Download as PDF, PPTX










































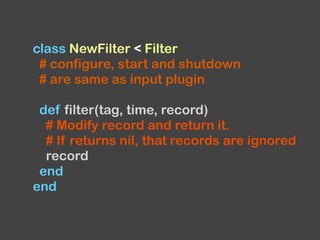









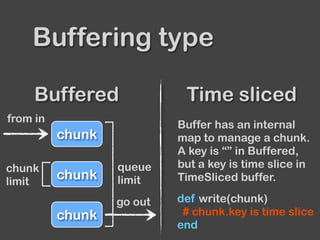

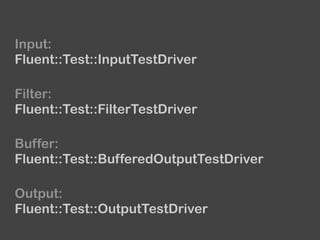
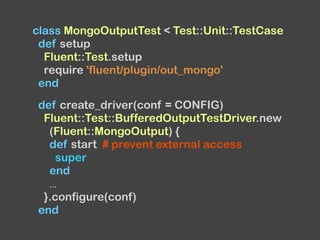
![...
def test_format
# test format using emit and expect_format
end
def test_write
d = create_driver
t = emit_documents(d)
# return a result of write method
collection_name, documents = d.run
assert_equal([{...}, {...}, ...], documents)
assert_equal('test', collection_name)
end
...
end](https://image.slidesharecdn.com/diveintofluentdpluginv0-151005105435-lva1-app6891/85/Dive-into-Fluentd-plugin-v0-12-68-320.jpg)





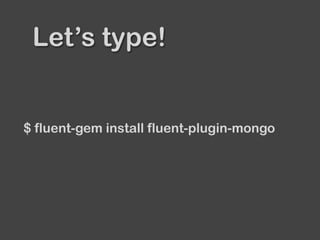
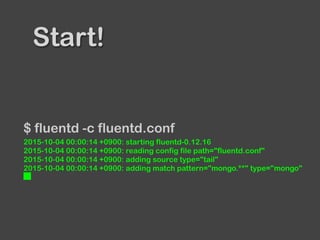
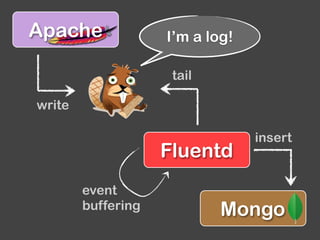
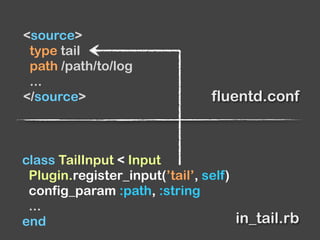
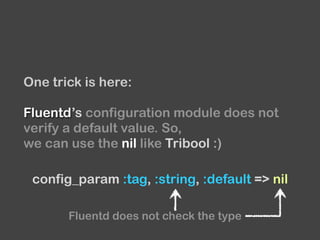
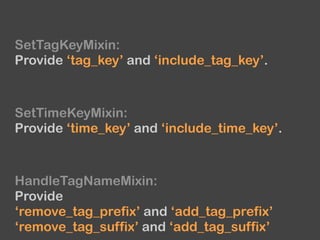
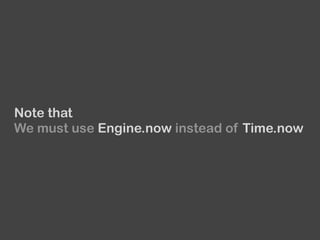
The document provides an overview of Fluentd and its plugin architecture, detailing input, filter, output, and buffer mechanisms. It includes examples of configuring Fluentd with plugins, particularly fluent-plugin-mongo, and discusses visualization tools, testing methods, and third-party plugins. The guide highlights the use of Ruby for development, the importance of message serialization, and best practices for plugin integration and data handling.


























![[Webinar] WSO2 Enterprise Integrator 7.1.0 Release](https://cdn.slidesharecdn.com/ss_thumbnails/wso2enterpriseintegrator7-200813070253-thumbnail.jpg?width=640&height=640&fit=bounds)




















































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)











