Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
NVIDIA Japan
PDF, PPTX
1,550 views
20190625 OpenACC 講習会 第3部
第23回 GPUコンピューティング講習会 - OpenACC講習会 - http://gpu-computing.gsic.titech.ac.jp/node/97
Technology
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 46
2
/ 46
3
/ 46
4
/ 46
5
/ 46
6
/ 46
7
/ 46
8
/ 46
9
/ 46
10
/ 46
11
/ 46
12
/ 46
13
/ 46
14
/ 46
15
/ 46
16
/ 46
17
/ 46
18
/ 46
19
/ 46
20
/ 46
21
/ 46
22
/ 46
23
/ 46
24
/ 46
25
/ 46
26
/ 46
27
/ 46
28
/ 46
29
/ 46
30
/ 46
31
/ 46
32
/ 46
33
/ 46
34
/ 46
35
/ 46
36
/ 46
37
/ 46
38
/ 46
39
/ 46
40
/ 46
41
/ 46
42
/ 46
43
/ 46
44
/ 46
45
/ 46
46
/ 46
More Related Content
PDF
20190625 OpenACC 講習会 第1部
by
NVIDIA Japan
PDF
GPGPU Seminar (GPU Accelerated Libraries, 2 of 3, cuSPARSE)
by
智啓 出川
PDF
20190625 OpenACC 講習会 第2部
by
NVIDIA Japan
PPTX
冬のLock free祭り safe
by
Kumazaki Hiroki
PDF
組み込み関数(intrinsic)によるSIMD入門
by
Norishige Fukushima
PPTX
Long-Tailed Classificationの最新動向について
by
Plot Hong
PDF
いまさら聞けないarmを使ったNEONの基礎と活用事例
by
Fixstars Corporation
PDF
Amazon RDSを参考にしたとりまチューニング
by
Shunsuke Mihara
20190625 OpenACC 講習会 第1部
by
NVIDIA Japan
GPGPU Seminar (GPU Accelerated Libraries, 2 of 3, cuSPARSE)
by
智啓 出川
20190625 OpenACC 講習会 第2部
by
NVIDIA Japan
冬のLock free祭り safe
by
Kumazaki Hiroki
組み込み関数(intrinsic)によるSIMD入門
by
Norishige Fukushima
Long-Tailed Classificationの最新動向について
by
Plot Hong
いまさら聞けないarmを使ったNEONの基礎と活用事例
by
Fixstars Corporation
Amazon RDSを参考にしたとりまチューニング
by
Shunsuke Mihara
What's hot
PDF
いまさら聞けない!CUDA高速化入門
by
Fixstars Corporation
PDF
CUDAのアセンブリ言語基礎のまとめ PTXとSASSの概説
by
Takateru Yamagishi
PDF
GPUが100倍速いという神話をぶち殺せたらいいな ver.2013
by
Ryo Sakamoto
PPTX
CPU / GPU高速化セミナー!性能モデルの理論と実践:理論編
by
Fixstars Corporation
PDF
競技プログラミングにおけるコードの書き方とその利便性
by
Hibiki Yamashiro
PPTX
AVX-512(フォーマット)詳解
by
MITSUNARI Shigeo
PDF
ARM CPUにおけるSIMDを用いた高速計算入門
by
Fixstars Corporation
PDF
Blazing Performance with Flame Graphs
by
Brendan Gregg
PDF
Spannerに関する技術メモ
by
Etsuji Nakai
PDF
2015年度GPGPU実践プログラミング 第9回 行列計算(行列-行列積)
by
智啓 出川
PDF
[DL輪読会]Deep Learning 第15章 表現学習
by
Deep Learning JP
PDF
1070: CUDA プログラミング入門
by
NVIDIA Japan
PDF
1076: CUDAデバッグ・プロファイリング入門
by
NVIDIA Japan
PDF
GPGPU Seminar (PyCUDA)
by
智啓 出川
PDF
MapReduce入門
by
Satoshi Noto
PPTX
[DL輪読会]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Envir...
by
Deep Learning JP
PDF
グラフ構造データに対する深層学習〜創薬・材料科学への応用とその問題点〜 (第26回ステアラボ人工知能セミナー)
by
STAIR Lab, Chiba Institute of Technology
PDF
TensorRT Inference Serverではじめる、 高性能な推論サーバ構築
by
NVIDIA Japan
PDF
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models
by
Deep Learning JP
PDF
流体シミュレータの製作
by
Fumiya Watanabe
いまさら聞けない!CUDA高速化入門
by
Fixstars Corporation
CUDAのアセンブリ言語基礎のまとめ PTXとSASSの概説
by
Takateru Yamagishi
GPUが100倍速いという神話をぶち殺せたらいいな ver.2013
by
Ryo Sakamoto
CPU / GPU高速化セミナー!性能モデルの理論と実践:理論編
by
Fixstars Corporation
競技プログラミングにおけるコードの書き方とその利便性
by
Hibiki Yamashiro
AVX-512(フォーマット)詳解
by
MITSUNARI Shigeo
ARM CPUにおけるSIMDを用いた高速計算入門
by
Fixstars Corporation
Blazing Performance with Flame Graphs
by
Brendan Gregg
Spannerに関する技術メモ
by
Etsuji Nakai
2015年度GPGPU実践プログラミング 第9回 行列計算(行列-行列積)
by
智啓 出川
[DL輪読会]Deep Learning 第15章 表現学習
by
Deep Learning JP
1070: CUDA プログラミング入門
by
NVIDIA Japan
1076: CUDAデバッグ・プロファイリング入門
by
NVIDIA Japan
GPGPU Seminar (PyCUDA)
by
智啓 出川
MapReduce入門
by
Satoshi Noto
[DL輪読会]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Envir...
by
Deep Learning JP
グラフ構造データに対する深層学習〜創薬・材料科学への応用とその問題点〜 (第26回ステアラボ人工知能セミナー)
by
STAIR Lab, Chiba Institute of Technology
TensorRT Inference Serverではじめる、 高性能な推論サーバ構築
by
NVIDIA Japan
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models
by
Deep Learning JP
流体シミュレータの製作
by
Fumiya Watanabe
Similar to 20190625 OpenACC 講習会 第3部
PDF
新しい並列for構文のご提案
by
yohhoy
PDF
optimal Ate pairing
by
MITSUNARI Shigeo
PDF
マルチコアを用いた画像処理
by
Norishige Fukushima
PDF
LLVMで遊ぶ(整数圧縮とか、x86向けの自動ベクトル化とか)
by
Takeshi Yamamuro
PDF
第11回 配信講義 計算科学技術特論B(2022)
by
RCCSRENKEI
PDF
2015年度GPGPU実践プログラミング 第10回 行列計算(行列-行列積の高度な最適化)
by
智啓 出川
PPTX
純粋関数型アルゴリズム入門
by
Kimikazu Kato
PDF
More modern gpu
by
Preferred Networks
PPTX
Rによる繰り返しの並列処理
by
wada, kazumi
PPTX
並列化による高速化
by
sakura-mike
PDF
Pfi Seminar 2010 1 7
by
Preferred Networks
PDF
Boost Fusion Library
by
Akira Takahashi
PDF
あまぁいRcpp生活
by
Masaki Tsuda
PDF
短距離古典分子動力学計算の 高速化と大規模並列化
by
Hiroshi Watanabe
PDF
200730material fujita
by
RCCSRENKEI
PDF
統計解析言語Rにおける大規模データ管理のためのboost.interprocessの活用
by
Shintaro Fukushima
PDF
Tuning, etc.
by
Hiroshi Watanabe
PPTX
GPUによる多倍長整数乗算の高速化手法の提案
by
Koji Kitano
PDF
CMSI計算科学技術特論B(14) OpenACC・CUDAによるGPUコンピューティング
by
Computational Materials Science Initiative
PDF
“Symbolic bounds analysis of pointers, array indices, and accessed memory reg...
by
Masahiro Sakai
新しい並列for構文のご提案
by
yohhoy
optimal Ate pairing
by
MITSUNARI Shigeo
マルチコアを用いた画像処理
by
Norishige Fukushima
LLVMで遊ぶ(整数圧縮とか、x86向けの自動ベクトル化とか)
by
Takeshi Yamamuro
第11回 配信講義 計算科学技術特論B(2022)
by
RCCSRENKEI
2015年度GPGPU実践プログラミング 第10回 行列計算(行列-行列積の高度な最適化)
by
智啓 出川
純粋関数型アルゴリズム入門
by
Kimikazu Kato
More modern gpu
by
Preferred Networks
Rによる繰り返しの並列処理
by
wada, kazumi
並列化による高速化
by
sakura-mike
Pfi Seminar 2010 1 7
by
Preferred Networks
Boost Fusion Library
by
Akira Takahashi
あまぁいRcpp生活
by
Masaki Tsuda
短距離古典分子動力学計算の 高速化と大規模並列化
by
Hiroshi Watanabe
200730material fujita
by
RCCSRENKEI
統計解析言語Rにおける大規模データ管理のためのboost.interprocessの活用
by
Shintaro Fukushima
Tuning, etc.
by
Hiroshi Watanabe
GPUによる多倍長整数乗算の高速化手法の提案
by
Koji Kitano
CMSI計算科学技術特論B(14) OpenACC・CUDAによるGPUコンピューティング
by
Computational Materials Science Initiative
“Symbolic bounds analysis of pointers, array indices, and accessed memory reg...
by
Masahiro Sakai
More from NVIDIA Japan
PDF
開発者が語る NVIDIA cuQuantum SDK
by
NVIDIA Japan
PDF
NVIDIA HPC ソフトウエア斜め読み
by
NVIDIA Japan
PDF
Hopper アーキテクチャで、変わること、変わらないこと
by
NVIDIA Japan
PDF
GPU と PYTHON と、それから最近の NVIDIA
by
NVIDIA Japan
PDF
データ爆発時代のネットワークインフラ
by
NVIDIA Japan
PDF
HPC 的に H100 は魅力的な GPU なのか?
by
NVIDIA Japan
PDF
NVIDIA cuQuantum SDK による量子回路シミュレーターの高速化
by
NVIDIA Japan
PDF
Magnum IO GPUDirect Storage 最新情報
by
NVIDIA Japan
PDF
NVIDIA Modulus: Physics ML 開発のためのフレームワーク
by
NVIDIA Japan
PDF
Physics-ML のためのフレームワーク NVIDIA Modulus 最新事情
by
NVIDIA Japan
PDF
20221021_JP5.0.2-Webinar-JP_Final.pdf
by
NVIDIA Japan
PDF
HPC+AI ってよく聞くけど結局なんなの
by
NVIDIA Japan
PDF
Jetson Xavier NX クラウドネイティブをエッジに
by
NVIDIA Japan
PDF
テレコムのビッグデータ解析 & AI サイバーセキュリティ
by
NVIDIA Japan
PDF
2020年10月29日 Jetson Nano 2GBで始めるAI x Robotics教育
by
NVIDIA Japan
PDF
2020年10月29日 プロフェッショナルAI×Roboticsエンジニアへのロードマップ
by
NVIDIA Japan
PDF
必見!絶対におすすめの通信業界セッション 5 つ ~秋の GTC 2020~
by
NVIDIA Japan
PDF
GTC November 2021 – テレコム関連アップデート サマリー
by
NVIDIA Japan
PDF
2020年10月29日 Jetson活用によるAI教育
by
NVIDIA Japan
PDF
COVID-19 研究・対策に活用可能な NVIDIA ソフトウェアと関連情報
by
NVIDIA Japan
開発者が語る NVIDIA cuQuantum SDK
by
NVIDIA Japan
NVIDIA HPC ソフトウエア斜め読み
by
NVIDIA Japan
Hopper アーキテクチャで、変わること、変わらないこと
by
NVIDIA Japan
GPU と PYTHON と、それから最近の NVIDIA
by
NVIDIA Japan
データ爆発時代のネットワークインフラ
by
NVIDIA Japan
HPC 的に H100 は魅力的な GPU なのか?
