Downloaded 13 times


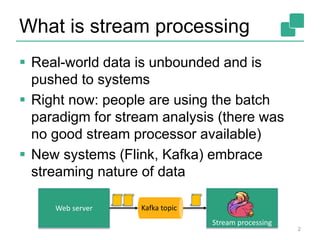




![APIs for stream and batch
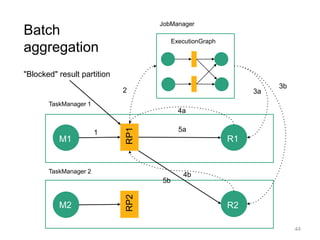
22
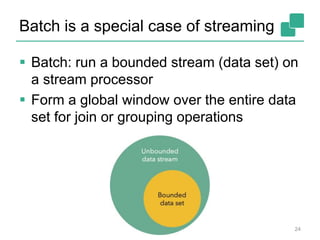
case class Word (word: String, frequency: Int)
val lines: DataStream[String] = env.fromSocketStream(...)
lines.flatMap {line => line.split(" ")
.map(word => Word(word,1))}
.window(Time.of(5,SECONDS)).every(Time.of(1,SECONDS))
.groupBy("word").sum("frequency")
.print()
val lines: DataSet[String] = env.readTextFile(...)
lines.flatMap {line => line.split(" ")
.map(word => Word(word,1))}
.groupBy("word").sum("frequency")
.print()
DataSet API (batch):
DataStream API (streaming):](https://image.slidesharecdn.com/chicagomeetup-flinkarch-151030024628-lva1-app6891/85/Chicago-Flink-Meetup-Flink-s-streaming-architecture-22-320.jpg)
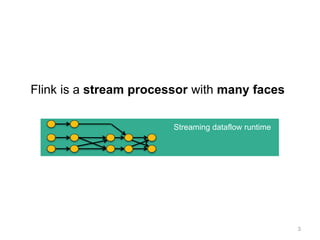
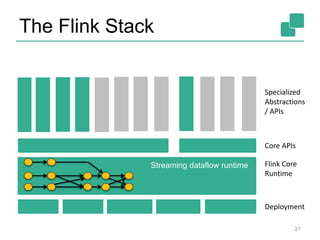
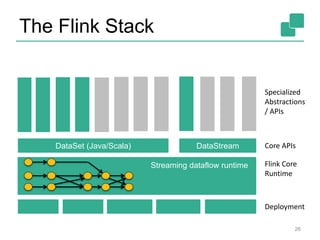
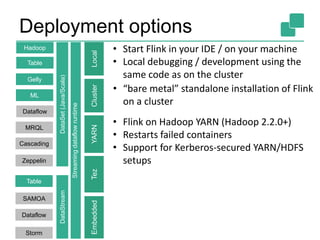
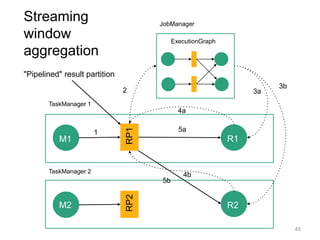
![The Flink Stack
23
Streaming dataflow runtime
DataSet (Java/Scala) DataStream (Java/Scala)
Experimental
Python API also
available
Data Source
orders.tbl
Filter
Map DataSource
lineitem.tbl
Join
Hybrid Hash
buildHT probe
hash-part [0] hash-part [0]
GroupRed
sort
forward
API independent Dataflow
Graph representation
Batch Optimizer Graph Builder](https://image.slidesharecdn.com/chicagomeetup-flinkarch-151030024628-lva1-app6891/85/Chicago-Flink-Meetup-Flink-s-streaming-architecture-23-320.jpg)

