Download as PDF, PPTX







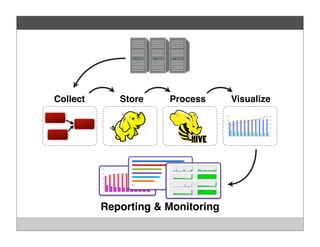
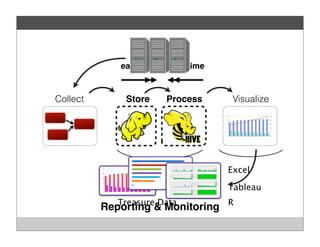
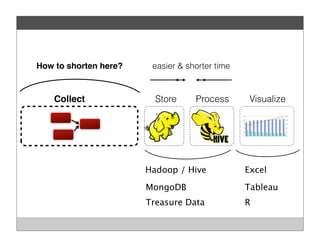
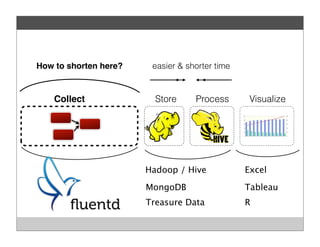
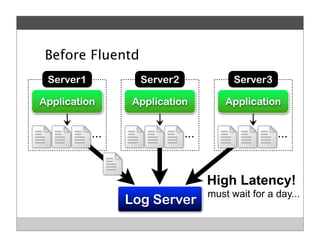
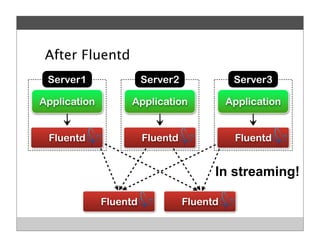


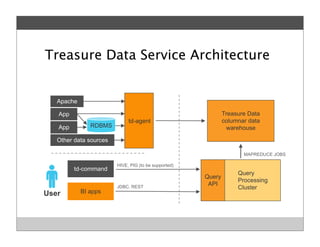
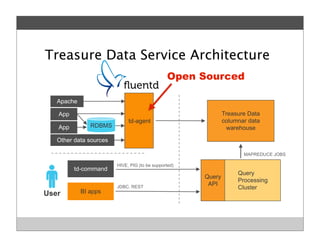
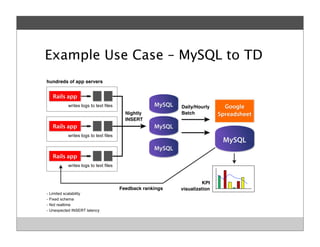
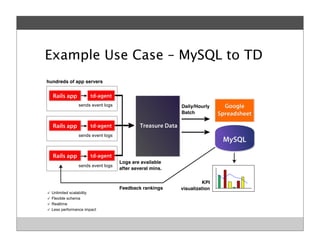