by
NVIDIA Japan
NVIDIA cuQuantum SDK による量子回路シミュレーターの高速化
by
NVIDIA Japan
Magnum IO GPUDirect Storage 最新情報
by
NVIDIA Japan
NVIDIA Modulus: Physics ML 開発のためのフレームワーク
by
NVIDIA Japan
Physics-ML のためのフレームワーク NVIDIA Modulus 最新事情
by
NVIDIA Japan
20221021_JP5.0.2-Webinar-JP_Final.pdf
by
NVIDIA Japan
HPC+AI ってよく聞くけど結局なんなの
by
NVIDIA Japan
Jetson Xavier NX クラウドネイティブをエッジに
by
NVIDIA Japan
テレコムのビッグデータ解析 & AI サイバーセキュリティ
by
NVIDIA Japan
2020年10月29日 Jetson Nano 2GBで始めるAI x Robotics教育
by
NVIDIA Japan
2020年10月29日 プロフェッショナルAI×Roboticsエンジニアへのロードマップ
by
NVIDIA Japan
必見!絶対におすすめの通信業界セッション 5 つ ~秋の GTC 2020~
by
NVIDIA Japan
GTC November 2021 – テレコム関連アップデート サマリー
by
NVIDIA Japan
2020年10月29日 Jetson活用によるAI教育
by
NVIDIA Japan
COVID-19 研究・対策に活用可能な NVIDIA ソフトウェアと関連情報
by
NVIDIA Japan
Recently uploaded
PDF
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
PPTX
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
PDF
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
20190625 OpenACC 講習会 第3部
1.
第3部 – OpenACC
によるループの最適化 Naruhiko Tan, Solution Architect, NVIDIA OPENACC 講習会
2.
COURSE OBJECTIVE 参加者のみなさんが、 OpenACC を⽤いてみなさん ⾃⾝のアプリケーションを加速 できるようにすること
3.
第3部のアウトライン カバーするトピック § はじめての Gangs,
Workers, and Vectors § GPU のプロファイル § ループ最適化 § 参考情報
4.
第1部と第2部の復習
5.
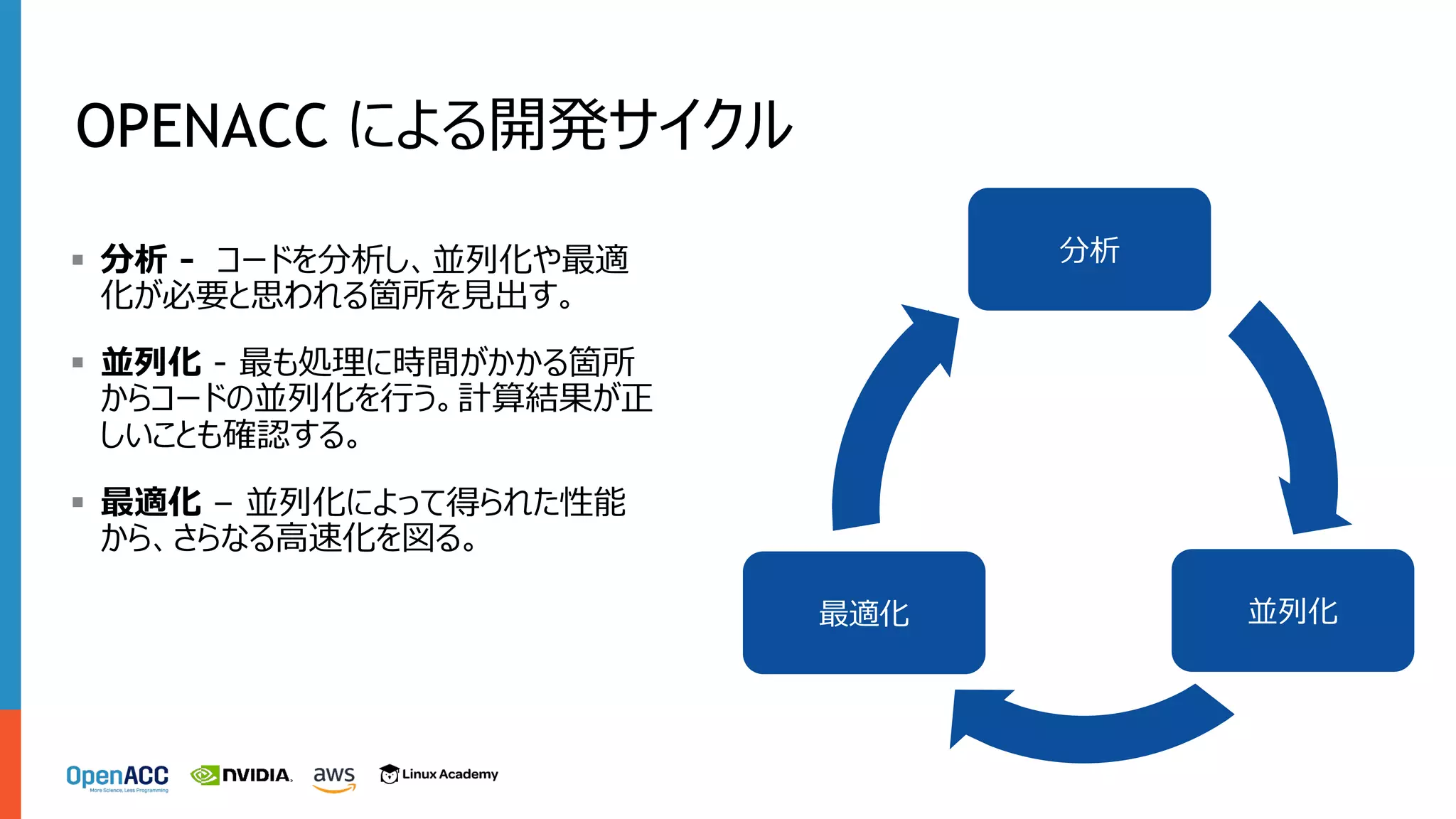
OPENACC による開発サイクル 分析 並列化最適化 § 分析
- コードを分析し、並列化や最適 化が必要と思われる箇所を⾒出す。 § 並列化 - 最も処理に時間がかかる箇所 からコードの並列化を⾏う。計算結果が正 しいことも確認する。 § 最適化 – 並列化によって得られた性能 から、さらなる⾼速化を図る。
6.
OpenACC ディレクティブ データ移動の 管理 並列実⾏の 開始 ループ マッピングの 最適化 #pragma
acc data copyin(a,b) copyout(c) { ... #pragma acc parallel { #pragma acc loop gang vector for (i = 0; i < n; ++i) { c[i] = a[i] + b[i]; ... } } ... } CPU, GPU, Manycore 移植性 相互操作可能 1つのソース コード 段階的
7.
while ( err
> tol && iter < iter_max ) { err=0.0; #pragma acc parallel loop reduction(max:err) for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { Anew[OFFSET(j, i, m)] = 0.25 * ( A[OFFSET(j, i+1, m)] + A[OFFSET(j, i-1, m)] + A[OFFSET(j-1, i, m)] + A[OFFSET(j+1, i, m)]); error = fmax( error, fabs(Anew[OFFSET(j, i, m)] - A[OFFSET(j, i , m)])); } } #pragma acc parallel loop for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { A[OFFSET(j, i, m)] = Anew[OFFSET(j, i, m)]; } } iter++; } OPENACC PARALLEL LOOP による並列化 7 最初のループを並列化 max reduction を指定 2つ⽬のループを並列化 どのループを並列化するかのみを指⽰し、 どのように並列化するかの詳細は指⽰ していない。
8.
#pragma acc data
copy(A[0:n*m]) copyin(Anew[0:n*m]) while ( err > tol && iter < iter_max ) { err=0.0; #pragma acc parallel loop reduction(max:err) copyin(A[0:n*m]) copy(Anew[0:n*m]) for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { Anew[OFFSET(j, i, m)] = 0.25 * ( A[OFFSET(j, i+1, m)] + A[OFFSET(j, i-1, m)] + A[OFFSET(j-1, i, m)] + A[OFFSET(j+1, i, m)]); error = fmax( error, fabs(Anew[OFFSET(j, i, m)] - A[OFFSET(j, i , m)])); } } #pragma acc parallel loop copyin(Anew[0:n*m]) copyout(A[0:n*m]) for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { A[OFFSET(j, i, m)] = Anew[OFFSET(j, i, m)]; } } iter++; } 最適化されたデータ転送 必要な時のみ A をコピー。 Anew の初期条件はコピーす るが、最終的な値はしない。
9.
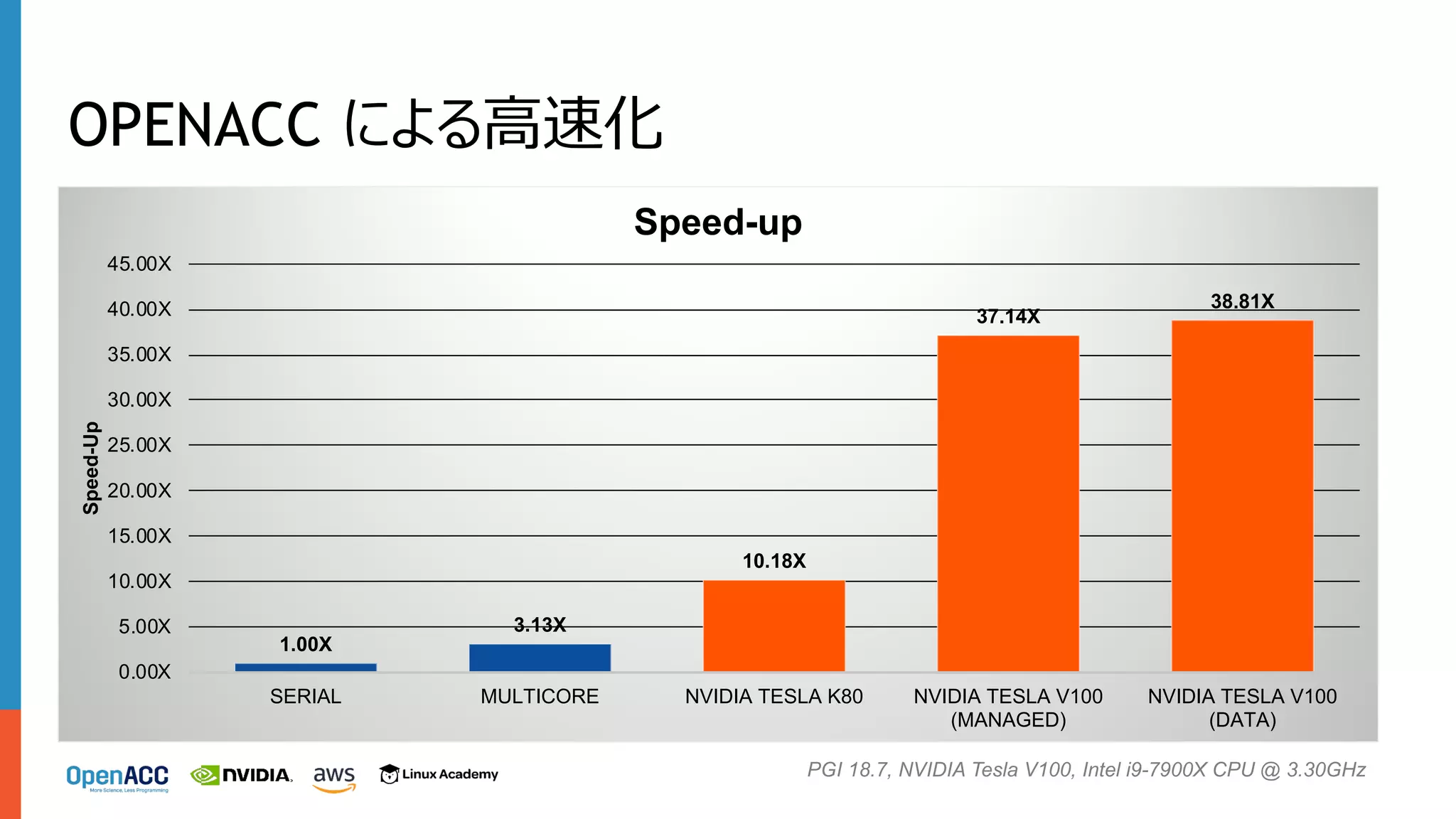
OPENACC による⾼速化 1.00X 3.13X 10.18X 37.14X 38.81X 0.00X 5.00X 10.00X 15.00X 20.00X 25.00X 30.00X 35.00X 40.00X 45.00X SERIAL MULTICORE
NVIDIA TESLA K80 NVIDIA TESLA V100 (MANAGED) NVIDIA TESLA V100 (DATA) Speed-Up Speed-up PGI 18.7, NVIDIA Tesla V100, Intel i9-7900X CPU @ 3.30GHz
10.
