Downloaded 115 times






![§ Stateless runtime by design
• No continuous operators
• UDFs are assumed to be stateless
§ State can be generated as a stream of
RDDs: updateStateByKey(…)
𝒇:
𝑺𝒆𝒒[𝒊𝒏 𝒌], 𝒔𝒕𝒂𝒕𝒆 𝒌 ⟶ 𝒔𝒕𝒂𝒕𝒆.
𝒌
§ 𝒇 is scoped to a specific key
§ Exactly-once semantics
9Apache Flink Meetup @ MapR2015-‐‑08-‐‑27](https://image.slidesharecdn.com/statefulstreamingmaprfinal-150828030935-lva1-app6892/85/Stateful-Distributed-Stream-Processing-9-320.jpg)
,
true,
initialRDD)
val updateFunc = (values: Seq[Int], state: Option[Int]) => {
val currentCount = values.sum
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}
Spark Streaming Word Count
10Apache Flink Meetup @ MapR2015-‐‑08-‐‑27](https://image.slidesharecdn.com/statefulstreamingmaprfinal-150828030935-lva1-app6892/85/Stateful-Distributed-Stream-Processing-10-320.jpg)



![Flink Word Count
words.keyBy(x => x).mapWithState {
(word, count: Option[Int]) =>
{
val newCount = count.getOrElse(0) + 1
val output = (word, newCount)
(output, Some(newCount))
}
}
15Apache Flink Meetup @ MapR2015-‐‑08-‐‑27](https://image.slidesharecdn.com/statefulstreamingmaprfinal-150828030935-lva1-app6892/85/Stateful-Distributed-Stream-Processing-15-320.jpg)
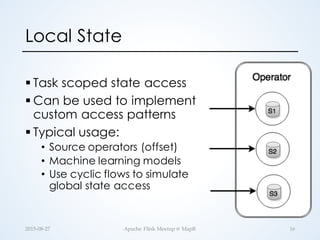

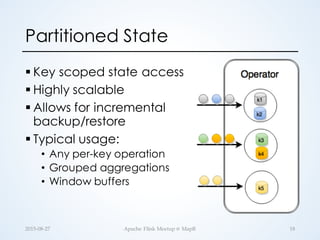
![Partitioned State Example (Scala)
// Compute the current average of each city's temperature
temps.keyBy("city").mapWithState {
(in: Temp, state: Option[(Double, Long)]) =>
{
val current = state.getOrElse((0.0, 0L))
val updated = (current._1 + in.temp, current._2 + 1)
val avg = Temp(in.city, updated._1 / updated._2)
(avg, Some(updated))
}
}
case class Temp(city: String, temp: Double)
19Apache Flink Meetup @ MapR2015-‐‑08-‐‑27](https://image.slidesharecdn.com/statefulstreamingmaprfinal-150828030935-lva1-app6892/85/Stateful-Distributed-Stream-Processing-19-320.jpg)
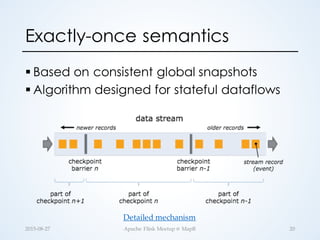
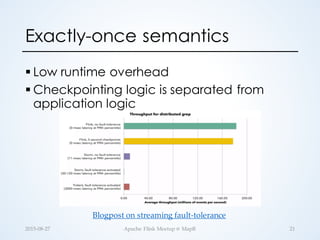



The document discusses stateful distributed stream processing, highlighting its definition, challenges, and the implementation of state in various open-source systems like Apache Flink. Key concepts include stateful processing examples such as window aggregations and machine learning, as well as the importance of scalability and fault-tolerance. Ultimately, Flink aims to balance expressivity, scalability, and exactly-once semantics in streaming applications.























































































