI Shigeo
PDF
暗認本読書会9
by
MITSUNARI Shigeo
PDF
Intel AVX-512/富岳SVE用SIMDコード生成ライブラリsimdgen
by
MITSUNARI Shigeo
PDF
暗認本読書会8
by
MITSUNARI Shigeo
PDF
暗認本読書会7
by
MITSUNARI Shigeo
PDF
暗認本読書会6
by
MITSUNARI Shigeo
PDF
暗認本読書会5
by
MITSUNARI Shigeo
PDF
暗認本読書会4
by
MITSUNARI Shigeo
PDF
深層学習フレームワークにおけるIntel CPU/富岳向け最適化法
by
MITSUNARI Shigeo
PDF
私とOSSの25年
by
MITSUNARI Shigeo
PDF
WebAssembly向け多倍長演算の実装
by
MITSUNARI Shigeo
PDF
Lifted-ElGamal暗号を用いた任意関数演算の二者間秘密計算プロトコルのmaliciousモデルにおける効率化
by
MITSUNARI Shigeo
PDF
楕円曲線と暗号
by
MITSUNARI Shigeo
PDF
HPC Phys-20201203
by
MITSUNARI Shigeo
PDF
BLS署名の実装とその応用
by
MITSUNARI Shigeo
暗号技術の実装と数学
by
MITSUNARI Shigeo
範囲証明つき準同型暗号とその対話的プロトコル
by
MITSUNARI Shigeo
暗認本読書会13 advanced
by
MITSUNARI Shigeo
暗認本読書会12
by
MITSUNARI Shigeo
暗認本読書会11
by
MITSUNARI Shigeo
暗認本読書会10
by
MITSUNARI Shigeo
暗認本読書会9
by
MITSUNARI Shigeo
Intel AVX-512/富岳SVE用SIMDコード生成ライブラリsimdgen
by
MITSUNARI Shigeo
暗認本読書会8
by
MITSUNARI Shigeo
暗認本読書会7
by
MITSUNARI Shigeo
暗認本読書会6
by
MITSUNARI Shigeo
暗認本読書会5
by
MITSUNARI Shigeo
暗認本読書会4
by
MITSUNARI Shigeo
深層学習フレームワークにおけるIntel CPU/富岳向け最適化法
by
MITSUNARI Shigeo
私とOSSの25年
by
MITSUNARI Shigeo
WebAssembly向け多倍長演算の実装
by
MITSUNARI Shigeo
Lifted-ElGamal暗号を用いた任意関数演算の二者間秘密計算プロトコルのmaliciousモデルにおける効率化
by
MITSUNARI Shigeo
楕円曲線と暗号
by
MITSUNARI Shigeo
HPC Phys-20201203
by
MITSUNARI Shigeo
BLS署名の実装とその応用
by
MITSUNARI Shigeo
LazyFP vulnerabilityの紹介
1.
Intel LazyFP vulnerability: Exploiting
lazy FPU state switching 暗号とセキュリティ勉強会 2018/6/25 光成滋生 1 / 10
2.
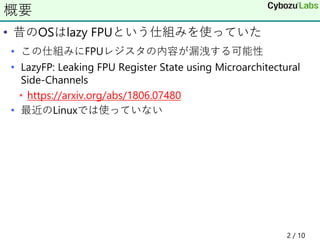
• 昔のOSはlazy FPUという仕組みを使っていた •
この仕組みにFPUレジスタの内容が漏洩する可能性 • LazyFP: Leaking FPU Register State using Microarchitectural Side-Channels • https://arxiv.org/abs/1806.07480 • 最近のLinuxでは使っていない 2 / 10 概要
3.
• 小数やベクトル演算専用のコプロセッサ • かつては別売だった •
i387コプロセッサ10万円 • 今はCPUの中に入ってる 3 / 10 FPU
4.