はじめての GANGS, WORKERS,
AND VECTORS
11.
はじめての GANGS, WORKERS,
AND VECTORS
12.
はじめての GANGS, WORKERS,
AND VECTORS
13.
! 1 worker がどのくらいの仕事が できるかは、彼/彼⼥のスピード で律速される。 1
worker はある⼀定の速さで しか動けない。 はじめての GANGS, WORKERS, AND VECTORS
14.
! ローラーのサイズを⼤きくした としても、worker が動ける スピードに律速される。 Worker がもっと必要。 はじめての
GANGS, WORKERS, AND VECTORS
15.
適切に組織されていれば、複数 の worker を投⼊することでもっ とたくさんの仕事ができるし、リ ソースのシェアも可能。 はじめての
GANGS, WORKERS, AND VECTORS
16.
ワーカーを複数のグループ (gangs) に組織することで、1フロ ア内の作業を効率的に⾏うこと ができる。 異なるフロアのグループ (gangs) は独⽴に作業をすることができる。 Gangs
はそれぞれ独⽴に作業 をするので、必要な分だけ gangs を投⼊することができる。 はじめての GANGS, WORKERS, AND VECTORS
17.
Gangs の数が全てのフロアをカ バーするのに⼗分でなくても、あ るフロアでの作業が終わり次第、 別のフロアへ移動して作業するこ とができる。 はじめての GANGS,
WORKERS, AND VECTORS
18.
ここでのペインターは OpenACC で⾔うところの worker
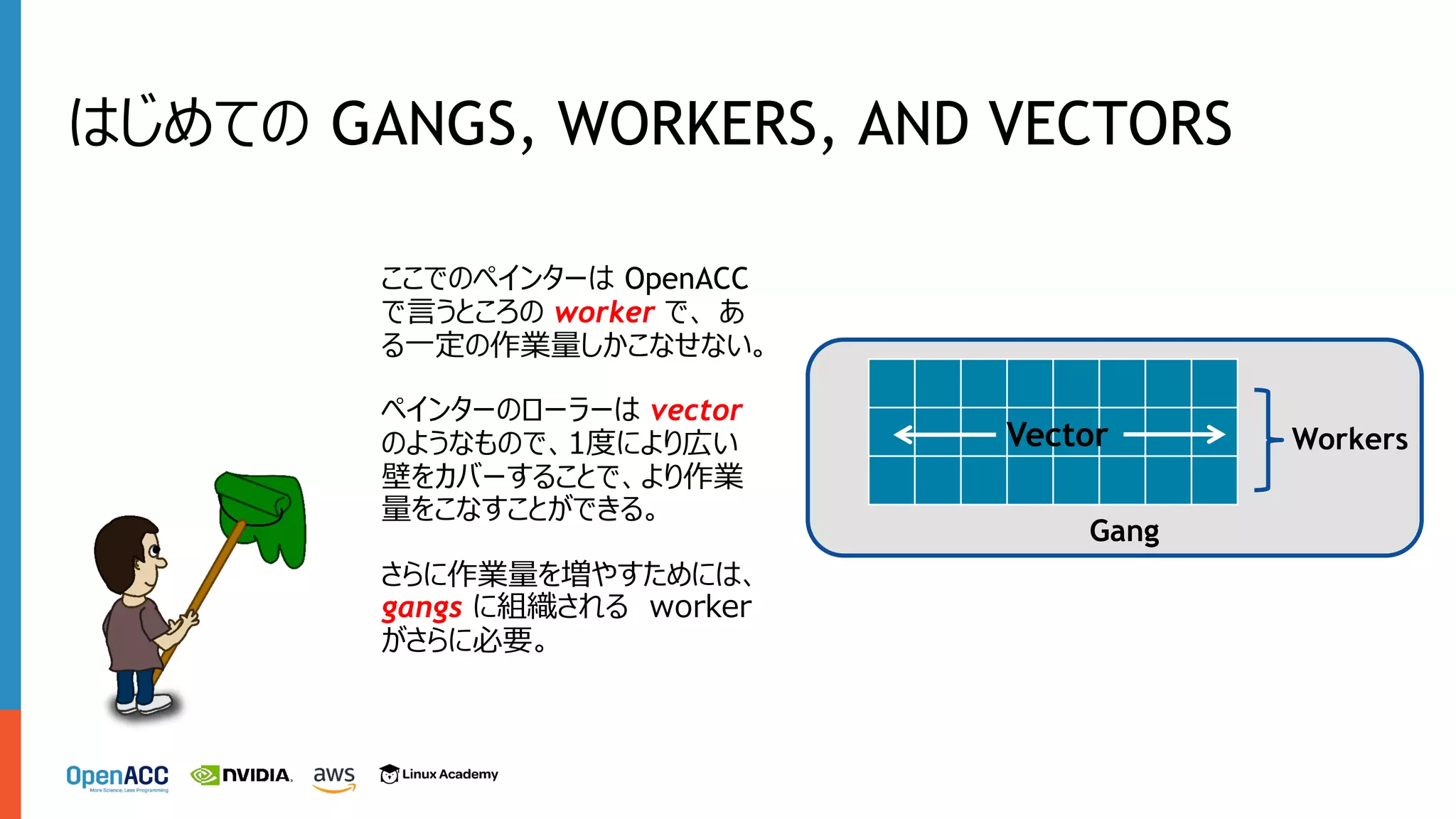
で、 あ る⼀定の作業量しかこなせない。 ペインターのローラーは vector のようなもので、1度により広い 壁をカバーすることで、より作業 量をこなすことができる。 さらに作業量を増やすためには、 gangs に組織される worker がさらに必要。 Workers Gang Vector はじめての GANGS, WORKERS, AND VECTORS
19.
GPU のプロファイル
20.
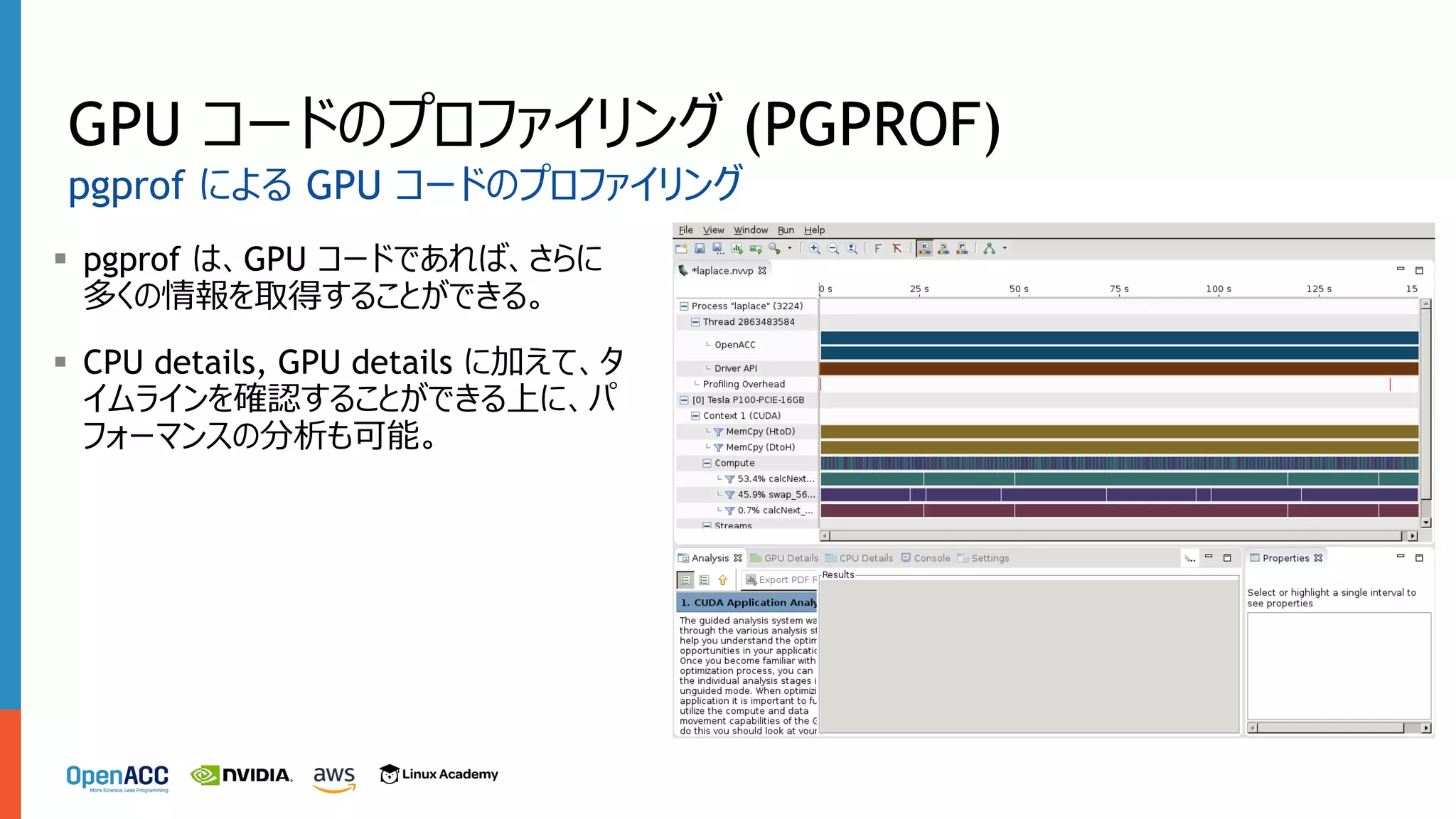
GPU コードのプロファイリング (PGPROF) §
pgprof は、GPU コードであれば、さらに 多くの情報を取得することができる。 § CPU details, GPU details に加えて、タ イムラインを確認することができる上に、パ フォーマンスの分析も可能。 pgprof による GPU コードのプロファイリング
21.
