Download as PDF, PPTX






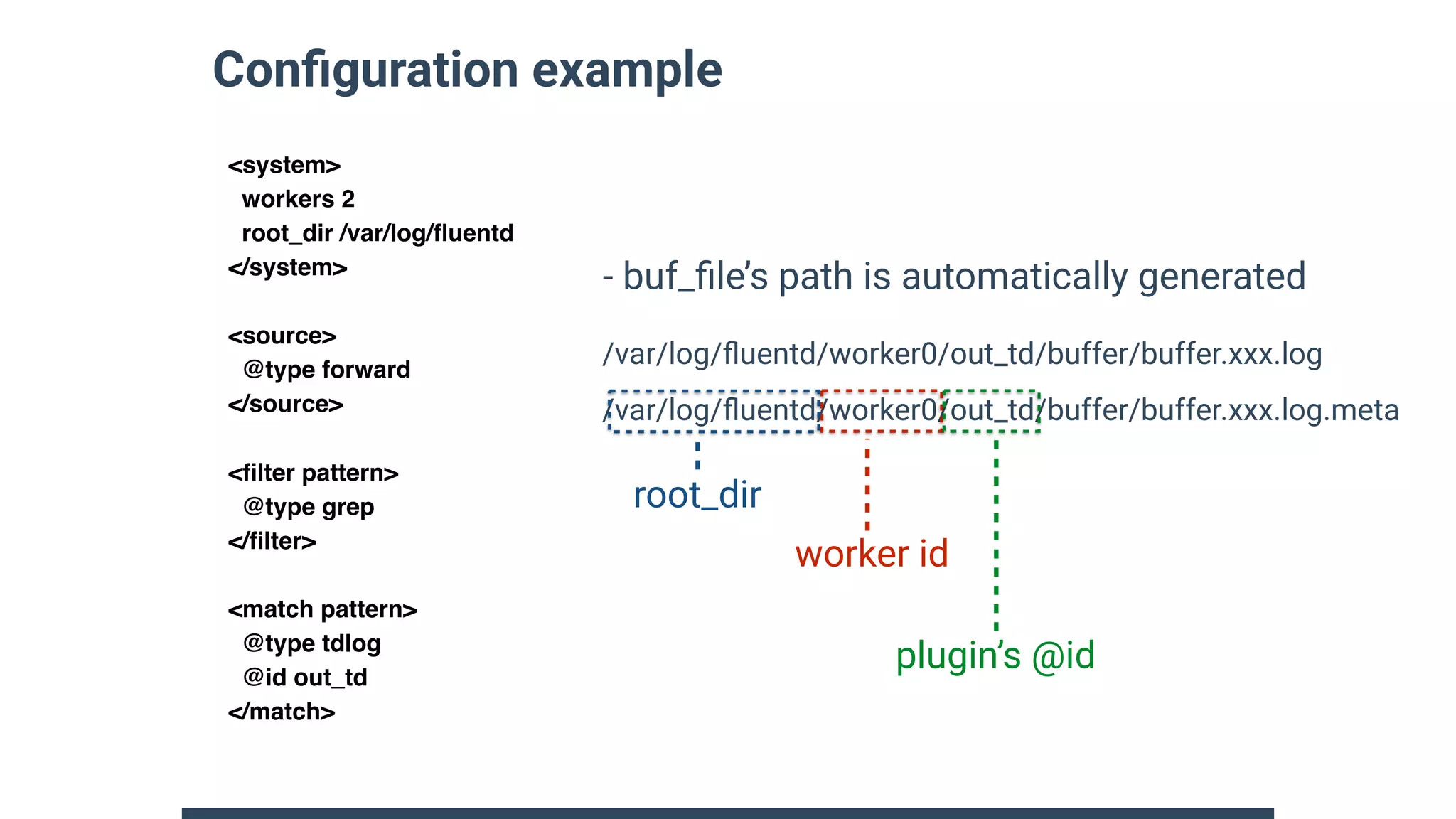
![Buffer keys and placeholders
• Dynamic parameters for table name, object path and more
• We can embed time, tag and any field with placeholder
<match s3.**>
@type s3
aws_key_id "#{ENV['AWS_ACCESS_KEY']}"
aws_sec_key "#{ENV['AWS_SECRETA_KEY']}"
s3_bucket fluent-plugin-s3
path test/%Y/%m/${tag}/${key}/
<buffer time,tag,key>
timekey 3600
</buffer>
</match>
http://docs.fluentd.org/v1.0/articles/buffer-section
