Downloaded 62 times






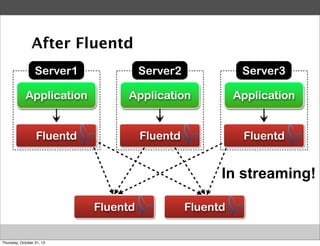


![Example (apache to mongo)
2013-10-30 01:33:51
apache.log
Web Server
{
"host": "127.0.0.1",
"method": "GET",
...
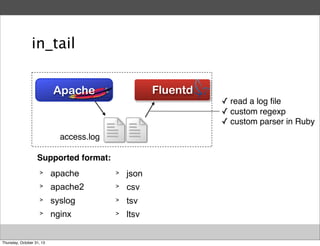
tail
127.0.0.1
127.0.0.1
127.0.0.1
127.0.0.1
127.0.0.1
-
-
[30/Oct/2013:07:26:27]
[30/Oct/2013:07:26:30]
[30/Oct/2013:07:26:32]
[30/Oct/2013:07:26:40]
[30/Oct/2013:07:27:01]
...
Thursday, October 31, 13
"GET
"GET
"GET
"GET
"GET
/
/
/
/
/
...
...
...
...
...
}
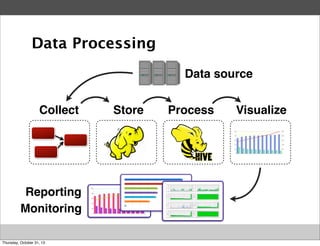
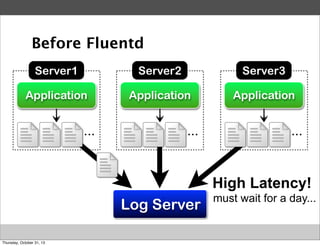
Fluentd
event
buffering
insert](https://image.slidesharecdn.com/fluentd-introduction-at-ipros-131030215805-phpapp01/85/Fluentd-introduction-at-ipros-13-320.jpg)

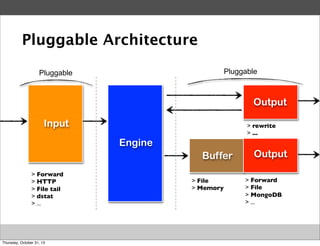




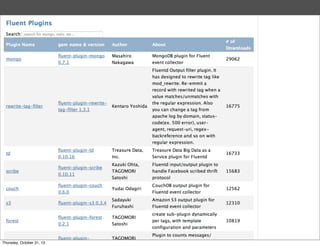
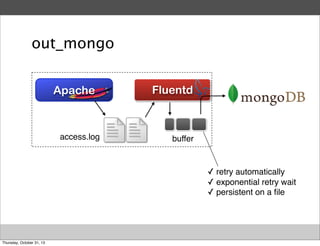
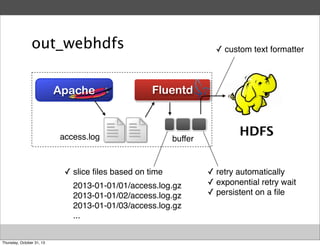
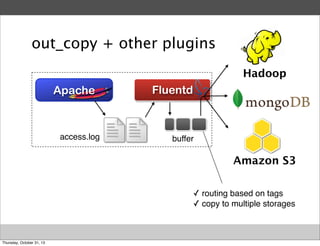
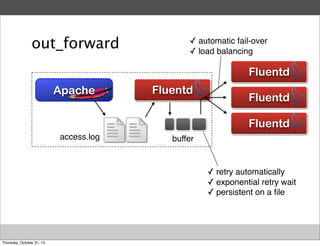
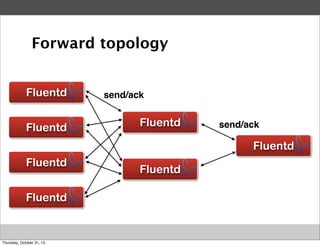
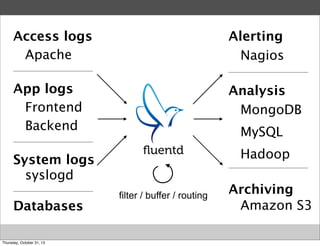



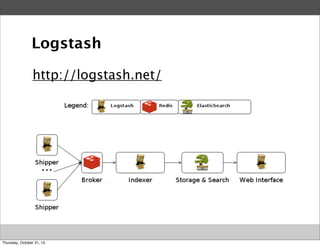


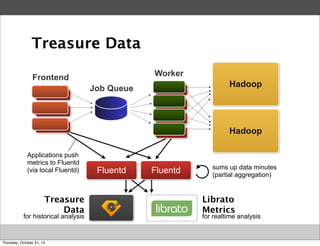
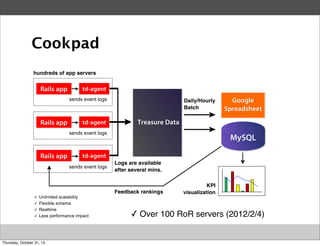
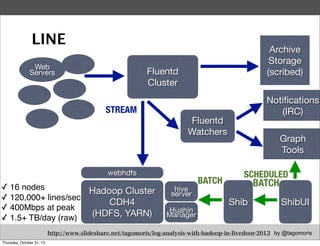






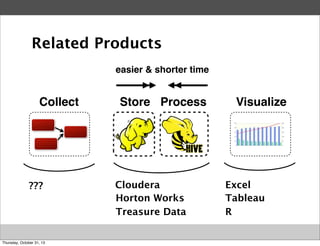
Masahiro Nakagawa from Treasure Data gave a presentation on Fluentd, an open source log collector. Fluentd allows for reliable and structured logging, forwarding, and processing of data through its pluggable architecture. It can collect logs from various sources and output to different destinations using plugins. Common uses of Fluentd include log aggregation, monitoring, and analysis on large-scale architectures.











































































