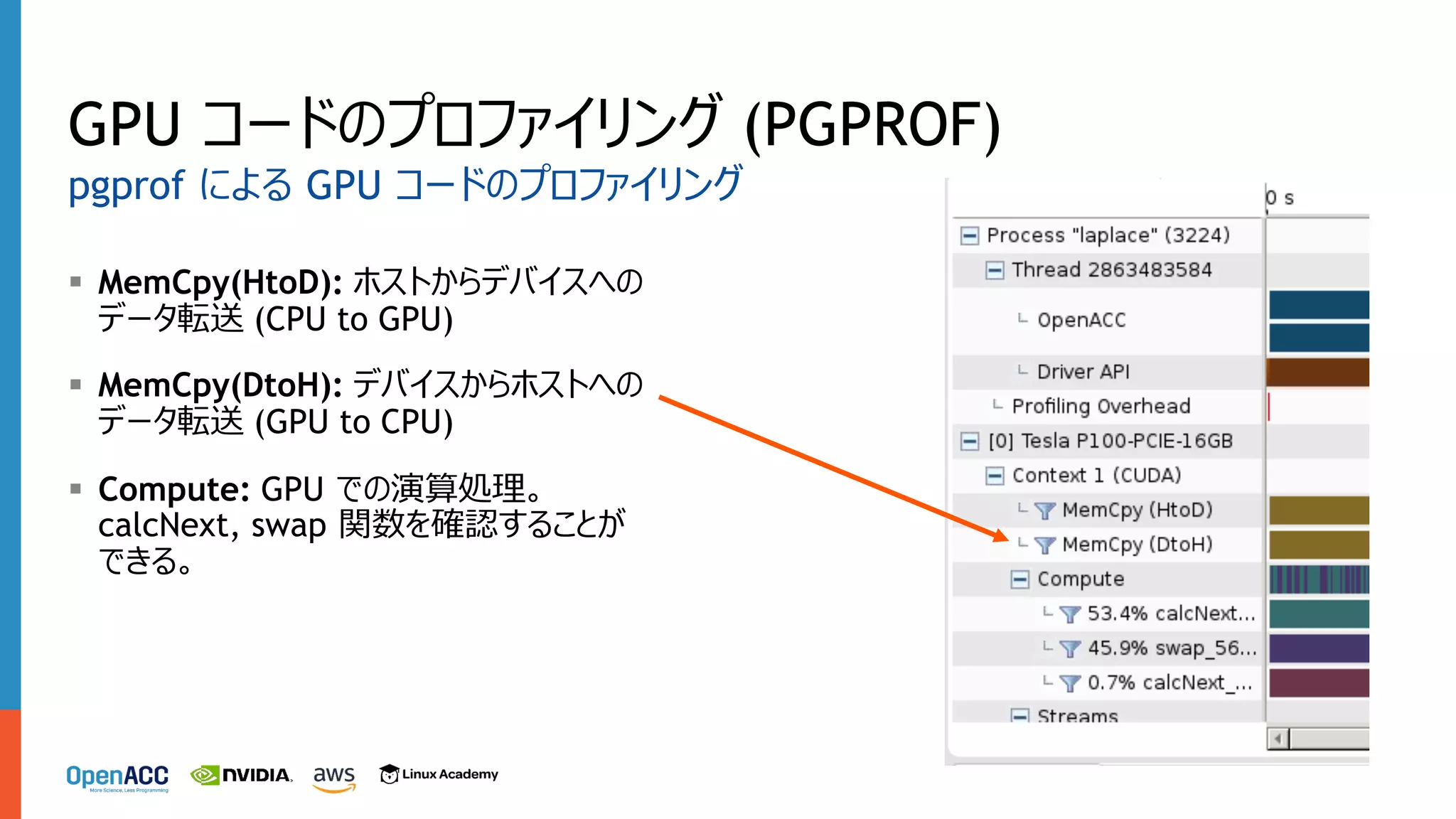
§ MemCpy(HtoD): ホストからデバイスへの データ転送
(CPU to GPU) § MemCpy(DtoH): デバイスからホストへの データ転送 (GPU to CPU) § Compute: GPU での演算処理。 calcNext, swap 関数を確認することが できる。 GPU コードのプロファイリング (PGPROF) pgprof による GPU コードのプロファイリング
22.
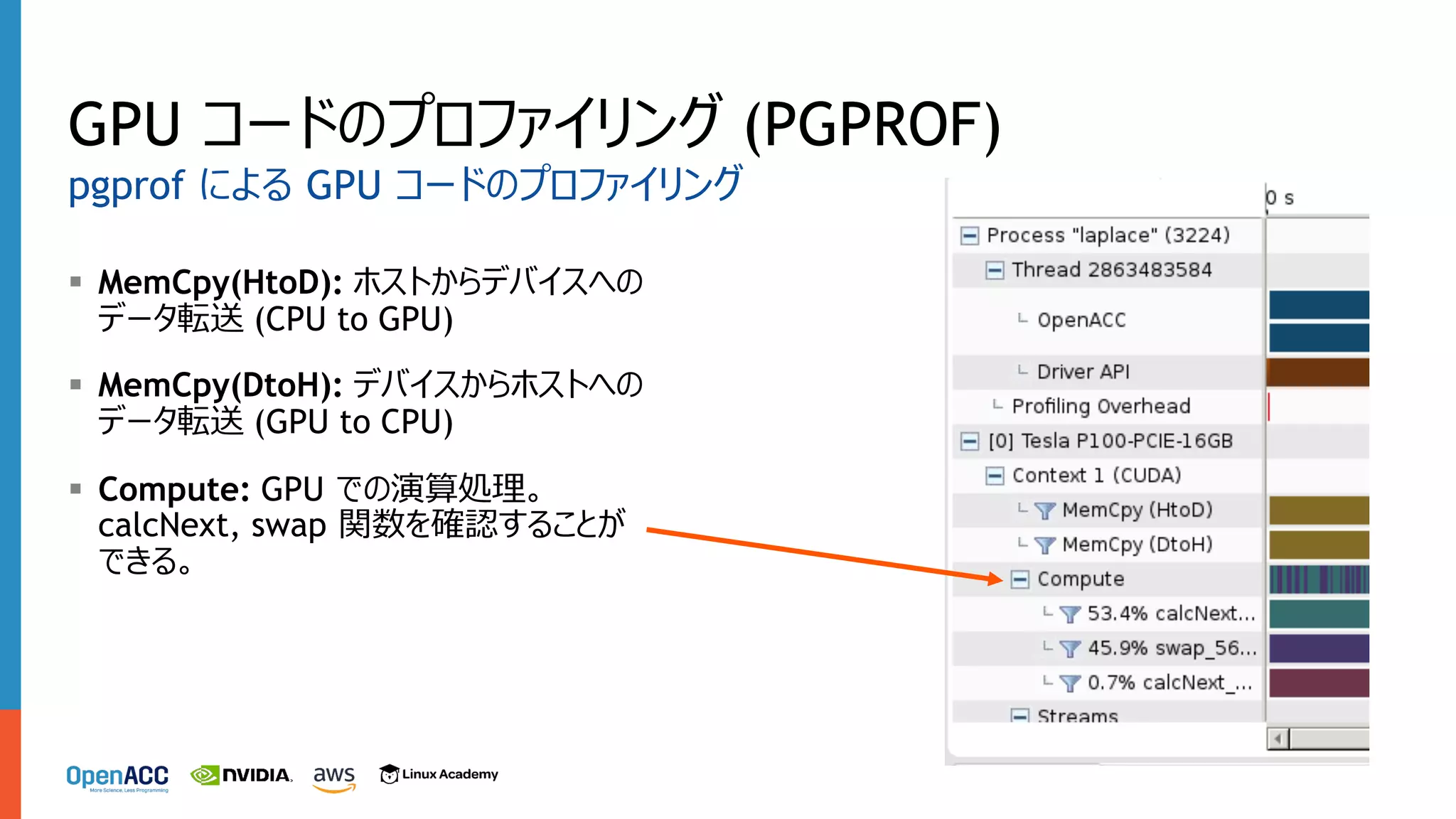
§ MemCpy(HtoD): ホストからデバイスへの データ転送
(CPU to GPU) § MemCpy(DtoH): デバイスからホストへの データ転送 (GPU to CPU) § Compute: GPU での演算処理。 calcNext, swap 関数を確認することが できる。 GPU コードのプロファイリング (PGPROF) pgprof による GPU コードのプロファイリング
23.
§ MemCpy(HtoD): ホストからデバイスへの データ転送
(CPU to GPU) § MemCpy(DtoH): デバイスからホストへの データ転送 (GPU to CPU) § Compute: GPU での演算処理。 calcNext, swap 関数を確認することが できる。 GPU コードのプロファイリング (PGPROF) pgprof による GPU コードのプロファイリング
24.
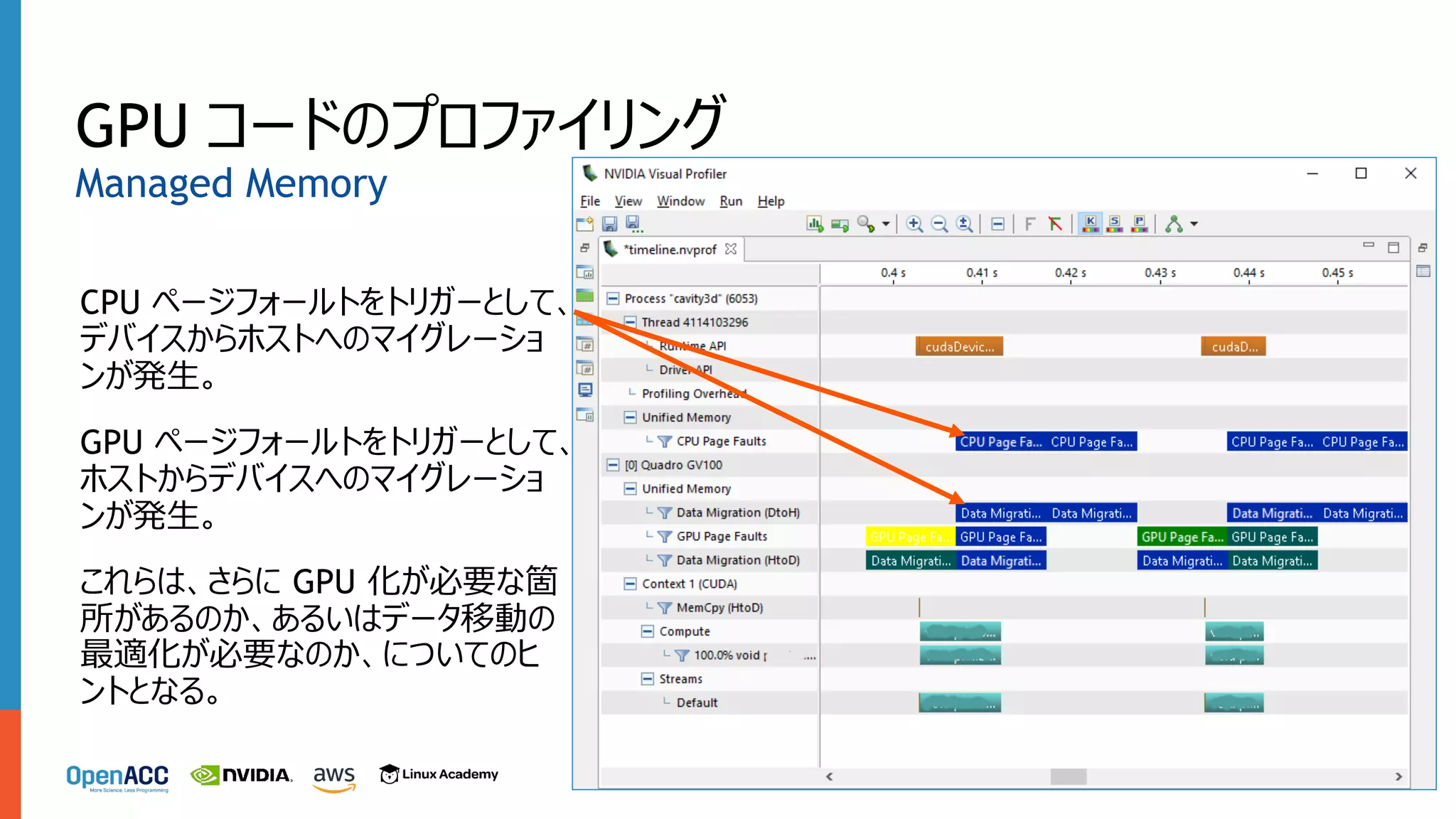
GPU コードのプロファイリング CPU ページフォールトをトリガーとして、 デバイスからホストへのマイグレーショ ンが発⽣。 GPU
ページフォールトをトリガーとして、 ホストからデバイスへのマイグレーショ ンが発⽣。 これらは、さらに GPU 化が必要な箇 所があるのか、あるいはデータ移動の 最適化が必要なのか、についてのヒ ントとなる。 Managed Memory
25.