time: 2018-02-15 12:00:00 +0700
tag: “test”
record: {“key”:”hello”}
- Event sample
test/2018/2/test/hello/
- Generated “path”](https://image.slidesharecdn.com/fluentd-v1-and-future-at-techtalk-180418050650/75/Fluentd-v1-and-future-at-techtalk-9-2048.jpg)




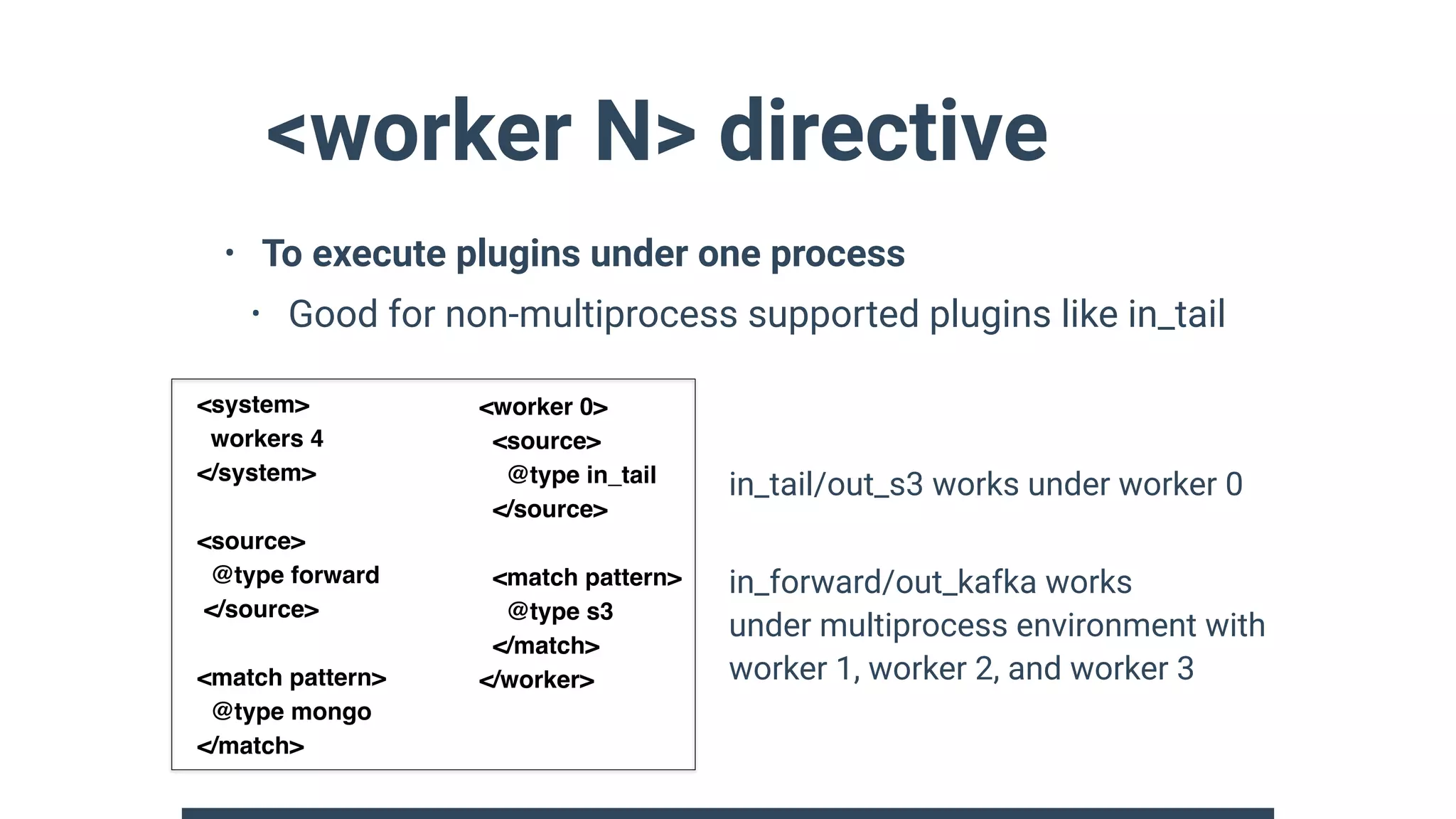



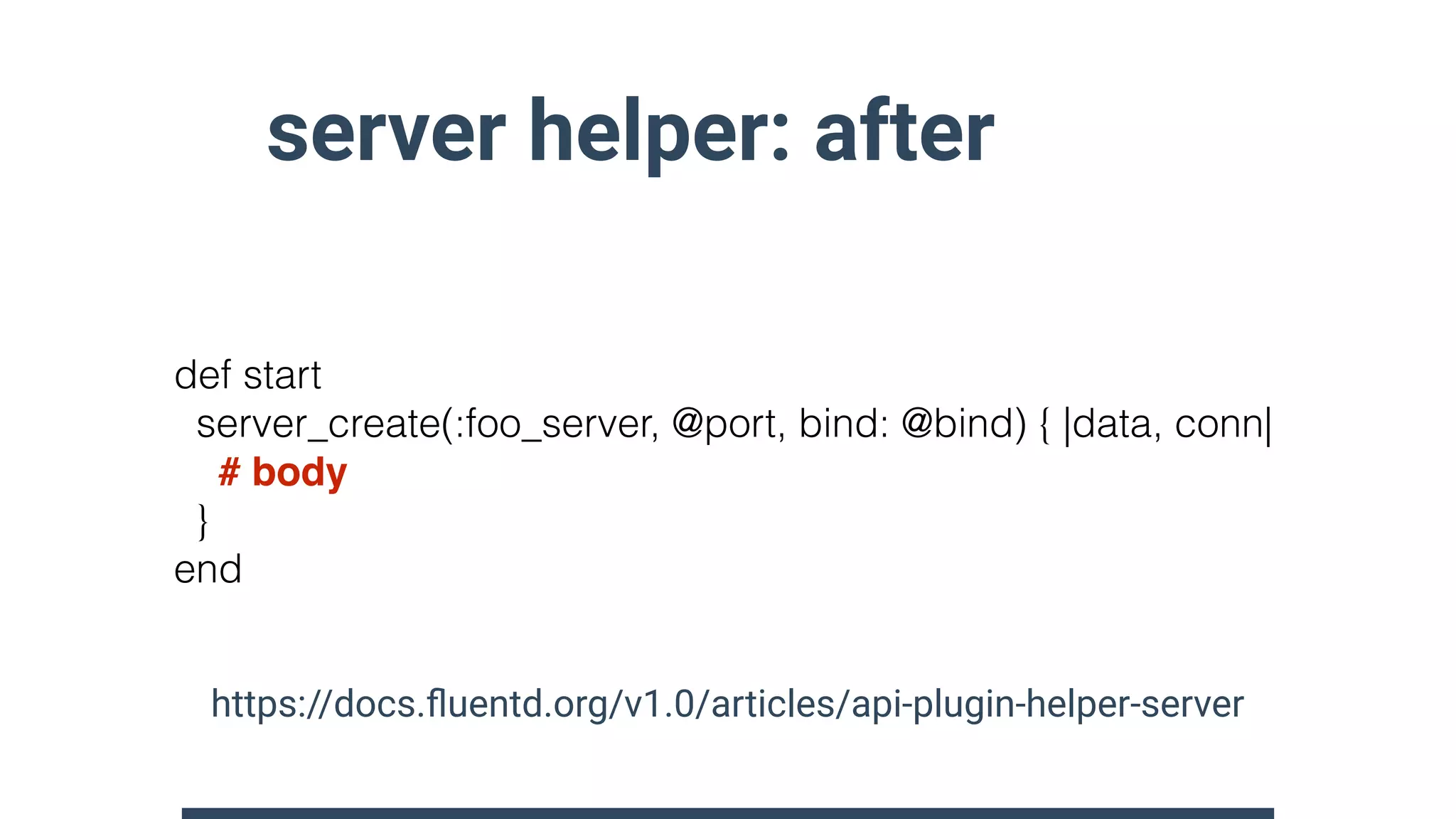
![record_accessor helper
• access / delete support for nested field
• e.g. parser’s key_name parameter uses this helper