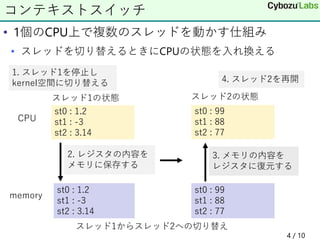
• 1個のCPU上で複数のスレッドを動かす仕組み • スレッドを切り替えるときにCPUの状態を入れ換える 4
/ 10 コンテキストスイッチ st0 : 1.2 st1 : -3 st2 : 3.14 st0 : 99 st1 : 88 st2 : 77 スレッド1からスレッド2への切り替え st0 : 1.2 st1 : -3 st2 : 3.14 st0 : 99 st1 : 88 st2 : 77 CPU memory 2. レジスタの内容を メモリに保存する 3. メモリの内容を レジスタに復元する スレッド1の状態 スレッド2の状態 1. スレッド1を停止し kernel空間に切り替える 4. スレッド2を再開
5.
• 負荷が大きい • FPUは80bitレジスタ8個 •
AVX-512では512bitレジスタが32個で合計2KiB • 動機 • 昔はFPUを使うアプリは限られていた • 使わないのに退避・復元は無駄 • LazyFPU • 使う必要が出たときだけ切り替えればよいのでは? • スレッドを切り替えたらFPUを使えないモードにする • そのスレッドがFPUを使ったら#NM(Device not available : no math)例外が発生 • そのときにレジスタの退避・復元を行いFPUを使う • FPUを使わなければ無駄な退避・復元をしなくてよい 5 / 10 難点とLazyFPU
6.
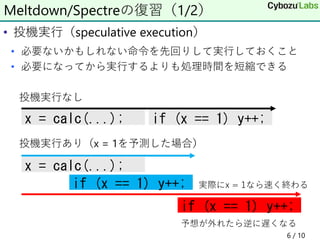
• 投機実行(speculative execution) •
必要ないかもしれない命令を先回りして実行しておくこと • 必要になってから実行するよりも処理時間を短縮できる 投機実行なし 投機実行あり(x = 1を予測した場合) 6 / 10 Meltdown/Spectreの復習(1/2) x = calc(...); if (x == 1) y++; x = calc(...); if (x == 1) y++; if (x == 1) y++; 実際にx = 1なら速く終わる 予想が外れたら逆に遅くなる
7.
• キャッシュメモリ • メモリの読み書きは遅い(100nsecレベル) •
add/subは0.1nsecレベル • CPUの近くに少量で高速なメモリを配置 • 一度readすると次のreadが高速になる • Meltdown/Spectre • 秘密情報に依存した場所を投機実行で読ませる • そのあとどの領域がキャッシュに入ってるかを確認 7 / 10 Meltdown/Spectreの復習(2/2) 秘密情報xに対して 投機実行で read mem[x] させる mem 0 1 2 3 4 5 0 1 2 3 4 5 mem read time 2番目のread が速いので x = 2と推測
8.
• レジスタの1bitが漏洩するコード • xmm0に秘密情報が入ったスレッドから 攻撃者のスレッドにコンテキストスイッチ •
攻撃者は上記のコードを実行 • OSはmovq rax, xmm0の段階で#NM例外を発生 • しかし投機実行によりreadまで行ってしまう • mem[0]とmem[64]のread timeの短い方がxmm0の最下位bit 8 / 10 LazyFPUの脆弱性 movq rax, xmm0 // FPUのxmm0をraxに代入(rax = xmm0) and rax, 1 // raxの最下位bitのみにする(rax &= 1) shl rax, 6 // 64掛ける(rax *= 64) mov dword [mem + rax], 0 // mem[0]またはmem[64]をread
9.
• 前ページの方法では#NM例外が発生するとxmm0の中 身がクリアされてしまう • #NM例外ではなく#PF(page
fault)を発生させる • #PFが発生するためmovq rax, xmm0で#NM例外は発生しない • xmm0の中身がクリアされない • しかし投機実行でxmm0の最下位bitは判別可能 • movq rax, xmm0 / shr rax, 1 / and rax, 1とshiftを挟めば次のbit も判別可能...を繰り返す 9 / 10 コンセプトコードの改良 movq dword [0], 0 // #PF movq rax, xmm0 and rax, 1 shl rax, 6 mov dword [mem + rax], 0
10.