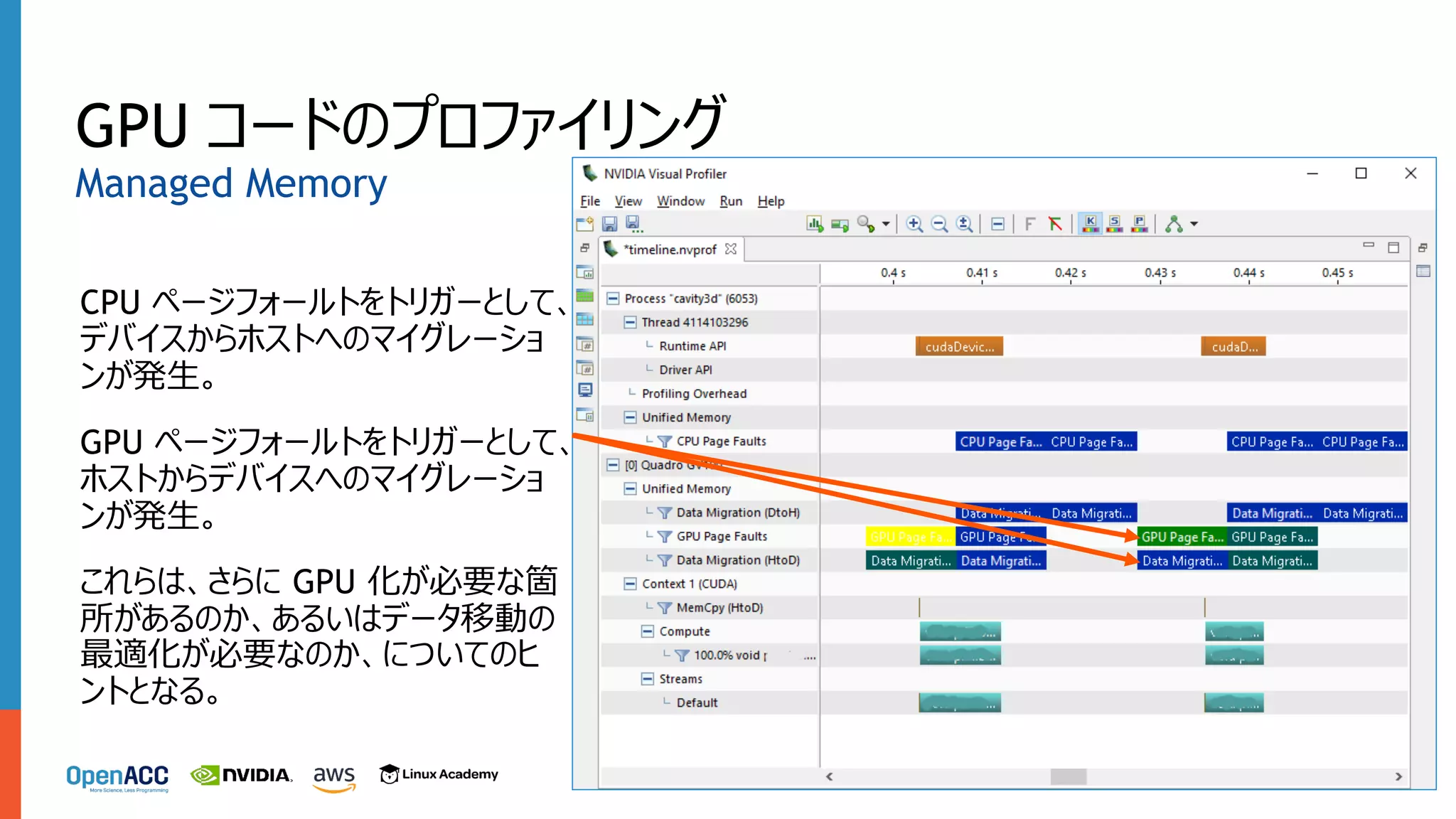
GPU コードのプロファイリング CPU ページフォールトをトリガーとして、 デバイスからホストへのマイグレーショ ンが発⽣。 GPU
ページフォールトをトリガーとして、 ホストからデバイスへのマイグレーショ ンが発⽣。 これらは、さらに GPU 化が必要な箇 所があるのか、あるいはデータ移動の 最適化が必要なのか、についてのヒ ントとなる。 Managed Memory
26.
ループの最適化
27.
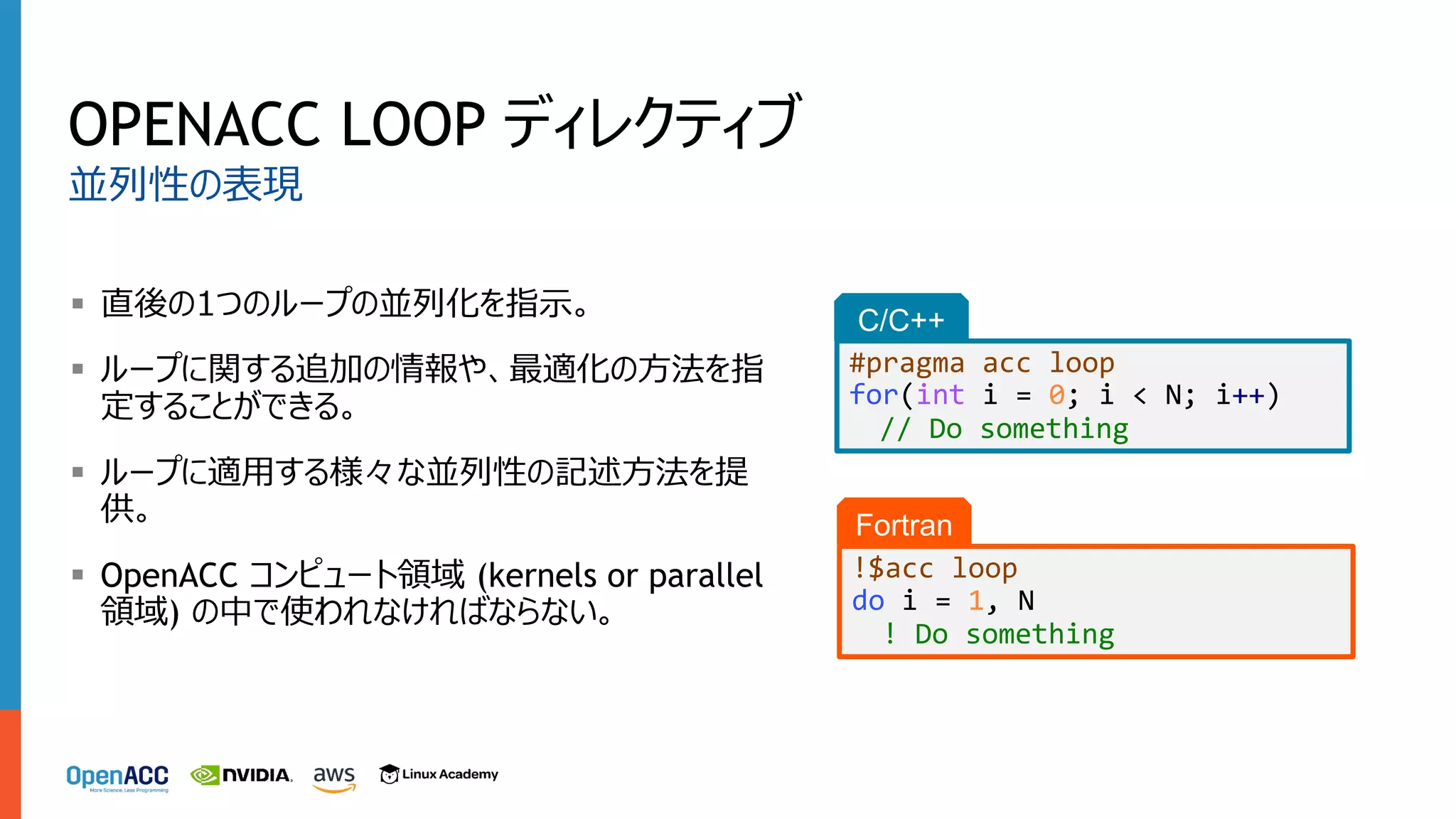
OPENACC LOOP ディレクティブ §
直後の1つのループの並列化を指⽰。 § ループに関する追加の情報や、最適化の⽅法を指 定することができる。 § ループに適⽤する様々な並列性の記述⽅法を提 供。 § OpenACC コンピュート領域 (kernels or parallel 領域) の中で使われなければならない。 並列性の表現 C/C++ #pragma acc loop for(int i = 0; i < N; i++) // Do something Fortran !$acc loop do i = 1, N ! Do something
28.
COLLAPSE クローズ § collapse(
N ) § 直後の N 個の tightly nested loops を結 合。 § 多次元のループ ネスト1次元のループに変換 することができる。 § ループ⻑を⻑くして、より多くの並列性を抽出 したり、メモリの局所性を向上させるのに有効。 #pragma acc parallel loop collapse(2) for( i = 0; i < size; i++ ) for( j = 0; j < size; j++ ) double tmp = 0.0f; #pragma acc loop reduction(+:tmp) for( k = 0; k < size; k++ ) tmp += a[i][k] * b[k][j]; c[i][j] = tmp;
29.
for( i =
0; i < 4; i++ ) for( j = 0; j < 4; j++ ) array[i][j] = 0.0f; COLLAPSE クローズ (0,0) (0,1) (0,2) (0,3) (1,0) (1,1) (1,2) (1,3) (2,0) (2,1) (2,2) (2,3) (3,0) (3,1) (3,2) (3,3) collapse( 2 ) #pragma acc parallel loop collapse(2) for( i = 0; i < 4; i++ ) for( j = 0; j < 4; j++ ) array[i][j] = 0.0f;
30.
COLLAPSE クローズ § 1つのループだけでは、⼗分な並列性を抽出できないかもしれない。 §
アウターループを collapse することで、gang の並列性を上げることができる。 § インナーループを collapse することで、vector の並列性を上げることができる。 § 全てのループを collapse することで、コンパイラに並列化の⾃由度を与えることができるが、デー タ局所性が犠牲になる場合もある。 いつ/なぜ使うべきか
31.