• Provide two syntax for configuration
• $.field1.field2 == record[“field1”][“field2”]
• $[“field1”][“field2”] == record[“field1”][“field2”]
ra = record_accessor_create(”$.user.name”)
ra.call(record) # access record[”$.user”][”name”]
ra.delete(record) # delete record[”$.user”][”name”]](https://image.slidesharecdn.com/fluentd-v1-and-future-at-techtalk-180418050650/75/Fluentd-v1-and-future-at-techtalk-21-2048.jpg)

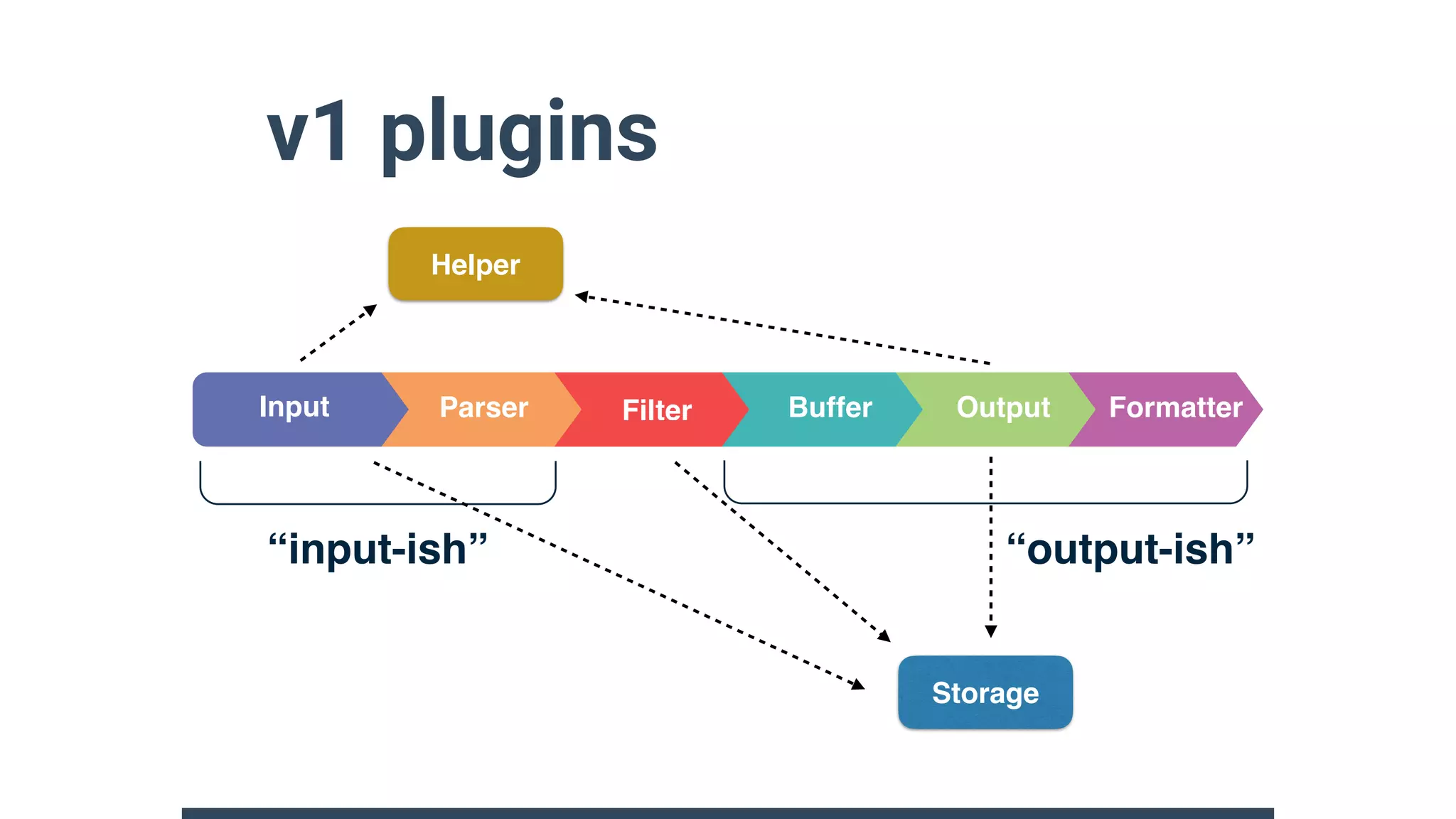












Fluentd v1 provides major improvements over v0.12 including nanosecond event time resolution, multi-core support, Windows support, and new plugin APIs. The new plugin APIs provide well-controlled lifecycles and integrate all output plugins. v1 also introduces a server engine based supervisor, dynamic buffering capabilities, and various plugin helpers. While maintaining compatibility with v0.12 plugins, v1 focuses on ease of use, stability, performance and flexibility.