• RTM(Restricted Trancastional
Memory) • トランザクション実行用の命令群 • 指定された命令群(トランザクション領域)を他のプロセッ サからatomicに(一瞬で)実行されたように見える仕組み • 何らかの原因で失敗すると何も実行しなかったことになる • #PFよりもRTMを使う方が15倍ほど高速(3MiB/s)に レジスタの中身が見える 10 / 10 RTM(Intel TSX)を使う xbegin abort // トランザクション開始 movq rax, xmm0 and rax, 1 shl rax, 6 mov dword [mem + rax], 0 xabort // トランザクション強制失敗
Download



![• キャッシュメモリ
• メモリの読み書きは遅い(100nsecレベル)
• add/subは0.1nsecレベル
• CPUの近くに少量で高速なメモリを配置
• 一度readすると次のreadが高速になる
• Meltdown/Spectre
• 秘密情報に依存した場所を投機実行で読ませる
• そのあとどの領域がキャッシュに入ってるかを確認
7 / 10
Meltdown/Spectreの復習(2/2)
秘密情報xに対して
投機実行で
read mem[x]
させる
mem
0
1
2
3
4
5 0 1 2 3 4 5 mem
read
time
2番目のread
が速いので
x = 2と推測](https://image.slidesharecdn.com/lazyfp-201013042313/85/LazyFP-vulnerability-7-320.jpg)
![• レジスタの1bitが漏洩するコード
• xmm0に秘密情報が入ったスレッドから
攻撃者のスレッドにコンテキストスイッチ
• 攻撃者は上記のコードを実行
• OSはmovq rax, xmm0の段階で#NM例外を発生
• しかし投機実行によりreadまで行ってしまう
• mem[0]とmem[64]のread timeの短い方がxmm0の最下位bit
8 / 10
LazyFPUの脆弱性
movq rax, xmm0 // FPUのxmm0をraxに代入(rax = xmm0)
and rax, 1 // raxの最下位bitのみにする(rax &= 1)
shl rax, 6 // 64掛ける(rax *= 64)
mov dword [mem + rax], 0 // mem[0]またはmem[64]をread](https://image.slidesharecdn.com/lazyfp-201013042313/85/LazyFP-vulnerability-8-320.jpg)
![• 前ページの方法では#NM例外が発生するとxmm0の中
身がクリアされてしまう
• #NM例外ではなく#PF(page fault)を発生させる
• #PFが発生するためmovq rax, xmm0で#NM例外は発生しない
• xmm0の中身がクリアされない
• しかし投機実行でxmm0の最下位bitは判別可能
• movq rax, xmm0 / shr rax, 1 / and rax, 1とshiftを挟めば次のbit
も判別可能...を繰り返す
9 / 10
コンセプトコードの改良
movq dword [0], 0 // #PF
movq rax, xmm0
and rax, 1
shl rax, 6
mov dword [mem + rax], 0](https://image.slidesharecdn.com/lazyfp-201013042313/85/LazyFP-vulnerability-9-320.jpg)
![• RTM(Restricted Trancastional Memory)
• トランザクション実行用の命令群
• 指定された命令群(トランザクション領域)を他のプロセッ
サからatomicに(一瞬で)実行されたように見える仕組み
• 何らかの原因で失敗すると何も実行しなかったことになる
• #PFよりもRTMを使う方が15倍ほど高速(3MiB/s)に
レジスタの中身が見える
10 / 10
RTM(Intel TSX)を使う
xbegin abort // トランザクション開始
movq rax, xmm0
and rax, 1
shl rax, 6
mov dword [mem + rax], 0
xabort // トランザクション強制失敗](https://image.slidesharecdn.com/lazyfp-201013042313/85/LazyFP-vulnerability-10-320.jpg)





![[Basic 7] OS の基本 / 割り込み / システム コール / メモリ管理](https://cdn.slidesharecdn.com/ss_thumbnails/basic-07-180228134341-thumbnail.jpg?width=640&height=640&fit=bounds)





