COLLAPSE クローズ #pragma acc
data copy(A[:n*m]) copyin(Anew[:n*m]) while ( err > tol && iter < iter_max ) { err=0.0; #pragma acc parallel loop reduction(max:err) collapse(2) copyin(A[0:n*m]) copy(Anew[0:n*m]) for( int j = 1; j < n-1; j++) { for(int i = 1; i < m-1; i++) { Anew[j][i] = 0.25 * (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]); err = max(err, abs(Anew[j][i] - A[j][i])); } } #pragma acc parallel loop collapse(2) copyin(Anew[0:n*m]) copyout(A[0:n*m]) for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { A[j][i] = Anew[j][i]; } } iter++; } 並列化の⾃由度を上げるため に、2つのループを1つに collapse
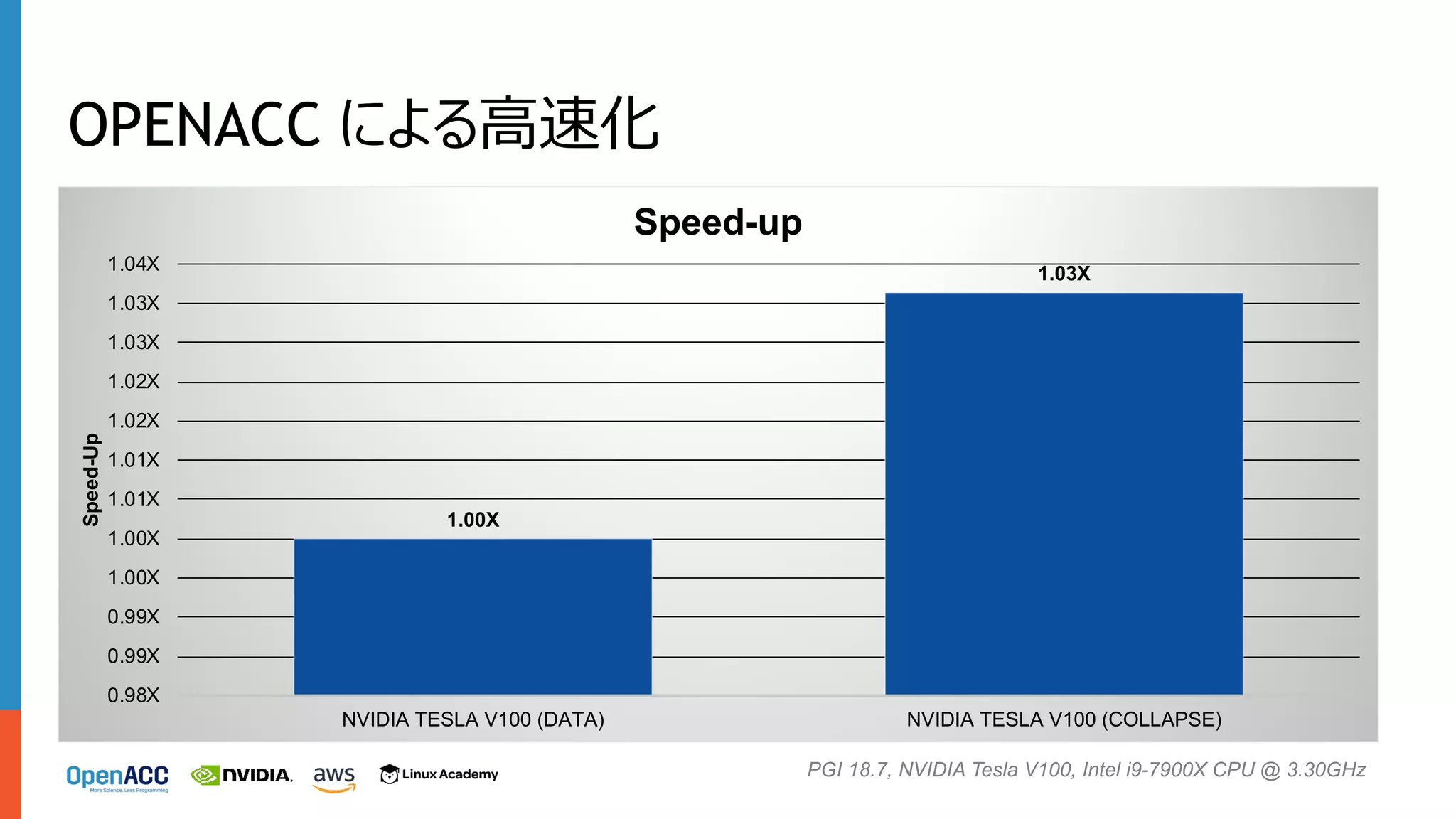
32.
OPENACC による⾼速化 1.00X 1.03X 0.98X 0.99X 0.99X 1.00X 1.00X 1.01X 1.01X 1.02X 1.02X 1.03X 1.03X 1.04X NVIDIA TESLA
V100 (DATA) NVIDIA TESLA V100 (COLLAPSE) Speed-Up Speed-up PGI 18.7, NVIDIA Tesla V100, Intel i9-7900X CPU @ 3.30GHz
33.
TILE クローズ § tile
( x , y , z, ...) § 多次元ループを、”tiles” または “blocks” に 分割。 § データ局所性を向上させられる場合がある。 § 複数の “tiles” を同時に実⾏可能。 #pragma acc kernels loop tile(32, 32) for( i = 0; i < size; i++ ) for( j = 0; j < size; j++ ) for( k = 0; k < size; k++ ) c[i][j] += a[i][k] * b[k][j];
34.
TILE クローズ (0,0) (0,1)
(0,3)(0,2) (1,0) (1,1) (1,3)(1,2) (2,0) (2,1) (2,3)(2,2) (3,0) (3,1) (3,3)(3,2) for(int x = 0; x < 4; x++){ for(int y = 0; y < 4; y++){ array[x][y]++; } } #pragma acc kernels loop tile(2,2) for(int x = 0; x < 4; x++){ for(int y = 0; y < 4; y++){ array[x][y]++; } } tile ( 2 , 2 ) (0,0) (0,1) (0,3)(0,2) (1,0) (1,1) (1,3)(1,2) (2,0) (2,1) (2,3)(2,2) (3,0) (3,1) (3,3)(3,2)
35.
TILE クローズ #pragma acc
data copy(A[:n*m]) copyin(Anew[:n*m]) while ( err > tol && iter < iter_max ) { err=0.0; #pragma acc parallel loop reduction(max:err) tile(32,32) copyin(A[0:n*m]) copy(Anew[0:n*m]) for( int j = 1; j < n-1; j++) { for(int i = 1; i < m-1; i++) { Anew[j][i] = 0.25 * (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]); err = max(err, abs(Anew[j][i] - A[j][i])); } } #pragma acc parallel loop tile(32,32) copyin(Anew[0:n*m]) copyout(A[0:n*m]) for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { A[j][i] = Anew[j][i]; } } iter++; } データ局所性を有効に使うた めに、32x32 の tiles を⽣成
36.
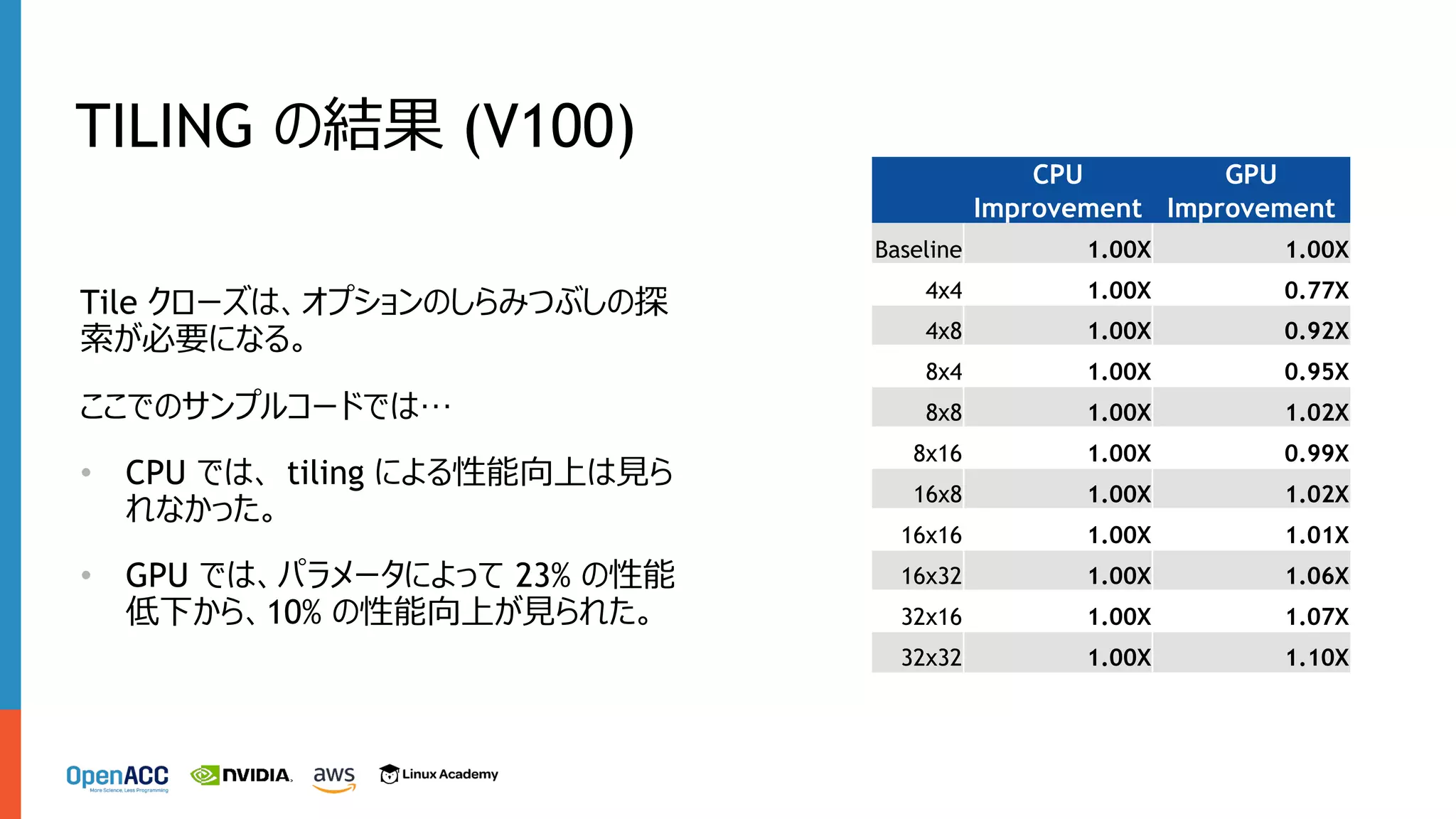
TILING の結果 (V100) Tile
クローズは、オプションのしらみつぶしの探 索が必要になる。 ここでのサンプルコードでは… • CPU では、 tiling による性能向上は⾒ら れなかった。 • GPU では、パラメータによって 23% の性能 低下から、10% の性能向上が⾒られた。 CPU Improvement GPU Improvement Baseline 1.00X 1.00X 4x4 1.00X 0.77X 4x8 1.00X 0.92X 8x4 1.00X 0.95X 8x8 1.00X 1.02X 8x16 1.00X 0.99X 16x8 1.00X 1.02X 16x16 1.00X 1.01X 16x32 1.00X 1.06X 32x16 1.00X 1.07X 32x32 1.00X 1.10X
37.