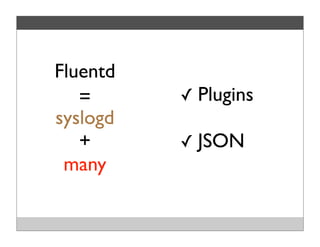
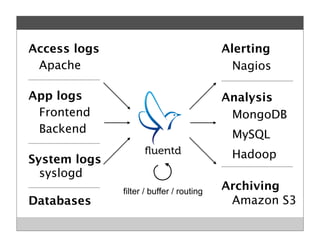
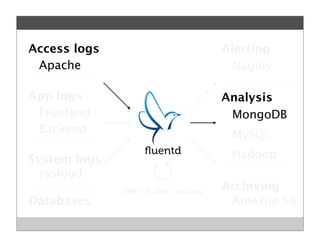
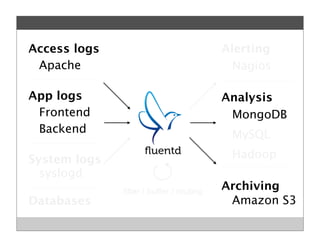
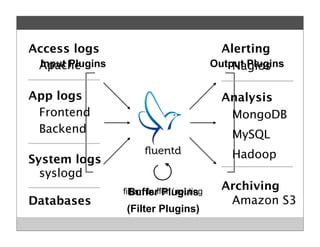
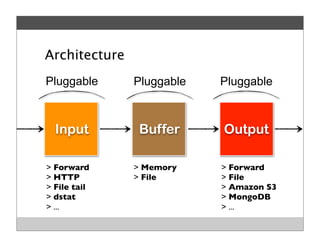
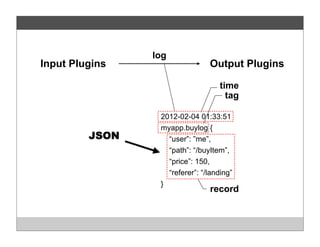
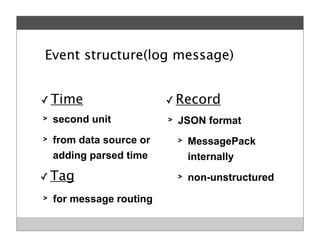
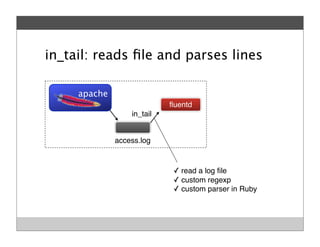
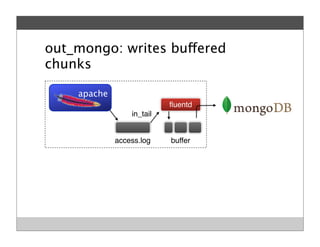
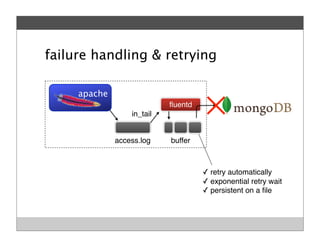
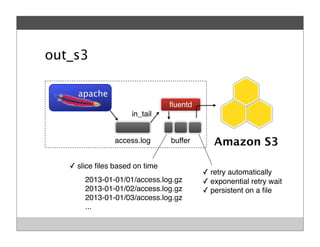
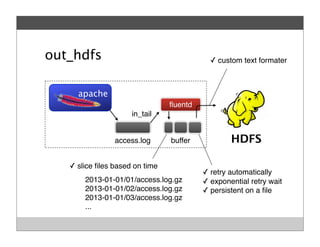
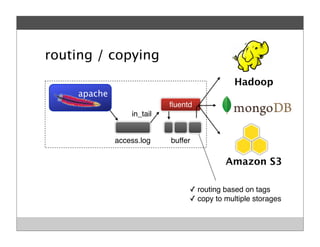
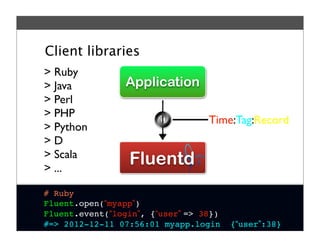
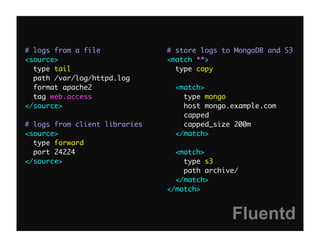
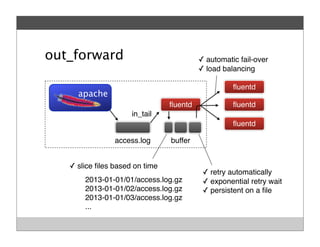
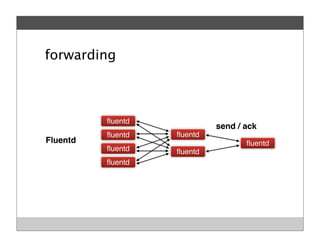


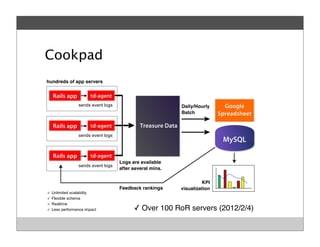
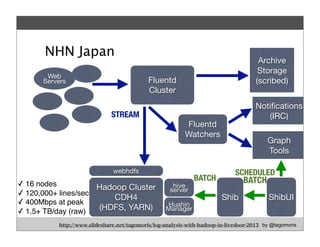
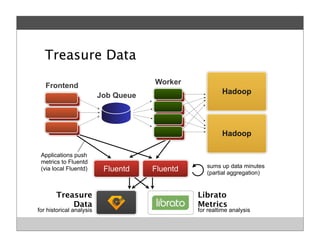



Fluentd is an open source log collector that allows flexible collection and routing of log data. It uses JSON format for log messages and supports many input and output plugins. Fluentd can collect logs from files, network services, and applications before routing them to storage and analysis services like MongoDB, HDFS, and Treasure Data. The open source project has grown a large community contributing over 100 plugins to make log collection and processing easier.










![[March sn meetup] apache pulsar + apache nifi for cloud data lake](https://cdn.slidesharecdn.com/ss_thumbnails/marchsnmeetupapachepulsarapachenififorclouddatalake-220311125943-thumbnail.jpg?width=640&height=640&fit=bounds)
























