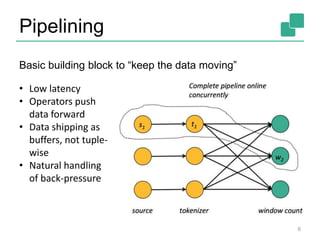
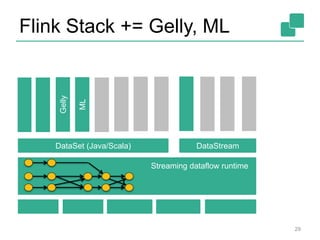
![FlinkML: Machine Learning
API for ML pipelines inspired by scikit-learn
Collection of packaged algorithms
• SVM, Multiple Linear Regression, Optimization, ALS, ...
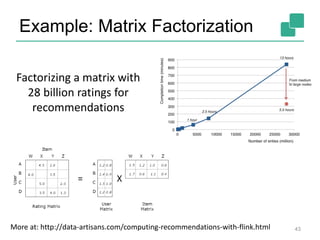
27
val trainingData: DataSet[LabeledVector] = ...
val testingData: DataSet[Vector] = ...
val scaler = StandardScaler()
val polyFeatures = PolynomialFeatures().setDegree(3)
val mlr = MultipleLinearRegression()
val pipeline = scaler.chainTransformer(polyFeatures).chainPredictor(mlr)
pipeline.fit(trainingData)
val predictions: DataSet[LabeledVector] = pipeline.predict(testingData)](https://image.slidesharecdn.com/chicagomeetup-flinkarch-151030024628-lva1-app6891/85/Chicago-Flink-Meetup-Flink-s-streaming-architecture-27-320.jpg)

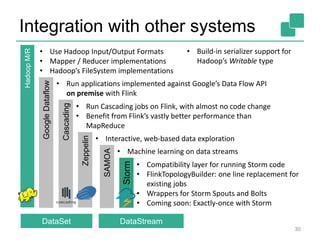






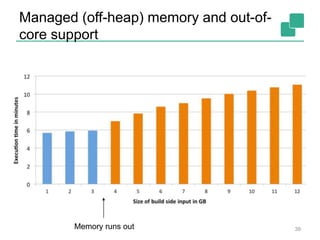
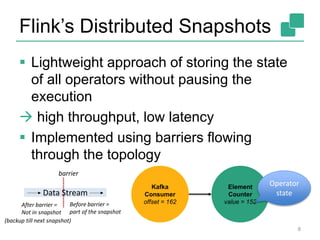
![Cost-based Optimizer
40
DataSource
orders.tbl
Filter
Map DataSource
lineitem.tbl
Join
Hybrid Hash
buildHT probe
broadcast forward
Combine
GroupRed
sort
DataSource
orders.tbl
Filter
Map DataSource
lineitem.tbl
Join
Hybrid Hash
buildHT probe
hash-part [0] hash-part [0]
hash-part [0,1]
GroupRed
sort
forward
Best plan
depends on
relative sizes
of input files](https://image.slidesharecdn.com/chicagomeetup-flinkarch-151030024628-lva1-app6891/85/Chicago-Flink-Meetup-Flink-s-streaming-architecture-40-320.jpg)
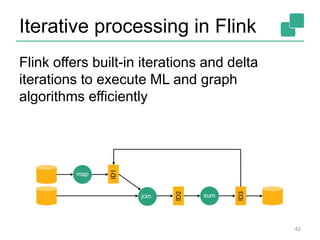
![41
case class Path (from: Long, to:
Long)
val tc = edges.iterate(10) {
paths: DataSet[Path] =>
val next = paths
.join(edges)
.where("to")
.equalTo("from") {
(path, edge) =>
Path(path.from, edge.to)
}
.union(paths)
.distinct()
next
}
Optimizer
Type extraction
stack
Task
scheduling
Dataflow
metadata
Pre-flight (Client)
JobManager
TaskManagers
Data
Source
orders.tbl
Filter
Map
DataSourc
e
lineitem.tbl
Join
Hybrid Hash
build
HT
probe
hash-part [0] hash-part [0]
GroupRed
sort
forward
Program
Dataflow
Graph
deploy
operators
track
intermediate
results
LocalCluster:YARN,Standalone](https://image.slidesharecdn.com/chicagomeetup-flinkarch-151030024628-lva1-app6891/85/Chicago-Flink-Meetup-Flink-s-streaming-architecture-41-320.jpg)

This document summarizes the architecture of Apache Flink's streaming runtime. Flink is a stream processor that embraces the streaming nature of data with low latency, high throughput, and exactly-once guarantees. It achieves this through pipelining to keep data moving efficiently and distributed snapshots for fault tolerance. Flink also supports batch processing as a special case of streaming by running bounded streams as a single global window.











































































