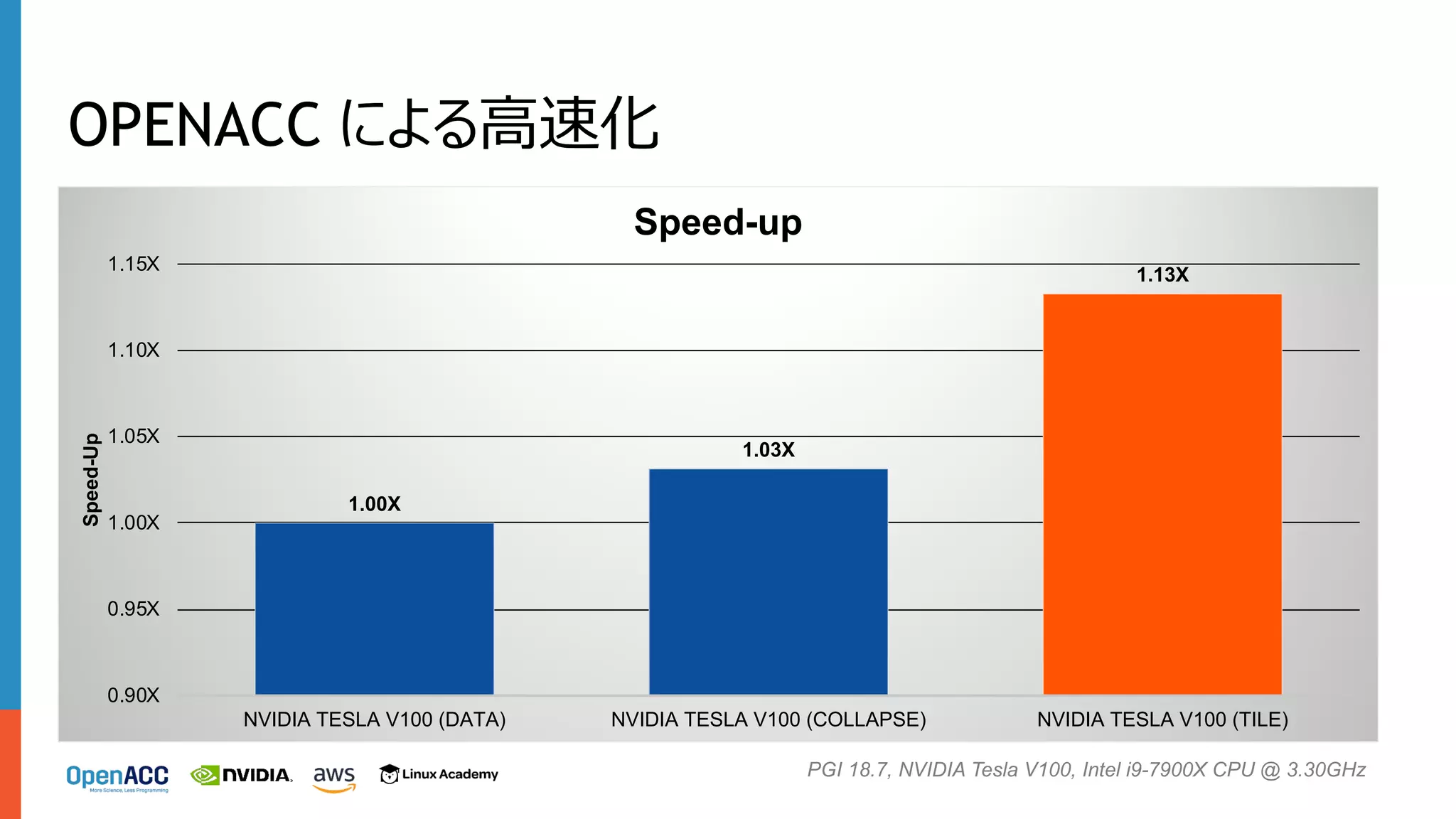
OPENACC による⾼速化 1.00X 1.03X 1.13X 0.90X 0.95X 1.00X 1.05X 1.10X 1.15X NVIDIA TESLA
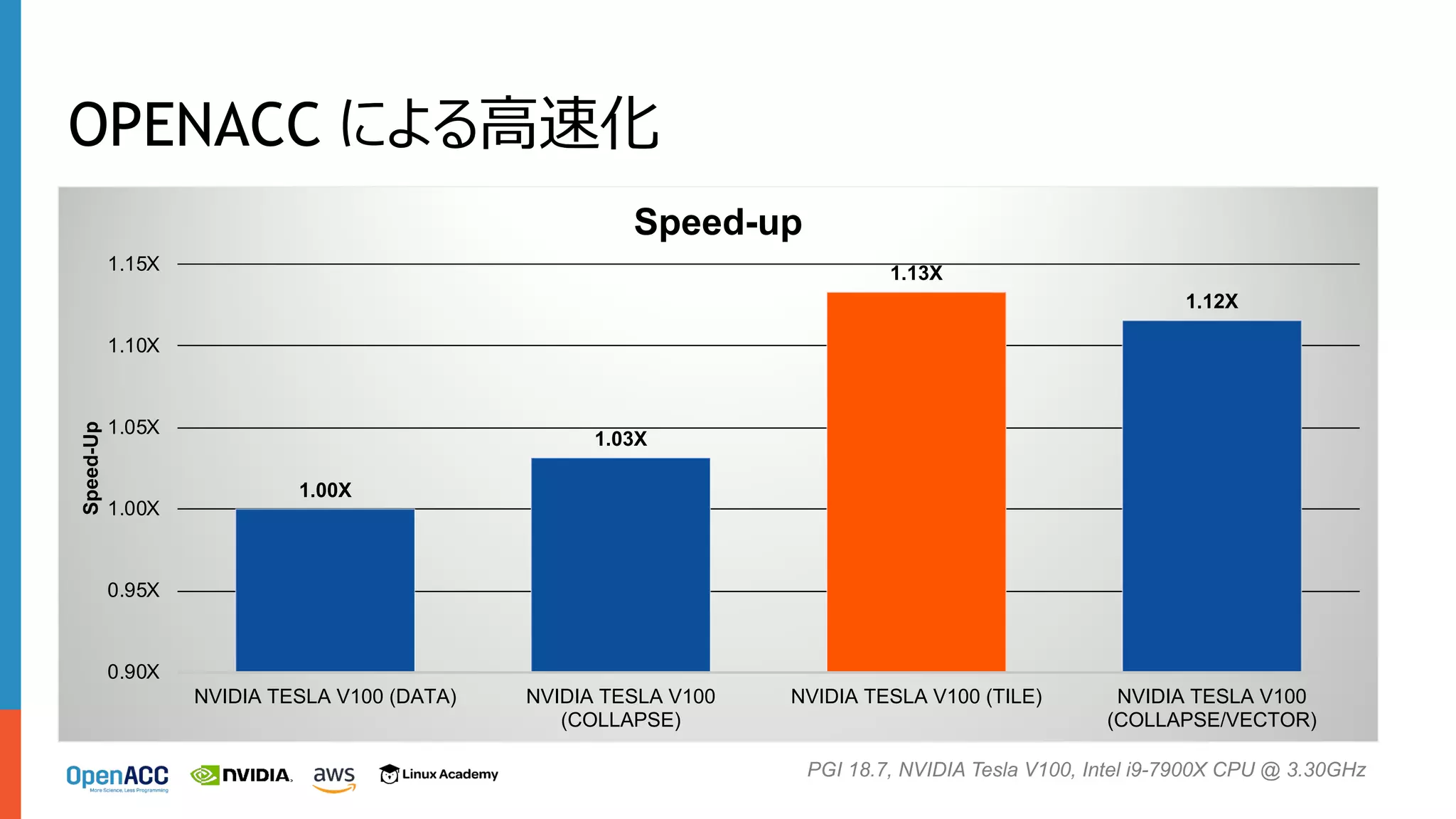
V100 (DATA) NVIDIA TESLA V100 (COLLAPSE) NVIDIA TESLA V100 (TILE) Speed-Up Speed-up PGI 18.7, NVIDIA Tesla V100, Intel i9-7900X CPU @ 3.30GHz
38.
GANG, WORKER, VECTOR
クローズ § 開発者はクローズによって、ループに対する並 列性のレベルをコンパイラに指⽰することがで きる︓ § gang – gang レベルの並列化 § worker – worker レベルの並列化 § vector – vector レベルの並列化 これらを組み合わせて使うことも可能。 #pragma acc parallel loop gang for( i = 0; i < size; i++ ) #pragma acc loop worker for( j = 0; j < size; j++ ) #pragma acc loop vector for( k = 0; k < size; k++ ) c[i][j] += a[i][k] * b[k][j]; #pragma acc parallel loop collapse(3) gang vector for( i = 0; i < size; i++ ) for( j = 0; j < size; j++ ) for( k = 0; k < size; k++ ) c[i][j] += a[i][k] * b[k][j];
39.
SEQ クローズ § Seq
(sequential の略) クローズは、そのルー プを逐次的に実⾏するようコンパイラに指⽰ する。 § 右のサンプル コードでは、外側2つのループは 並列化されるが、最も内側のループは逐次 的に実⾏される。 § コンパイラが⾃動で seq クローズを適⽤する 場合もある。 #pragma acc parallel loop for( i = 0; i < size; i++ ) #pragma acc loop for( j = 0; j < size; j++ ) #pragma acc loop seq for( k = 0; k < size; k++ ) c[i][j] += a[i][k] * b[k][j];
40.
GANGS, WORKERS, VECTORS
の調整 #pragma acc parallel num_gangs(2) num_workers(2) vector_length(32) { #pragma acc loop gang worker for(int x = 0; x < 4; x++){ #pragma acc loop vector for(int y = 0; y < 32; y++){ array[x][y]++; } } } 基本的にはコンパイラが⾃動で gang, worker の数、 vector ⻑さを選択するが、クローズを⽤いることで、 それらを指定することもできる。 § num_gangs(N) – N個の gang を⽣成 § num_workers(M) – M個の worker を⽣成 § vector_length(Q) – vector ⻑を Q に設定
41.
COLLAPSE クローズと VECTOR
⻑指定の組み合わせ #pragma acc data copy(A[:n*m]) copyin(Anew[:n*m]) while ( err > tol && iter < iter_max ) { err=0.0; #pragma acc parallel loop reduction(max:err) collapse(2) vector_length(1024) copyin(A[0:n*m]) copy(Anew[0:n*m]) for( int j = 1; j < n-1; j++) { for(int i = 1; i < m-1; i++) { Anew[j][i] = 0.25 * (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]); err = max(err, abs(Anew[j][i] - A[j][i])); } } #pragma acc parallel loop collapse(2) vector_length(1024) copyin(Anew[0:n*m]) copyout(A[0:n*m]) for( int j = 1; j < n-1; j++) { for( int i = 1; i < m-1; i++ ) { A[j][i] = Anew[j][i]; } } iter++; }
42.
OPENACC による⾼速化 1.00X 1.03X 1.13X 1.12X 0.90X 0.95X 1.00X 1.05X 1.10X 1.15X NVIDIA TESLA
V100 (DATA) NVIDIA TESLA V100 (COLLAPSE) NVIDIA TESLA V100 (TILE) NVIDIA TESLA V100 (COLLAPSE/VECTOR) Speed-Up Speed-up PGI 18.7, NVIDIA Tesla V100, Intel i9-7900X CPU @ 3.30GHz
43.
LOOP 最適化の⼤まかな指針(経験則) § 開発者が
gang の数を指定せずに、コンパイラに任せた⽅が良い場合が多い。 § ほとんどの場合、vector ⻑をチューニングするだけで、効果的にループを最適化することができる。 § Worker ループを使うことはまれ。Vector ⻑が極端に短い場合は、worker ループによって gang の中の並列性を向上させることができる。 § 可能であれば、vector ループは配列に連続にアクセスするのが望ましい。 § Gang は外側のループから、vector は内側のループから⽣成する。
44.
おわりに
45.
キー コンセプト 本講義で学んだこと… § GPU
プロファイルから最適化のための様々な情報が⼊⼿可能であること。 § はじめての、Gangs, Workers, and Vectors。 § Collapse クローズ。 § Tile クローズ。 § Gang/Worker/Vector クローズ。
46.
Resources https://www.openacc.org/resources Success Stories https://www.openacc.org/success-stories Events https://www.openacc.org/events OPENACC RESOURCES Guides
● Talks ● Tutorials ● Videos ● Books ● Spec ● Code Samples ● Teaching Materials ● Events ● Success Stories ● Courses ● Slack ● Stack Overflow Compilers and Tools https://www.openacc.org/tools FREE Compilers
Download




![OpenACC ディレクティブ
データ移動の
管理
並列実⾏の
開始
ループ マッピングの
最適化
#pragma acc data copyin(a,b) copyout(c)
{
...
#pragma acc parallel
{
#pragma acc loop gang vector
for (i = 0; i < n; ++i) {
c[i] = a[i] + b[i];
...
}
}
...
}
CPU, GPU, Manycore
移植性
相互操作可能
1つのソース コード
段階的](https://image.slidesharecdn.com/openacclecture20190625part3-190626091606/75/20190625-OpenACC-3-6-2048.jpg)
![while ( err > tol && iter < iter_max ) {
err=0.0;
#pragma acc parallel loop reduction(max:err)
for( int j = 1; j < n-1; j++) {
for( int i = 1; i < m-1; i++ ) {
Anew[OFFSET(j, i, m)] = 0.25 * ( A[OFFSET(j, i+1, m)] + A[OFFSET(j, i-1, m)]
+ A[OFFSET(j-1, i, m)] + A[OFFSET(j+1, i, m)]);
error = fmax( error, fabs(Anew[OFFSET(j, i, m)] - A[OFFSET(j, i , m)]));
}
}
#pragma acc parallel loop
for( int j = 1; j < n-1; j++) {
for( int i = 1; i < m-1; i++ ) {
A[OFFSET(j, i, m)] = Anew[OFFSET(j, i, m)];
}
}
iter++;
}
OPENACC PARALLEL LOOP による並列化
7
最初のループを並列化
max reduction を指定
2つ⽬のループを並列化
どのループを並列化するかのみを指⽰し、
どのように並列化するかの詳細は指⽰
していない。](https://image.slidesharecdn.com/openacclecture20190625part3-190626091606/75/20190625-OpenACC-3-7-2048.jpg)
![#pragma acc data copy(A[0:n*m]) copyin(Anew[0:n*m])
while ( err > tol && iter < iter_max ) {
err=0.0;
#pragma acc parallel loop reduction(max:err) copyin(A[0:n*m]) copy(Anew[0:n*m])
for( int j = 1; j < n-1; j++) {
for( int i = 1; i < m-1; i++ ) {
Anew[OFFSET(j, i, m)] = 0.25 * ( A[OFFSET(j, i+1, m)] + A[OFFSET(j, i-1, m)]
+ A[OFFSET(j-1, i, m)] + A[OFFSET(j+1, i, m)]);
error = fmax( error, fabs(Anew[OFFSET(j, i, m)] - A[OFFSET(j, i , m)]));
}
}
#pragma acc parallel loop copyin(Anew[0:n*m]) copyout(A[0:n*m])
for( int j = 1; j < n-1; j++) {
for( int i = 1; i < m-1; i++ ) {
A[OFFSET(j, i, m)] = Anew[OFFSET(j, i, m)];
}
}
iter++;
}
最適化されたデータ転送
必要な時のみ A をコピー。
Anew の初期条件はコピーす
るが、最終的な値はしない。](https://image.slidesharecdn.com/openacclecture20190625part3-190626091606/75/20190625-OpenACC-3-8-2048.jpg)











![COLLAPSE クローズ
§ collapse( N )
§ 直後の N 個の tightly nested loops を結
合。
§ 多次元のループ ネスト1次元のループに変換
することができる。
§ ループ⻑を⻑くして、より多くの並列性を抽出
したり、メモリの局所性を向上させるのに有効。
#pragma acc parallel loop collapse(2)
for( i = 0; i < size; i++ )
for( j = 0; j < size; j++ )
double tmp = 0.0f;
#pragma acc loop reduction(+:tmp)
for( k = 0; k < size; k++ )
tmp += a[i][k] * b[k][j];
c[i][j] = tmp;](https://image.slidesharecdn.com/openacclecture20190625part3-190626091606/75/20190625-OpenACC-3-28-2048.jpg)
![for( i = 0; i < 4; i++ )
for( j = 0; j < 4; j++ )
array[i][j] = 0.0f;
COLLAPSE クローズ
(0,0) (0,1) (0,2) (0,3)
(1,0) (1,1) (1,2) (1,3)
(2,0) (2,1) (2,2) (2,3)
(3,0) (3,1) (3,2) (3,3)
collapse( 2 )
#pragma acc parallel loop collapse(2)
for( i = 0; i < 4; i++ )
for( j = 0; j < 4; j++ )
array[i][j] = 0.0f;](https://image.slidesharecdn.com/openacclecture20190625part3-190626091606/75/20190625-OpenACC-3-29-2048.jpg)

![COLLAPSE クローズ
#pragma acc data copy(A[:n*m]) copyin(Anew[:n*m])
while ( err > tol && iter < iter_max ) {
err=0.0;
#pragma acc parallel loop reduction(max:err) collapse(2)
copyin(A[0:n*m]) copy(Anew[0:n*m])
for( int j = 1; j < n-1; j++) {
for(int i = 1; i < m-1; i++) {
Anew[j][i] = 0.25 * (A[j][i+1] + A[j][i-1] +
A[j-1][i] + A[j+1][i]);
err = max(err, abs(Anew[j][i] - A[j][i]));
}
}
#pragma acc parallel loop collapse(2)
copyin(Anew[0:n*m]) copyout(A[0:n*m])
for( int j = 1; j < n-1; j++) {
for( int i = 1; i < m-1; i++ ) {
A[j][i] = Anew[j][i];
}
}
iter++;
}
並列化の⾃由度を上げるため
に、2つのループを1つに
collapse](https://image.slidesharecdn.com/openacclecture20190625part3-190626091606/75/20190625-OpenACC-3-31-2048.jpg)
![TILE クローズ
§ tile ( x , y , z, ...)
§ 多次元ループを、”tiles” または “blocks” に
分割。
§ データ局所性を向上させられる場合がある。
§ 複数の “tiles” を同時に実⾏可能。
#pragma acc kernels loop tile(32, 32)
for( i = 0; i < size; i++ )
for( j = 0; j < size; j++ )
for( k = 0; k < size; k++ )
c[i][j] += a[i][k] * b[k][j];](https://image.slidesharecdn.com/openacclecture20190625part3-190626091606/75/20190625-OpenACC-3-33-2048.jpg)
![TILE クローズ
(0,0) (0,1) (0,3)(0,2)
(1,0) (1,1) (1,3)(1,2)
(2,0) (2,1) (2,3)(2,2)
(3,0) (3,1) (3,3)(3,2)
for(int x = 0; x < 4; x++){
for(int y = 0; y < 4; y++){
array[x][y]++;
}
}
#pragma acc kernels loop tile(2,2)
for(int x = 0; x < 4; x++){
for(int y = 0; y < 4; y++){
array[x][y]++;
}
}
tile ( 2 , 2 )
(0,0) (0,1) (0,3)(0,2)
(1,0) (1,1) (1,3)(1,2)
(2,0) (2,1) (2,3)(2,2)
(3,0) (3,1) (3,3)(3,2)](https://image.slidesharecdn.com/openacclecture20190625part3-190626091606/75/20190625-OpenACC-3-34-2048.jpg)
![TILE クローズ
#pragma acc data copy(A[:n*m]) copyin(Anew[:n*m])
while ( err > tol && iter < iter_max ) {
err=0.0;
#pragma acc parallel loop reduction(max:err) tile(32,32)
copyin(A[0:n*m]) copy(Anew[0:n*m])
for( int j = 1; j < n-1; j++) {
for(int i = 1; i < m-1; i++) {
Anew[j][i] = 0.25 * (A[j][i+1] + A[j][i-1] +
A[j-1][i] + A[j+1][i]);
err = max(err, abs(Anew[j][i] - A[j][i]));
}
}
#pragma acc parallel loop tile(32,32)
copyin(Anew[0:n*m]) copyout(A[0:n*m])
for( int j = 1; j < n-1; j++) {
for( int i = 1; i < m-1; i++ ) {
A[j][i] = Anew[j][i];
}
}
iter++;
}
データ局所性を有効に使うた
めに、32x32 の tiles を⽣成](https://image.slidesharecdn.com/openacclecture20190625part3-190626091606/75/20190625-OpenACC-3-35-2048.jpg)
![GANG, WORKER, VECTOR クローズ
§ 開発者はクローズによって、ループに対する並
列性のレベルをコンパイラに指⽰することがで
きる︓
§ gang – gang レベルの並列化
§ worker – worker レベルの並列化
§ vector – vector レベルの並列化
これらを組み合わせて使うことも可能。
#pragma acc parallel loop gang
for( i = 0; i < size; i++ )
#pragma acc loop worker
for( j = 0; j < size; j++ )
#pragma acc loop vector
for( k = 0; k < size; k++ )
c[i][j] += a[i][k] * b[k][j];
#pragma acc parallel loop
collapse(3) gang vector
for( i = 0; i < size; i++ )
for( j = 0; j < size; j++ )
for( k = 0; k < size; k++ )
c[i][j] += a[i][k] * b[k][j];](https://image.slidesharecdn.com/openacclecture20190625part3-190626091606/75/20190625-OpenACC-3-38-2048.jpg)
![SEQ クローズ
§ Seq (sequential の略) クローズは、そのルー
プを逐次的に実⾏するようコンパイラに指⽰
する。
§ 右のサンプル コードでは、外側2つのループは
並列化されるが、最も内側のループは逐次
的に実⾏される。
§ コンパイラが⾃動で seq クローズを適⽤する
場合もある。
#pragma acc parallel loop
for( i = 0; i < size; i++ )
#pragma acc loop
for( j = 0; j < size; j++ )
#pragma acc loop seq
for( k = 0; k < size; k++ )
c[i][j] += a[i][k] * b[k][j];](https://image.slidesharecdn.com/openacclecture20190625part3-190626091606/75/20190625-OpenACC-3-39-2048.jpg)
![GANGS, WORKERS, VECTORS の調整
#pragma acc parallel num_gangs(2)
num_workers(2) vector_length(32)
{
#pragma acc loop gang worker
for(int x = 0; x < 4; x++){
#pragma acc loop vector
for(int y = 0; y < 32; y++){
array[x][y]++;
}
}
}
基本的にはコンパイラが⾃動で gang, worker の数、
vector ⻑さを選択するが、クローズを⽤いることで、
それらを指定することもできる。
§ num_gangs(N) – N個の gang を⽣成
§ num_workers(M) – M個の worker を⽣成
§ vector_length(Q) – vector ⻑を Q に設定](https://image.slidesharecdn.com/openacclecture20190625part3-190626091606/75/20190625-OpenACC-3-40-2048.jpg)
![COLLAPSE クローズと VECTOR ⻑指定の組み合わせ
#pragma acc data copy(A[:n*m]) copyin(Anew[:n*m])
while ( err > tol && iter < iter_max ) {
err=0.0;
#pragma acc parallel loop reduction(max:err) collapse(2) vector_length(1024)
copyin(A[0:n*m]) copy(Anew[0:n*m])
for( int j = 1; j < n-1; j++) {
for(int i = 1; i < m-1; i++) {
Anew[j][i] = 0.25 * (A[j][i+1] + A[j][i-1] +
A[j-1][i] + A[j+1][i]);
err = max(err, abs(Anew[j][i] - A[j][i]));
}
}
#pragma acc parallel loop collapse(2) vector_length(1024)
copyin(Anew[0:n*m]) copyout(A[0:n*m])
for( int j = 1; j < n-1; j++) {
for( int i = 1; i < m-1; i++ ) {
A[j][i] = Anew[j][i];
}
}
iter++;
}](https://image.slidesharecdn.com/openacclecture20190625part3-190626091606/75/20190625-OpenACC-3-41-2048.jpg)























![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Envir...](https://cdn.slidesharecdn.com/ss_thumbnails/20201023voxelposekuboshizuma-201023025841-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)














































